- The paper shows that large reasoning models collapse in performance when task complexity exceeds a critical threshold.
- Methodology involves systematic testing on puzzles like Tower of Hanoi and Checker Jumping, with detailed analysis of intermediate reasoning traces.
- Findings indicate that even with explicit algorithm guidance, models struggle with exact computation and robust symbolic manipulation.
The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models
This paper (2506.06941) investigates the capabilities and limitations of Large Reasoning Models (LRMs) by examining their performance on systematically varied puzzle environments. The study moves beyond traditional benchmarks, which often suffer from data contamination, to analyze both the final answers and the intermediate reasoning traces of LRMs. Through controlled experiments, the authors reveal critical insights into how these models "think," uncovering performance collapses at higher complexities and limitations in exact computation and algorithmic reasoning.
Experimental Setup and Findings
The authors evaluate LRMs, including o3-mini, DeepSeek-R1, and Claude-3.7-Sonnet-Thinking, across four puzzle environments: Tower of Hanoi, Checker Jumping, River Crossing, and Blocks World (Figure 1). These puzzles allow for precise control over compositional complexity while maintaining consistent logical structures. The models' performance is assessed by measuring accuracy and analyzing the reasoning traces, revealing a counterintuitive scaling limit where reasoning effort decreases despite an adequate token budget.
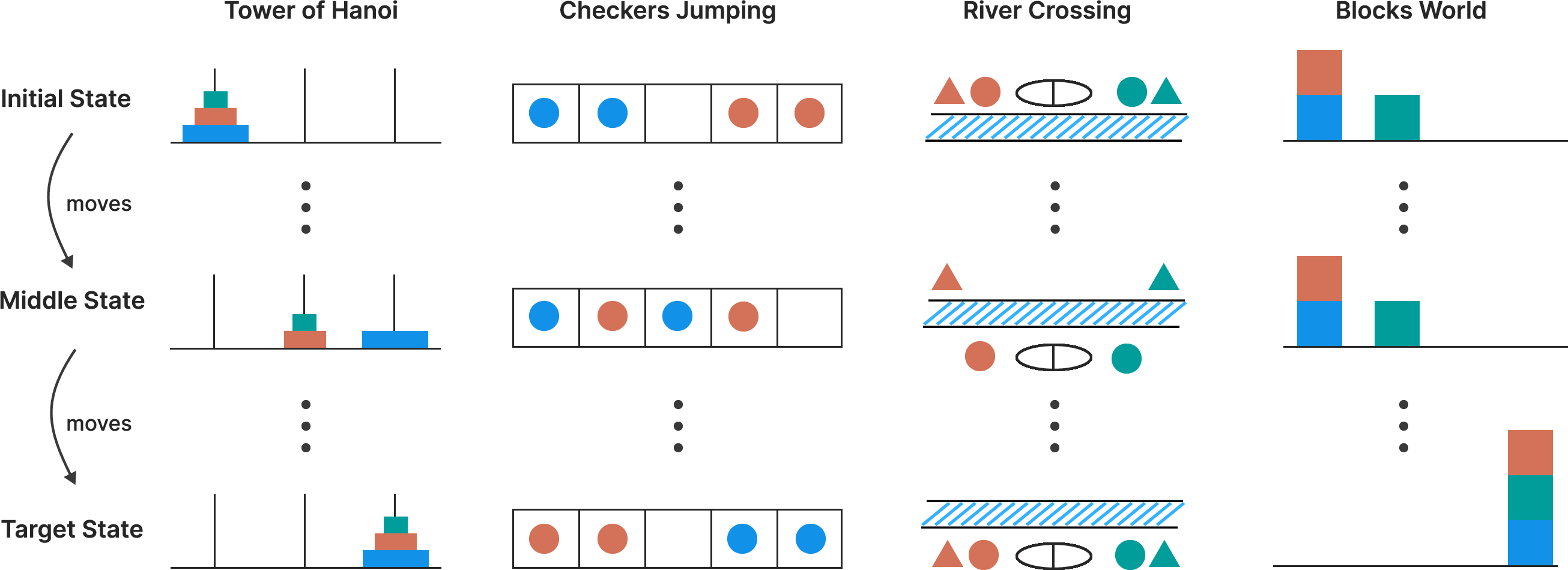
Figure 1: Illustration of the four puzzle environments, showcasing the progression from initial, intermediate, and target states for Tower of Hanoi, Checkers Jumping, River Crossing, and Blocks World.
