GraphText: Graph Reasoning in Text Space
Abstract: LLMs have gained the ability to assimilate human knowledge and facilitate natural language interactions with both humans and other LLMs. However, despite their impressive achievements, LLMs have not made significant advancements in the realm of graph machine learning. This limitation arises because graphs encapsulate distinct relational data, making it challenging to transform them into natural language that LLMs understand. In this paper, we bridge this gap with a novel framework, GraphText, that translates graphs into natural language. GraphText derives a graph-syntax tree for each graph that encapsulates both the node attributes and inter-node relationships. Traversal of the tree yields a graph text sequence, which is then processed by an LLM to treat graph tasks as text generation tasks. Notably, GraphText offers multiple advantages. It introduces training-free graph reasoning: even without training on graph data, GraphText with ChatGPT can achieve on par with, or even surpassing, the performance of supervised-trained graph neural networks through in-context learning (ICL). Furthermore, GraphText paves the way for interactive graph reasoning, allowing both humans and LLMs to communicate with the model seamlessly using natural language. These capabilities underscore the vast, yet-to-be-explored potential of LLMs in the domain of graph machine learning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “GraphText: Graph Reasoning in Text Space”
What is this paper about?
This paper introduces a new way to help LLMs, like ChatGPT, understand and solve problems on graphs. A graph is like a network: think of dots (called nodes) connected by lines (called edges), such as people in a social network or web pages connected by links. Normally, special models called Graph Neural Networks (GNNs) are used for these tasks. But the authors show how to “translate” graphs into natural language so regular LLMs can read them like a story and make decisions—often without any extra training.
What questions are the researchers asking?
The authors focus on a few simple questions:
- Can we turn graph data into sentences so LLMs can understand it?
- If we do that, can an LLM solve graph tasks (like guessing a node’s category) without special training, just by reading examples?
- Can this method let humans and AIs talk about graphs naturally, improving the model’s reasoning through feedback or examples?
- Will this work across different kinds of graphs, not just one specific dataset?
How does their method work?
Their method is called GraphText. It uses a “graph-syntax tree” to convert a graph into text that an LLM can read.
Here’s the idea in everyday terms:
- Imagine you want to guess the “topic” of one paper (a node) in a network of papers that cite each other (edges).
- Around the paper you care about, you collect a small neighborhood: the paper itself, its direct neighbors (1 hop away), and maybe their neighbors (2 hops away).
- For each paper, you gather information you can say in words: its label (if known), its features (sometimes real numbers that they turn into categories like “cluster 3” using a simple grouping method), or even real text like a title or abstract if available.
- You also describe relationships in words: for example, “center-node,” “1st-hop neighbor,” “2nd-hop neighbor,” or “most important neighbors” (based on a measure like Personalized PageRank, which is like saying “friends who influence you the most”).
Then they build a tree of this information:
- The tree has a clear hierarchy (like an outline). Internal parts of the tree say things like “feature” or “label,” and “1st-hop” or “2nd-hop.” The leaves are the actual pieces of text (like “label: Machine Learning”).
- If you “walk” through this tree in order, you get a well-structured paragraph (a “graph prompt”) the LLM can read.
- Finally, they ask the LLM a simple multiple-choice question, like “What is the topic of the center paper?” The LLM picks from options, and that becomes the prediction.
A few key tricks:
- Turning numbers into words: If a node has continuous features (like vectors), they group them into buckets (like sorting marbles by color) so they can be written as short text labels.
- Adding helpful patterns from GNNs: They can include extra information known to help on graphs (called “inductive bias”), like features that are averaged over neighbors (feature propagation) or connections based on similarity, to make the text more informative.
- In-context learning: They show the LLM a few solved examples first, so it learns the pattern just from reading them—no fine-tuning needed.
What did they find, and why is it important?
Here are the main findings in simple terms:
- Training-free success: Even without training on graph data, GraphText + ChatGPT can match or sometimes beat standard GNNs on node classification tasks in several datasets (like Cora, Citeseer, and some web graphs). This is especially true when there are few labeled examples or when neighbors aren’t very similar to each other (a tricky case for GNNs).
- Better with smart structure: The way the text is organized matters a lot. A clear, hierarchical “graph-syntax tree” beats a flat list or a jumbled set. Including helpful relationships (like “most important neighbors” using PageRank) and “propagated” information boosts accuracy.
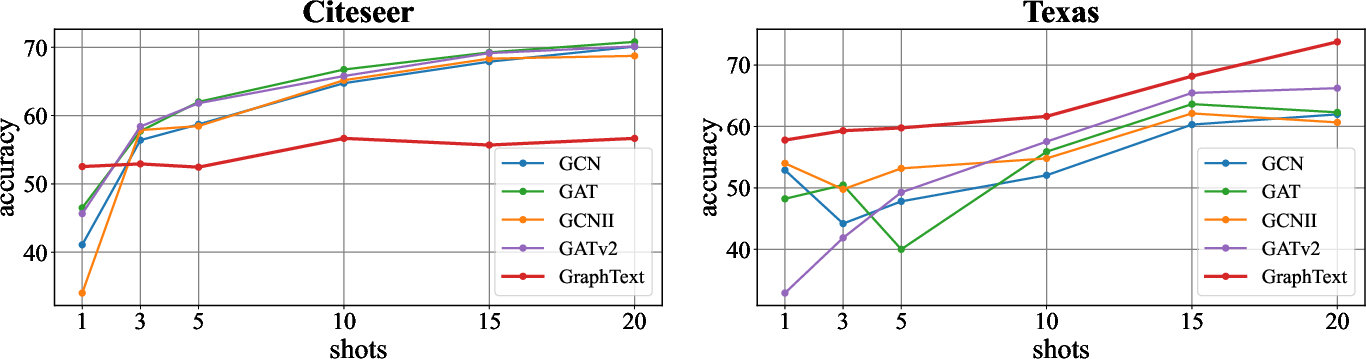
- Few-shot learning works: Giving the LLM a handful of examples improves performance steadily (1, 3, 5, 10, 15, 20 examples).
- Interactive reasoning: Because everything is in natural language, you can talk to the model. If it leans too much on the center node’s label, you can nudge it with feedback like “Pay more attention to the top PageRank neighbor,” and its accuracy goes up. In one case, GPT-4 reached 100% on a target after human feedback.
- Works with open-source models too: When they fine-tuned a smaller open-source LLM (Llama-2-7B) with efficient methods (LoRA), it got close to GNN performance on text-rich graphs. This suggests you don’t always need giant, closed-source models.
Why this matters:
- It shows LLMs are not just for language—they can perform graph reasoning if you describe the graph clearly in words.
- It reduces the need to train a new GNN for every new graph, saving time and computing power.
- It makes graph predictions explainable and adjustable, because the model “thinks” in text you can read and discuss.
What could this change in the future?
This approach opens up new possibilities:
- Easier workflows: Teams can apply one LLM across many different graphs by just changing the text prompts, instead of retraining a separate model each time.
- Explainable AI for graphs: Since the model reasons in language, humans can understand and improve its logic through examples and feedback.
- Broader applications: Social networks, recommendation systems, biology (molecules as graphs), transportation networks, and knowledge graphs could benefit.
- Responsible use: The authors note good impacts (less computing and carbon cost) but also warn about potential misuse (like in harmful recommendation systems), so ethics matter.
In short, GraphText shows that by carefully turning graphs into well-structured text, LLMs can become strong, flexible, and conversational problem-solvers for graph tasks—often without extra training.
Collections
Sign up for free to add this paper to one or more collections.