A Graph Talks, But Who's Listening? Rethinking Evaluations for Graph-Language Models
Abstract: Developments in Graph-LLMs (GLMs) aim to integrate the structural reasoning capabilities of Graph Neural Networks (GNNs) with the semantic understanding of LLMs. However, we demonstrate that current evaluation benchmarks for GLMs, which are primarily repurposed node-level classification datasets, are insufficient to assess multimodal reasoning. Our analysis reveals that strong performance on these benchmarks is achievable using unimodal information alone, suggesting that they do not necessitate graph-language integration. To address this evaluation gap, we introduce the CLEGR(Compositional Language-Graph Reasoning) benchmark, designed to evaluate multimodal reasoning at various complexity levels. Our benchmark employs a synthetic graph generation pipeline paired with questions that require joint reasoning over structure and textual semantics. We perform a thorough evaluation of representative GLM architectures and find that soft-prompted LLM baselines perform on par with GLMs that incorporate a full GNN backbone. This result calls into question the architectural necessity of incorporating graph structure into LLMs. We further show that GLMs exhibit significant performance degradation in tasks that require structural reasoning. These findings highlight limitations in the graph reasoning capabilities of current GLMs and provide a foundation for advancing the community toward explicit multimodal reasoning involving graph structure and language.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of the paper
What is this paper about?
This paper looks at a new kind of AI model called a Graph-LLM (GLM). A GLM tries to combine:
- the structure-reading skills of Graph Neural Networks (GNNs), which work on graphs (networks of dots and lines, like friends on a social network), and
- the language understanding of LLMs, like the ones that answer questions in plain text.
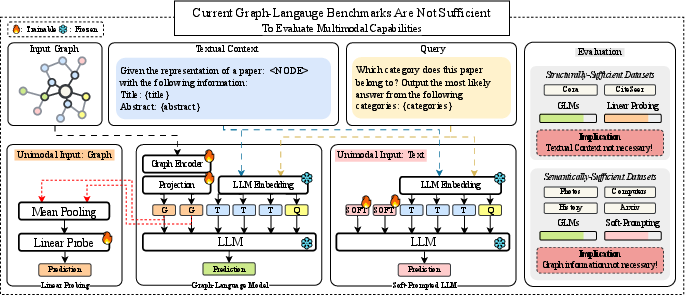
The authors argue that today’s tests for GLMs are not good enough. Many current benchmarks mainly reuse “node classification” datasets (classifying each dot/node in a graph). The paper shows that models can score highly on these tests without truly combining graph structure and language—meaning the tests don’t really check multimodal (graph + text) reasoning. To fix this, they introduce a new benchmark called CLeGR that is designed to require both graph structure and text understanding at the same time.
The big questions the authors asked
- Are the popular test datasets for GLMs actually measuring combined graph-and-language reasoning, or can models pass using just one type of information?
- Do GLMs really need a graph encoder (the GNN part), or can a simpler language-only setup do just as well?
- If we build a better benchmark that forces models to use both structure and language, do GLMs finally outperform language-only setups?
- Do GLMs generalize better to new topics and larger graphs compared to language-only methods?
How did they study it?
First, some quick translations of technical terms:
- Graph: A set of nodes (dots) connected by edges (lines). Think of subway stations (nodes) connected by subway lines (edges), or web pages connected by links.
- Text-Attributed Graph (TAG): Each node or edge has some text attached to it (like a station’s name, description, or properties).
- GLM (Graph-LLM): An LLM plus a graph encoder, stitched together so the LLM “listens” to the graph.
- Soft prompting: Instead of adding a full graph encoder, you add a small trainable set of hint tokens to the LLM—like giving it a short, learnable “sticky note” that helps it do the task, without feeding it the graph structure.
- Linear probing: Freeze a trained model’s internal representations and train a tiny, simple classifier on top. If this simple classifier does very well, it means most useful information was already present in the frozen representations.
What they did:
- They tested several GLMs and strong unimodal baselines on popular TAG datasets (like Cora, CiteSeer, Amazon Computers/Photo, History, Arxiv).
- Graph-only models (GNNs) use only the graph.
- Language-only models are LLMs with soft prompts (no graph).
- GLMs combine both.
- They checked whether good results come from one modality alone (just text or just graph) instead of both together.
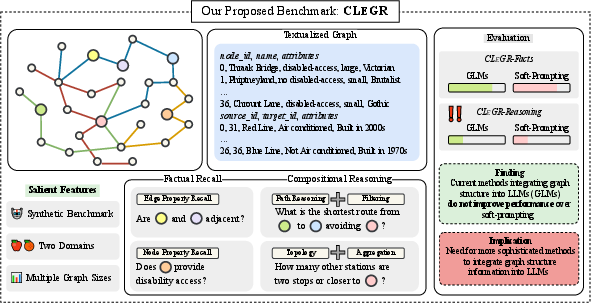
- They created a new benchmark called CLeGR (Compositional Language-Graph Reasoning). It uses synthetic (made-up) subway networks so the model can’t rely on memorized facts from the internet. CLeGR has two parts:
- CLeGR-Facts: simple questions that just need looking up node or edge properties (like “What music is played at Station X?”).
