- The paper introduces ReJump, a representation capturing LLM reasoning as tree structures, enabling nuanced analysis of multi-step problem-solving.
- It defines specific metrics like exploration-exploitation balance to quantify reasoning processes and compare model performance.
- Experimental evaluations on tasks like MATH-500 and Game of 24 reveal that models with similar accuracy can exhibit distinct reasoning strategies.
ReJump: A Tree-Jump Representation for Analyzing and Improving LLM Reasoning
Introduction
The research introduces ReJump, a novel representation method for analyzing reasoning in Large Reasoning Models (LRMs), which are a subclass of LLMs trained for generating Chain-of-Thought (CoT) reasoning. ReJump addresses how models solve problems by representing reasoning traces as tree structures, encapsulating the complexity of multi-step problem-solving processes typical in tasks like mathematical proofs and logical deductions.
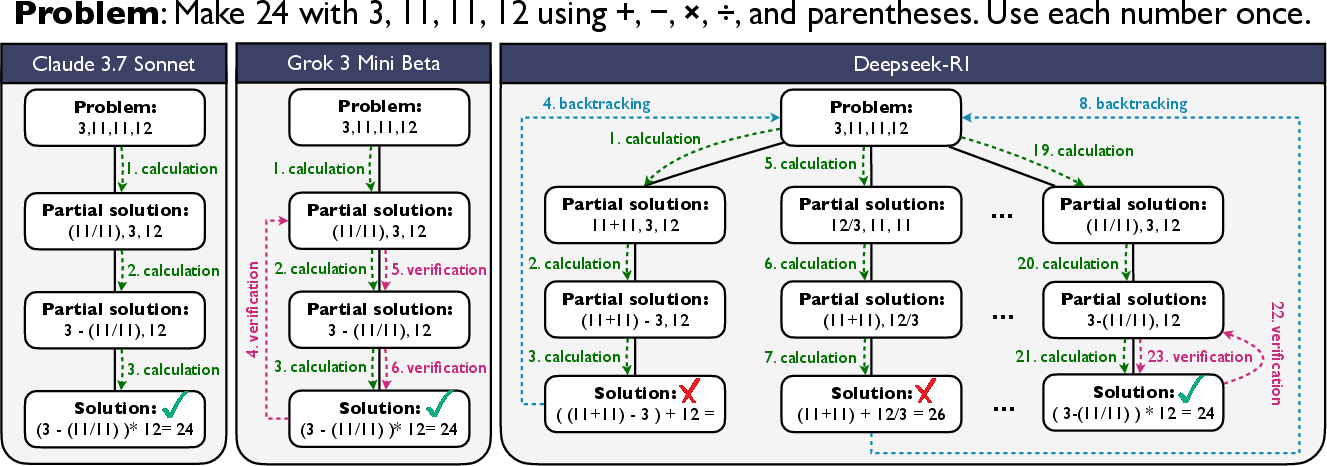
Figure 1: ReJump representations of reasoning traces generated by Claude 3.7 Sonnet, Grok 3 Mini Beta, and DeepSeek-R1 on a Game of 24 problem.
Methodology
ReJump Representation: ReJump captures reasoning by encoding the sequence of visited nodes as a tree, where nodes represent intermediate problem-solving steps, and transitions (termed 'jumps') between nodes indicate actions like calculation, verification, or backtracking. This structure differs from traditional linear CoT by illustrating multiple potential solution paths, thus offering insights into the model's strategic reasoning capabilities.
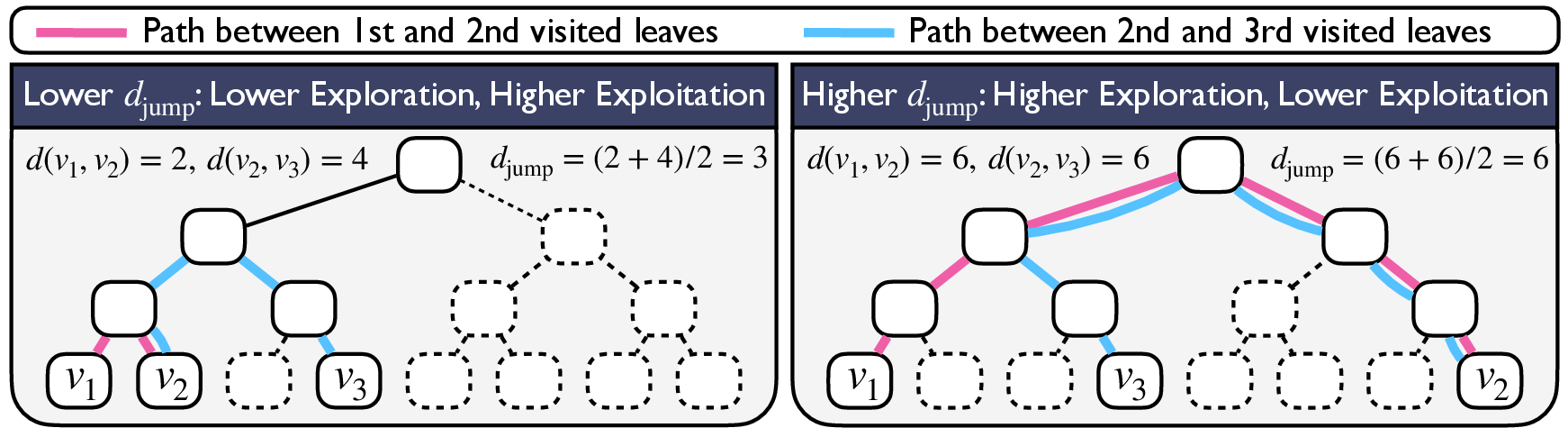
Figure 2: Illustration of how djump quantifies the exploration-exploitation trade-off in model reasoning.
