- The paper introduces the GDL4LLM framework that translates graph structures into a language corpus for efficient node classification.
- The paper leverages a two-stage approach with pre-training and fine-tuning to integrate graph structural information into LLMs.
- The paper demonstrates superior benchmark performance by modeling complex graph patterns with fewer tokens and reduced computational load.
Graph-Defined Language Learning with LLMs
The research paper "Each Graph is a New Language: Graph Learning with LLMs" explores the innovative framework of using LLMs to model graph structures as a unique language, focusing primarily on node classification tasks. This framework, referred to as Graph-Defined Language for LLM (GDL4LLM), aims to overcome the limitations traditional methods face in using LLMs for graph structural modeling.
Introduction to GDL4LLM
The approach of modeling graph structures using Graph Neural Networks (GNNs) has been instrumental in capturing node-level information via message-passing mechanisms. However, leveraging LLMs for similar tasks often results in verbose graph descriptions which do not efficiently encapsulate high-order structures. To mitigate this inadequacy, the paper introduces GDL4LLM, which translates graph structures into a graph language corpus. This transformation enables LLMs to understand graph structures through pre-training in a manner similar to acquiring language proficiency.
Graph Language Modeling
GDL4LLM conceptualizes graphs as languages in which nodes are treated as tokens and paths as sentences. This approach enables LLMs to model graph structures effectively by pre-training on a graph language corpus composed of these graph sentences. The corpus is generated through graph traversal methods such as random walks, ensuring that both local and global graph structural information is captured efficiently.
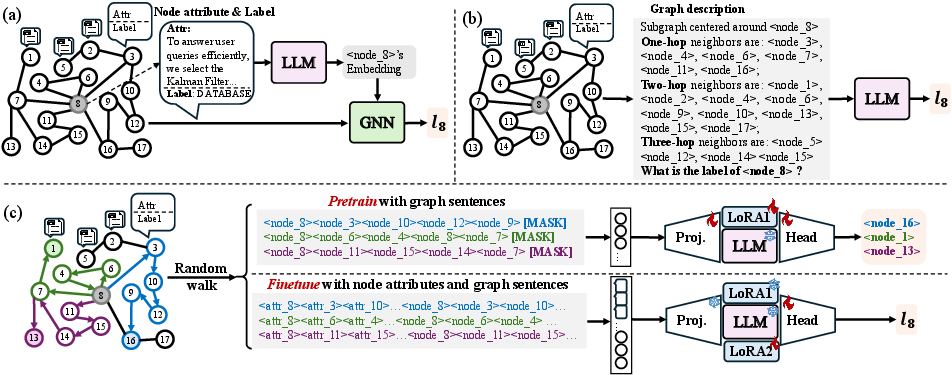
Figure 1: The figure demonstrates a comparison between mainstream methods and GDL4LLM for node-classification tasks.
Methodology
The GDL4LLM framework comprises two major stages: pre-training and fine-tuning. During the pre-training phase, LLMs learn to identify graph tokens and predict subsequent tokens using graph-based language modeling objectives. This process integrates graph structural information into the LLM, allowing for concise and efficient representation of graph structure in the fine-tuning stage.
Graph Language Pre-Training
The innovation in pre-training involves embedding graph tokens into LLMs using a learnable linear projector. This projector maps the initial graph token embeddings to align with structural information. Pre-training optimizes the likelihood of correct token occurrence within graph sentences, facilitating LLMs' understanding of the graph's statistical patterns.
Fine-Tuning with Graph Structures
Fine-tuning refines the pre-trained LLMs to enable node classification using graph language. By sampling multiple graph sentences centered around target nodes, LLMs learn to incorporate these sentences into a small corpus that conveys various orders of structural information. This strategy combines the statistical graph language comprehension of LLMs with textual attributes to bolster node classification tasks.