- CLeGR-Reasoning: tougher questions that require combining the graph structure with text, often over multiple steps (like “What is the shortest path from Station A to B using only air-conditioned lines?”). It covers:
- Filtering (choose items with certain properties),
- Aggregation (count/summarize),
- Path reasoning (find routes),
- Topology (understand how the network is connected).
- They also tested whether GLMs transfer better to a new domain (computer networks) and whether they handle larger graphs better.
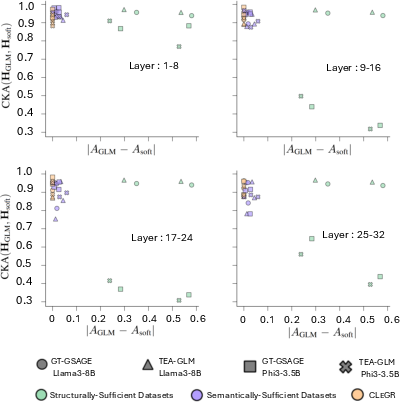
- They analyzed model internals using a technique called CKA (Centered Kernel Alignment) to see how similar the learned representations are between GLMs and soft-prompted LLMs.
What did they find, and why is it important?
Here are the key results:
- Many current benchmarks are “one-sided.”
- Some datasets are semantically sufficient: the text attached to nodes is enough to solve the task. Here, language-only models (just LLMs with soft prompts) did almost as well as GLMs. That means the graph part wasn’t really needed.
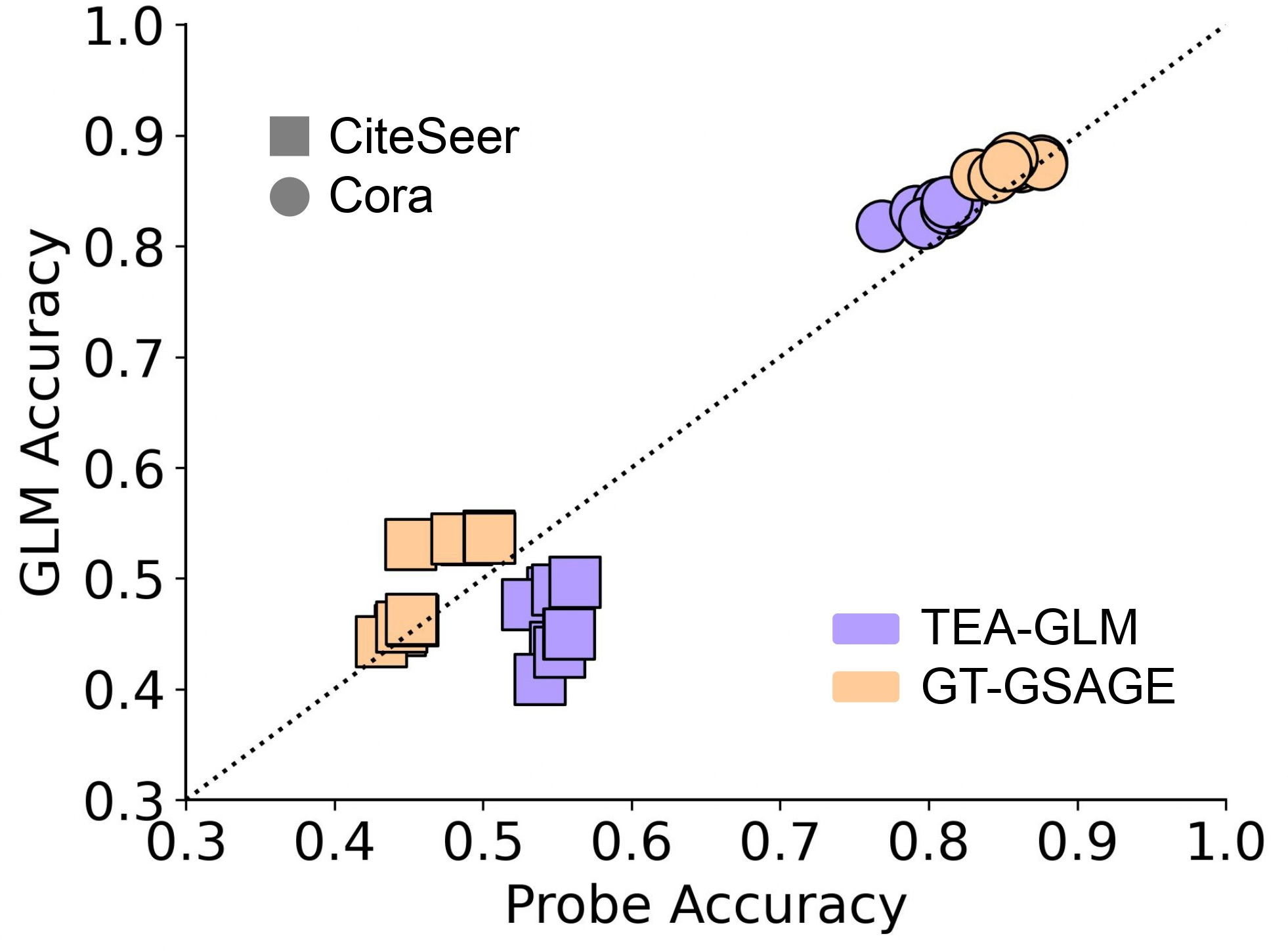
- Other datasets are structurally sufficient: the graph structure alone is enough. Here, graph-only models did great, and language-only models did poorly. The GLM’s gains mostly came from the graph encoder, not from combining graph + language.