Metrics in ReJump: The study introduces several quantitative metrics for evaluating reasoning, including exploration-exploitation balance (djump), success rate, verification rate, and overthinking rate. Such metrics are designed to evaluate not just the end results but the nuances of the reasoning paths taken by different models.
Experimental Evaluation
The research evaluates several state-of-the-art LRMs, such as DeepSeek-R1 and Grok 3 Mini Beta, on tasks like MATH-500 and the Game of 24. The analysis reveals that models exhibiting similar accuracy may follow distinct reasoning processes. For instance, some models might prioritize verification processes over exploratory steps, impacting their problem-solving efficiency and accuracy in different scenarios.
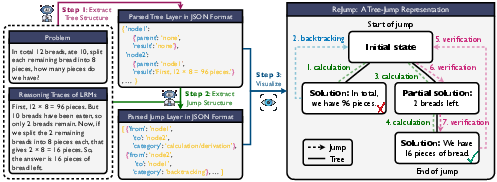
Figure 3: Illustration of how reasoning traces are converted into the ReJump representation for a math word problem.
Comparison to Existing Models
ReJump demonstrates its superiority in distinguishing reasoning patterns by comparing it against existing methods such as direct comparisons of final answer accuracies. The method provides a more nuanced understanding of reasoning behaviors, highlighting differences in how models handle exploration versus exploitation and manage verification tasks.
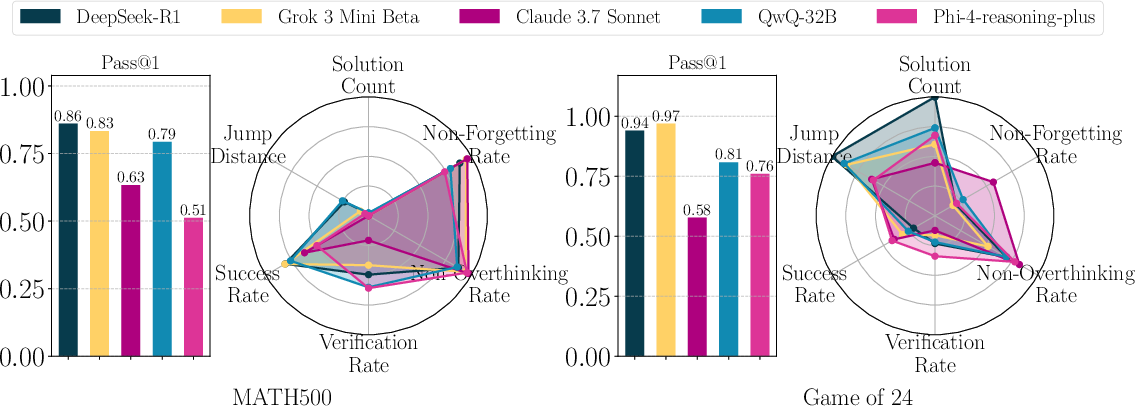
Figure 4: Reasoning performance of various models on MATH-500 and Game of 24. Bar plots show final accuracy, while radar plots depict reasoning metrics.
Implications and Future Directions
ReJump's ability to dissect reasoning strategies enhances the understanding of LLM behaviors and guides improvements in model development, particularly for tasks requiring strategic problem-solving like advanced mathematics or logical deductions. The authors suggest future work might involve integrating ReJump-derived insights into the training processes, potentially using them to refine reinforcement learning strategies or guide prompt design for improved task-specific reasoning.
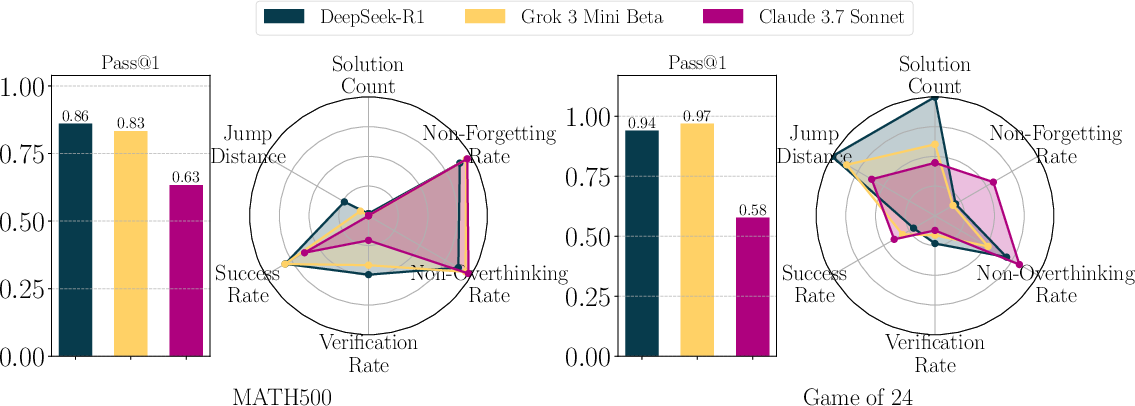
Figure 5: Detailed reasoning performance plots for DeepSeek-R1, Grok 3 Mini Beta, and Claude 3.7 Sonnet, emphasizing the variation in underlying processes despite similar performance metrics.
Conclusion
The introduction of ReJump represents a significant step in analyzing and enhancing the reasoning processes of contemporary LLMs. By articulating the intricacies of reasoning paths, ReJump not only aids in the evaluation of current models but also paves the way for developing LLMs that are more adept at complex reasoning tasks. The framework holds promise for advancing both theoretical understanding and practical application of LLMs in domains demanding high-level cognitive reasoning.