- The paper introduces a graph-based framework to map the chain-of-thought in RLMs, providing a new perspective on reasoning processes.
- It quantifies reasoning behavior using metrics like exploration density, branching, and convergence ratios to correlate graph structure with performance.
- The study reveals that zero-shot prompting leads to richer, more flexible graph structures compared to few-shot approaches.
Graph-Based Analysis of Reasoning in LLMs
Introduction
The paper "Mapping the Minds of LLMs: A Graph-Based Analysis of Reasoning LLM" (2505.13890) explores the reasoning capabilities of Reasoning LLMs (RLMs) by introducing a novel graph-based framework. This research is primarily motivated by the need to understand the counterintuitive and unstable behaviors exhibited by RLMs, particularly under various prompting regimes such as zero-shot and few-shot settings. The authors propose using graph structures to quantify and analyze the reasoning processes of these models, providing insights that extend beyond traditional accuracy metrics.
Framework Overview
The proposed framework constructs reasoning graphs from the chain-of-thought (CoT) outputs of RLMs. This approach involves clustering verbose CoT sequences into semantically coherent reasoning steps, which are then used as nodes in a directed graph that reveals contextual and logical dependencies among steps. The graph-based representation enhances human readability, systematic interpretability, and allows the calculation of quantifiable graph metrics for analysis (Figure 1).
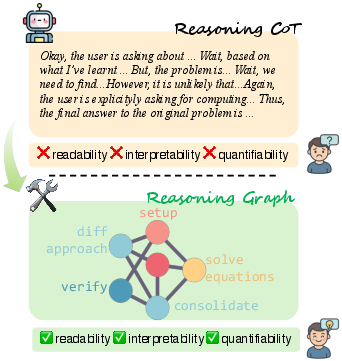
Figure 1: A conceptual overview of our framework for modeling the long reasoning CoT with a graph structure.
Graph Construction from CoT Tokens
The methodology for constructing reasoning graphs involves three main steps: clustering raw tokens into reasoning steps, detecting semantic relationships between these steps to form edges, and finally constructing the reasoning graph structure. Initially, token sequences are divided into reasoning units using delimiters, followed by a logical clustering process that organizes these units into semantically meaningful steps. Semantic relationships between steps are then detected to construct a graph that represents the reasoning process (Figure 2).

Figure 2: Our pipeline for building the graph structure from reasoning LLMs' output.
Graph-Based Metrics and Cognitive Analysis
The graph-based analysis introduces several metrics to quantify reasoning processes: exploration density, branching ratio, convergence ratio, and linearity. These metrics provide a detailed understanding of the model's reasoning behavior, highlighting how structures differ across different prompting styles. The study reveals that zero-shot prompting leads to richer graph structures compared to few-shot settings, which often impose linear constraints and reduce the model's effective reasoning capacity.
Impact of Prompting Regimes
The paper's analysis of prompting regimes demonstrates that few-shot prompting degrades performance, a counterintuitive outcome given its success with conventional LLMs. The inclusion of examples in prompts, especially verbose ones, can shift the reasoning structure towards linearity, limiting the model's capacity for adaptive reasoning. This is evidenced by significant drops in accuracy with increasing few-shot examples, as demonstrated in Figures 5 and 6.