- On structure-heavy datasets, the LLM part acts like a fancy decoder head.
- Using linear probing (a simple classifier on top of frozen graph-encoder outputs) gave almost the same accuracy as the full GLM. This suggests the graph encoder already captured everything needed, and the LLM wasn’t adding real reasoning over text.
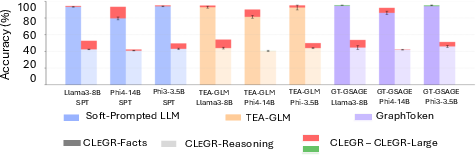
- On the new CLeGR benchmark:
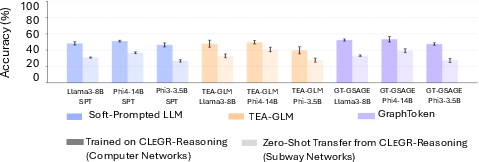
- Models easily solved the fact lookup tasks (CLeGR-Facts).
- But on the harder reasoning tasks (CLeGR-Reasoning), GLMs did not beat simple soft-prompted LLMs. Even a retrieval-based GLM (which tries to pull out the most relevant subgraph) didn’t help and sometimes performed worse—likely because it retrieved the wrong pieces or lost needed context.
- No clear advantage in zero-shot transfer or bigger graphs.
- When switching from the subway domain to a computer-network domain, GLMs still didn’t outperform soft-prompted LLMs.
- When the graphs got larger, both GLMs and soft-prompted LLMs got worse at similar rates. GLMs didn’t show a scaling advantage.
- Internal representations were similar when performance was similar.
- CKA analysis showed that when GLMs and soft-prompted LLMs performed about the same, their internal representations were also very similar—suggesting they were solving the tasks in similar (language-driven) ways rather than through true graph+language integration.
Why this matters:
- If benchmarks don’t require models to actually combine graph structure and language, we’ll think our models are strong when they’re not. That can slow real progress.
- CLeGR provides a harder, more honest test that forces models to use both modalities.
What does this mean for the future?
- We need better tests and better designs. The paper shows that current GLMs often don’t truly mix graph structure with language—they lean on one side. New benchmarks like CLeGR help reveal what models can and can’t do.
- Architecture rethink: If soft-prompted LLMs can match or beat GLMs on many tasks, maybe we need new ways of feeding graphs to LLMs or tighter integration than current methods provide.
- Practical takeaway: If your task is mostly about reading text properties, you might not need a full GLM; a language-first method could be enough. If your task is mostly structural, a strong GNN might suffice. But if you need both, today’s GLMs may still fall short—so research should focus on truly multimodal reasoning.
- Community resources: The authors release CLeGR (dataset and code) so others can test their models fairly and push the field forward.
Quick glossary (for clarity)
- Graph: Dots (nodes) connected by lines (edges); like a subway map or social network.
- GNN (Graph Neural Network): A model that learns from graph structure.
- LLM: A model that understands and generates text.
- GLM (Graph-LLM): An LLM that also takes graph inputs.
- Soft prompting: Small learned hint tokens added to the LLM input, without using a graph encoder.
- Benchmark: A shared test used to compare different models.
- Node classification: Labeling each node in a graph with a category.
In short: The paper argues that many current tests don’t truly measure graph+language reasoning. It introduces a stronger benchmark (CLeGR) and shows that current GLMs don’t yet outperform simpler language-only setups when real multimodal reasoning is required. This calls for better evaluations and better models that genuinely combine both worlds.
Collections
Sign up for free to add this paper to one or more collections.