The study identifies three performance regimes based on problem complexity (Figure 2): (1) low-complexity tasks where standard LLMs outperform LRMs due to greater token efficiency, (2) medium-complexity tasks where the additional thinking in LRMs demonstrates an advantage, and (3) high-complexity tasks where both models experience a complete collapse in performance. A key finding is that LRMs often fail to generalize problem-solving capabilities, with accuracy collapsing to near-zero beyond a certain complexity threshold.
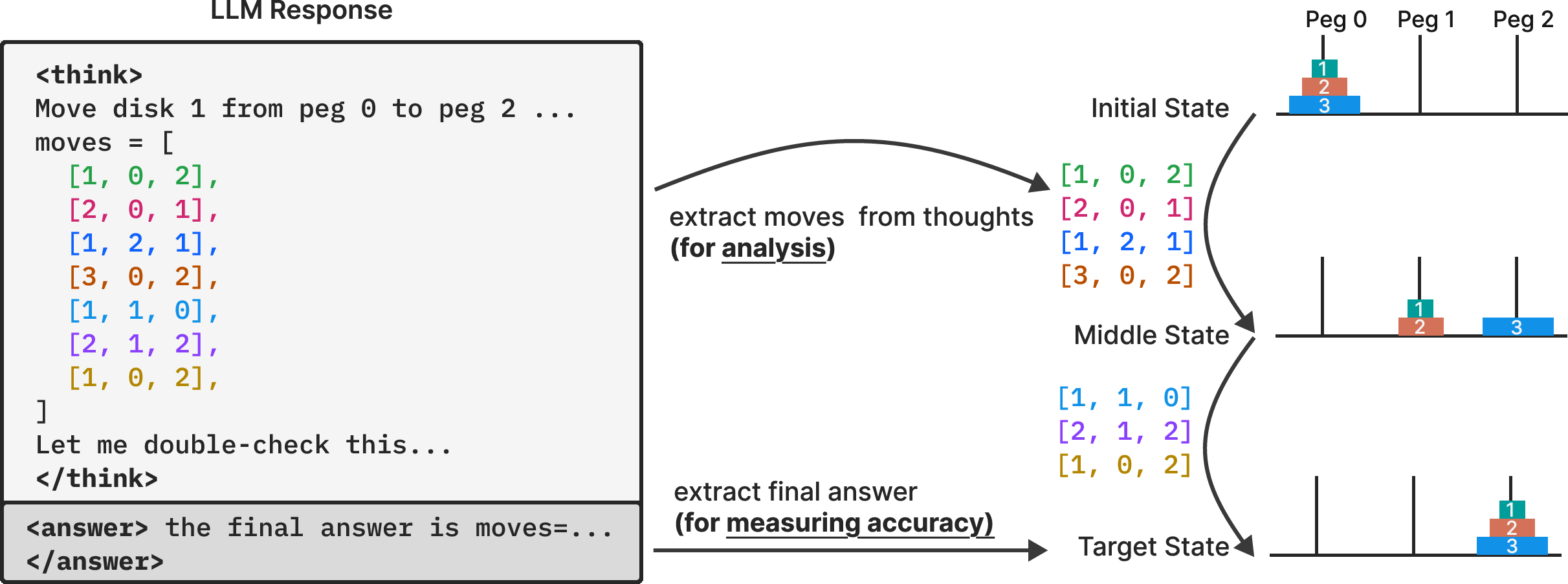
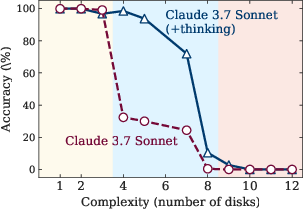
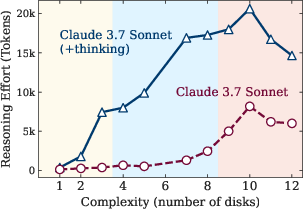
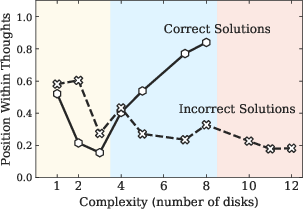
Figure 2: Comparative analysis of model thinking mechanisms, token efficiency, and inefficiencies in reasoning, highlighting the limitations of LRMs.
