- The paper introduces GraD, a graph-aware distillation framework that jointly optimizes a GNN teacher and a graph-free LM student to enhance node classification.
- It employs a shared encoding function for the teacher-student model, efficiently integrating textual and structural information from unlabeled nodes.
- Empirical results over eight benchmarks demonstrate superior scalability and instantaneous inference compared to conventional GNN and LM approaches.
Graph-Aware Distillation on Textual Graphs: A Detailed Assessment
Introduction
The paper "Train Your Own GNN Teacher: Graph-Aware Distillation on Textual Graphs" (2304.10668) addresses the challenge of learning node representations on textual graphs using Graph Neural Networks (GNNs) combined with LLMs (LMs). These models achieve state-of-the-art performance for node classification tasks. The primary innovation introduced is the Graph-Aware Distillation (GraD) framework, which encodes graph structures into an LM for faster and more efficient inference without reliance on graph structures during deployment. This approach is particularly significant due to the scalability issues present when deploying GNNs combined with LMs directly.
GraD's strategy involves jointly optimizing a GNN teacher and a graph-free student over the nodes of the graph via a shared LM. This process enables the graph-free student to exploit graph information encoded by the GNN teacher, while simultaneously allowing the GNN teacher to leverage textual information from unlabeled nodes. This mutual learning system yields enhanced performance for both models, showcasing superior results in node classification tasks across various scenarios, including transductive and inductive settings.
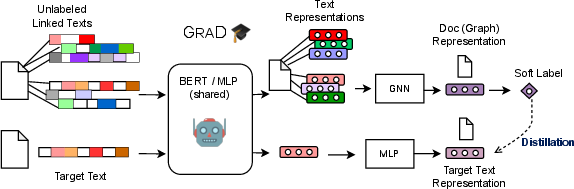
Figure 1: GraD framework. GraD captures textual information among unlabeled linked texts by allowing the teacher GNN and the graph-free student to jointly update the shared text encoding function.
Background
Graph Neural Networks have demonstrated efficacy in tasks across different domains such as social network analysis, and recommendation systems, among others. The core principle involves learning node representations via neighborhood aggregation schemes that consider both node features and graph structures. In textual graphs, text-based information is embedded within nodes, with methods ranging from bag-of-words to advanced pre-trained LMs like BERT used for generating numerical features from raw text data.
The integration of LMs with GNNs poses scalability challenges due to high computational costs, particularly when transforming raw texts on-the-fly during inference. This new framework seeks to address these issues by developing a model where a graph-free LM can perform inference without the graph structure, increasing efficiency significantly.
Graph-Aware Knowledge Distillation
The GraD framework proposes a novel approach to knowledge distillation within textual graphs by jointly optimizing a GNN with a graph-free LM student. Unlike conventional distillation methods, GraD allows concurrent optimization tasks for both teacher and student, ensuring broad and effective usage of node interactions encoded in the graph structure.
GraD uses a shared encoding function for both models, enabling dynamic interplay that fosters graph-aware text representations beneficial for both models. This framework optimizes a multi-task learning scheme where node information encoded by the GNN teacher is used for training a graph-free model, thereby reinforcing the representation capability of the LM.
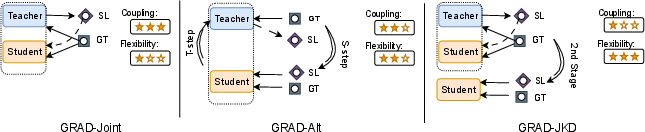
Figure 2: GraD strategies for coupling the GNN teacher and the graph-free student. SL denotes soft-label and GT denotes ground-truth label.
Experimental Results
Empirical evaluations over eight node classification benchmarks demonstrate that GraD consistently outperforms conventional knowledge distillation and models that deploy GNN and LM individually. The comprehensive analysis includes transductive and inductive settings across various datasets, revealing GraD's ability to effectively leverage graph structures during the training process for improved accuracy.
Notably, GraD achieves substantial improvement over counterparts in terms of scalability and efficiency, managing to provide instantaneous predictions equivalent to GNN models but with significantly reduced computational overhead during inference.
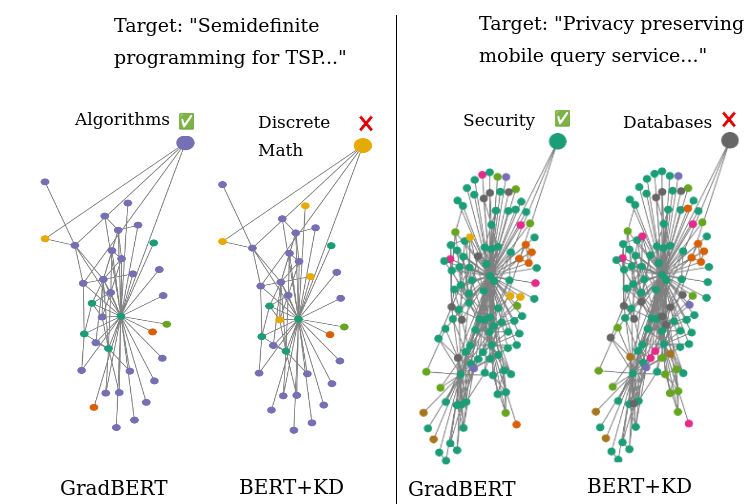
Figure 3: Qualitative examples in which GraDBERT outperforms conventional KD. Colors denote node labels. GraD leverages label-aware neighbor information to infer the correct label for the target text.
Conclusion
The paper introduces an advanced framework for transforming textual graph node representations by fostering mutual learning between GNN teachers and LM students. By capitalizing on structured data during training and decoupling dependencies from graph structures during inference, GraD sets a precedent for efficient, scalable node classification tasks. The methodology offers promising avenues for future research, potentially extending to featureless graphs or dynamic graphs with real-time updates. Although dependent on informative node features, this approach exemplifies a balance between compute efficiency and accuracy, making it adaptable to practical applications where rapid inference is critical.
Overall, the presented GraD framework holds profound implications for future AI developments, particularly for tasks demanding real-time interaction and learning in graph-based environments.