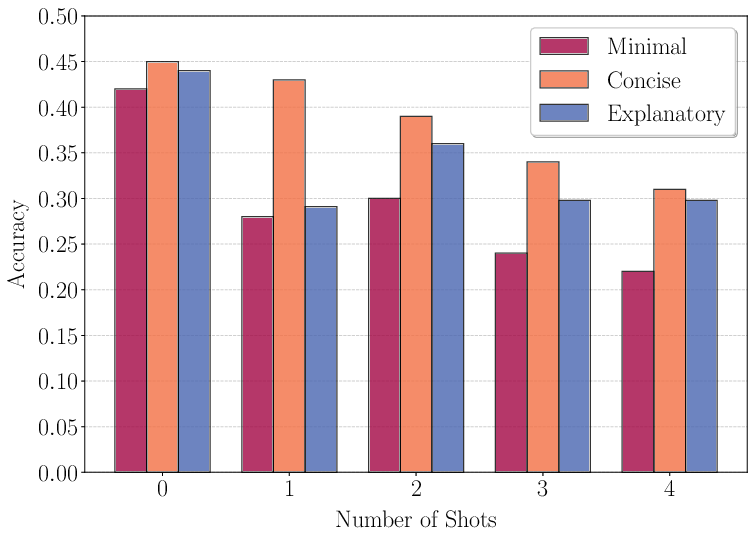
Figure 3: Few-shot prompting accuracy on GPQA-Diamond^
dataset using reasoning Qwen-7B.*
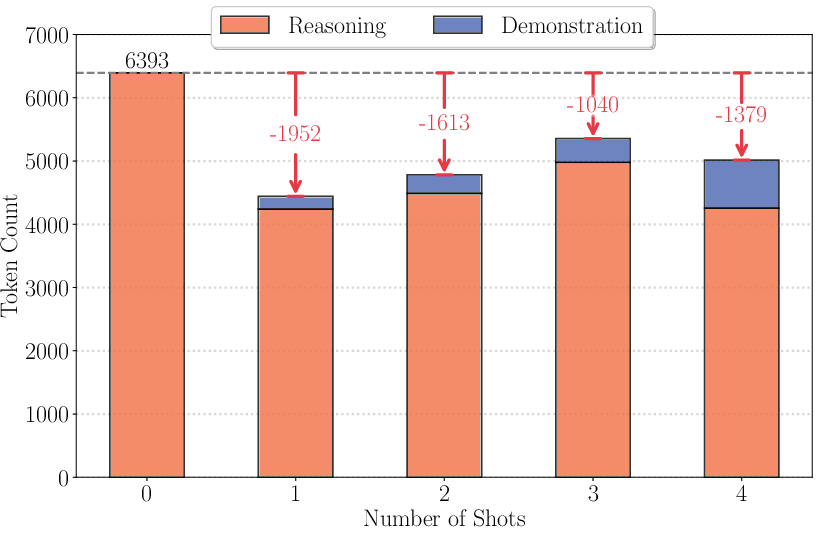
Figure 4: Average number of tokens under different numbers of shots with explanatary few-shot style.
The paper presents an analysis correlating graph structures with reasoning performance across different models and prompting paradigms. It finds consistent patterns where complex reasoning graphs—with higher exploration and convergence—are associated with better performance. This underscores the importance of flexible reasoning structures for effective problem-solving, as showcased in Figure 5.
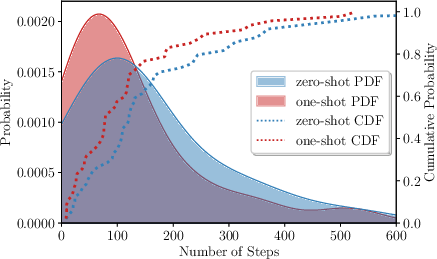
Figure 5: Distribution of reasoning step counts under zero-shot and one-shot prompting.
Implications and Future Research
The findings imply that graph-based approaches provide a deeper, structural-level understanding of RLM behavior, potentially guiding future prompt engineering strategies. By illuminating how different prompting methods influence reasoning structures, this work opens avenues for optimizing prompt design to enhance reasoning performance in RLMs. Future research could extend this framework to other RLM applications, exploring multi-modal and open-domain reasoning tasks.
Conclusion
The study offers an innovative perspective on RLM analysis through graph-based reasoning structures, presenting a framework that could significantly influence how prompt engineering and model behavior are understood in AI research. It marks a step forward in quantifying reasoning quality and enhancing interpretability beyond traditional performance metrics.