Analysis of Reasoning Traces
The authors conduct an in-depth analysis of intermediate reasoning traces, revealing complexity-dependent patterns. In simpler problems, LRMs tend to identify correct solutions early but then inefficiently explore incorrect alternatives, an "overthinking" phenomenon. At moderate complexity, correct solutions emerge only after extensive exploration of incorrect paths. Beyond a certain threshold, models fail to find correct solutions and fixate on early incorrect attempts, wasting the remaining inference token budget. This indicates limitations in self-correction capabilities and clear scaling limitations (Figure 3).
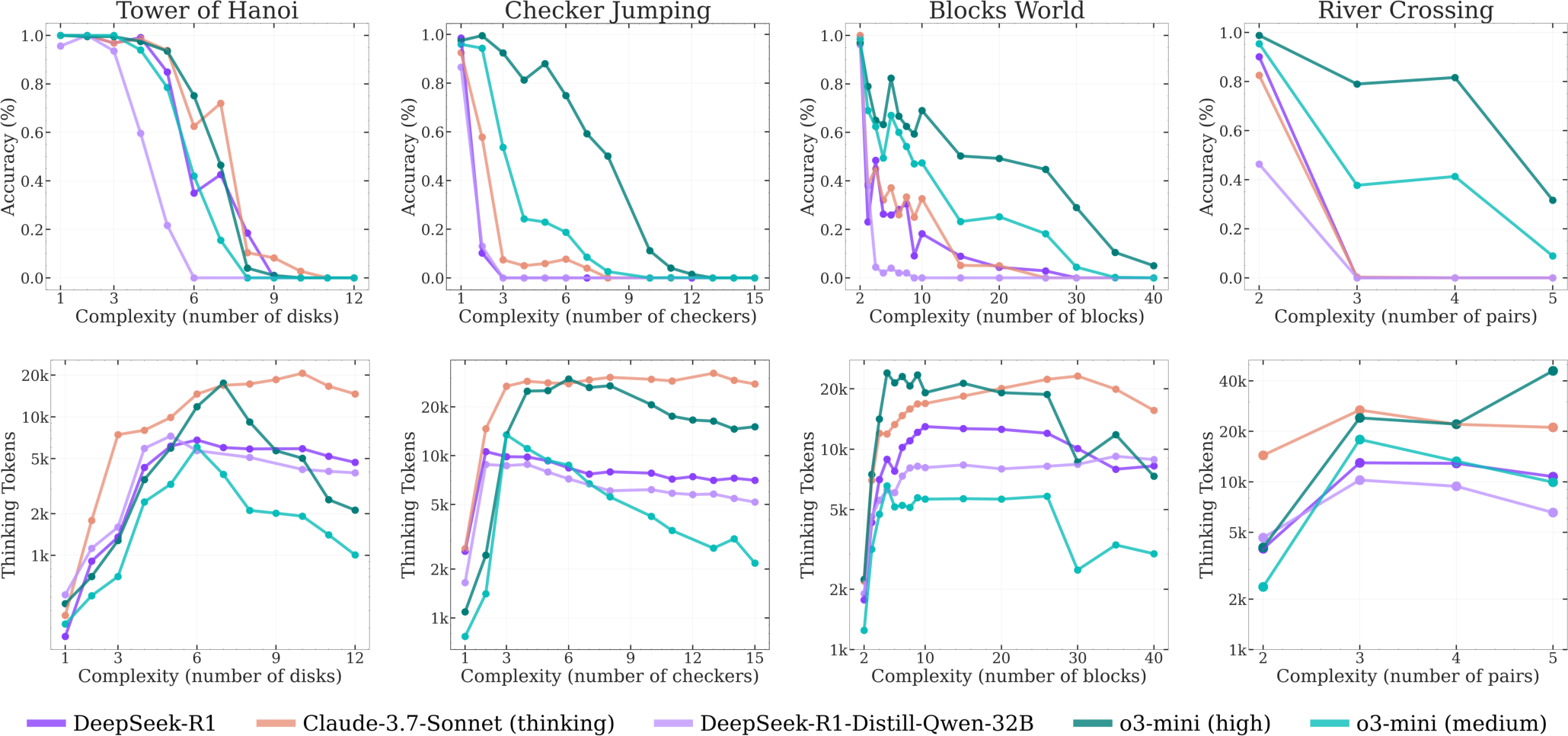
Figure 3: Accuracy and thinking tokens versus problem complexity for reasoning models, demonstrating the point at which reasoning collapses and effort decreases.