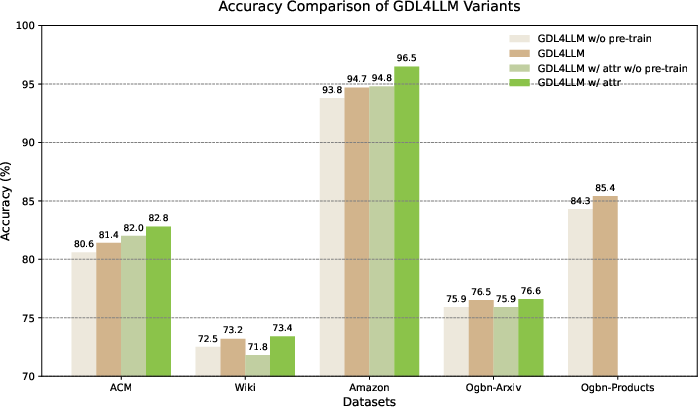
Figure 2: Accuracy comparison of different GDL4LLM variants on the test set across three datasets.
Results and Evaluation
The research demonstrates GDL4LLM's superior performance across several benchmarks against conventional text-attributed graph learning frameworks. It achieves higher accuracy in node classification by effectively modeling more complex graph structures using fewer tokens. The pre-training stage, akin to language pre-training for LLMs, proved advantageous, enhancing the model's capabilities in graph comprehension.
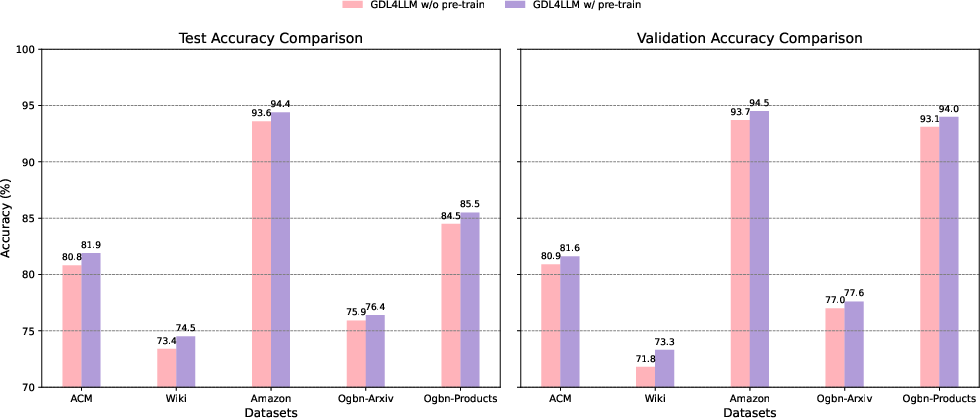
Figure 3: Replacement of the backbone with Llama3 on the validation and test sets across three datasets.
The framework's efficiency is evident from the reduced computational load and faster performance seen across a range of datasets, outperforming both description-based and attribute embedding-based models.
Implications and Future Directions
GDL4LLM represents a paradigm shift in applying LLMs to graph-based tasks, suggesting new pathways for integrating these models into broader applications in AI. Future developments may focus on extending this idea to more graph-based tasks like link prediction or clustering, and optimizing memory usage through advanced dynamic memory systems.
Conclusion
The GDL4LLM framework successfully amalgamates graph structure understanding with LLMs' language processing capabilities to advance node classification tasks. This innovative approach promotes the concise and effective application of LLMs across complex graph structures, paving the way for future exploration in the integration of LLMs with graph computations.
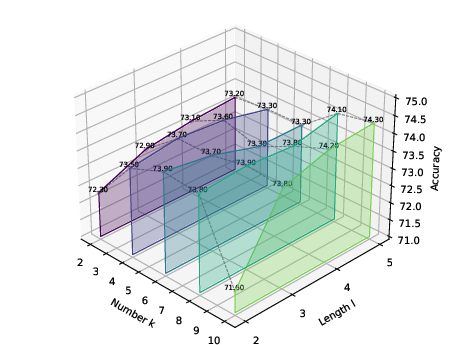
Figure 4: Visualizations of the impact of graph sentence length l and graph sentence length k on performance.