The paper further highlights LRMs' limitations in exact computation. Even when provided with explicit algorithms, the models fail to improve performance, and the observed collapse still occurs at roughly the same point (Figure 4). This is particularly evident in the Tower of Hanoi and Checker Jumping puzzles, suggesting that LRMs struggle with following logical procedures and may lack robust symbolic manipulation capabilities.
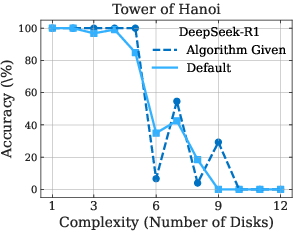
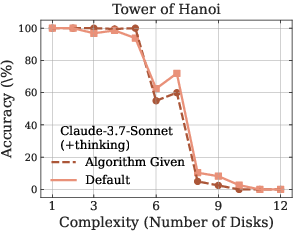
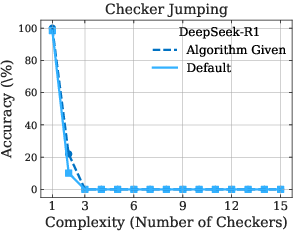
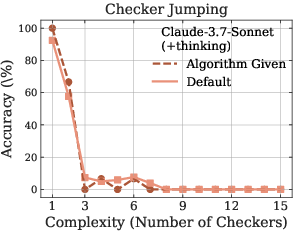
Figure 4: Performance comparison between default problem-solving and algorithm-guided execution across Tower of Hanoi and Checker Jumping puzzles, demonstrating the models' limitations in following logical procedures.
Implications and Open Questions
The findings of this study raise significant questions about the nature of reasoning in current LRM systems. The performance collapses, limitations in algorithmic execution, and inconsistent reasoning across scales highlight fundamental barriers to generalizable reasoning. The authors observe non-monotonic failure behavior with respect to problem complexity, where models fail earlier in the solution sequence for higher complexity values.
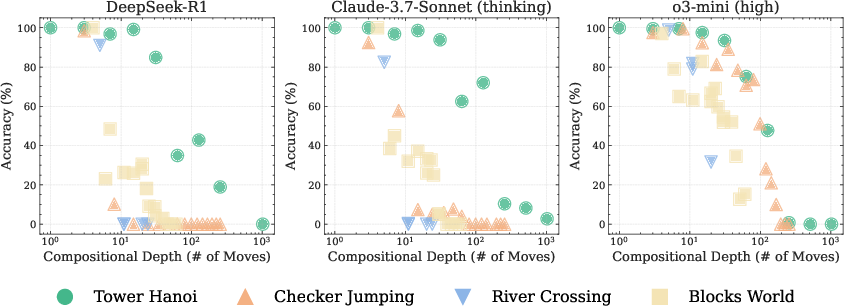
Figure 5: Accuracy versus compositional depth (number of moves required) for three LRMs across four puzzle environments, illustrating the relationship between problem complexity and model performance.
These observations suggest that LRMs may not truly understand the underlying logic of the problems but rather rely on learned solution distributions from their training data. This work opens avenues for future research into the symbolic manipulation capabilities of LRMs [marcus2003algebraic, gsmsymbolic] and the development of more robust reasoning mechanisms.
Conclusion
This paper (2506.06941) provides a systematic examination of LRMs through the lens of problem complexity, revealing both strengths and limitations in current models. The study highlights the importance of moving beyond final accuracy measurements and analyzing intermediate reasoning traces to understand how these models approach complex tasks. The findings challenge prevailing assumptions about LRM capabilities and suggest that current approaches may be encountering fundamental barriers to generalizable reasoning. The identified scaling limits, limitations in algorithmic execution, and inconsistent reasoning patterns pave the way for future investigations into the reasoning capabilities of these systems.