- The paper reveals that LLMs exhibit apparent reasoning largely due to high-probability memorization instead of genuine multistep logic.
- It employs the Tower of Hanoi puzzle in both baseline and agentic frameworks to expose performance collapses as task complexity increases.
- The study uses metrics like Jensen-Shannon divergence to quantify policy deviations, highlighting deficiencies in state tracking and adaptive planning.
Emergent Reasoning in LLMs
The paper "Limits of Emergent Reasoning of LLMs in Agentic Frameworks for Deterministic Games" (2510.15974) investigates the purported reasoning capabilities of large reasoning models (LRMs) using the Tower of Hanoi as a benchmark environment. Despite recent advances suggesting that LLMs demonstrate emergent reasoning abilities, this study challenges those claims by examining performance collapses when confronted with deterministic challenges.
Background and Motivation
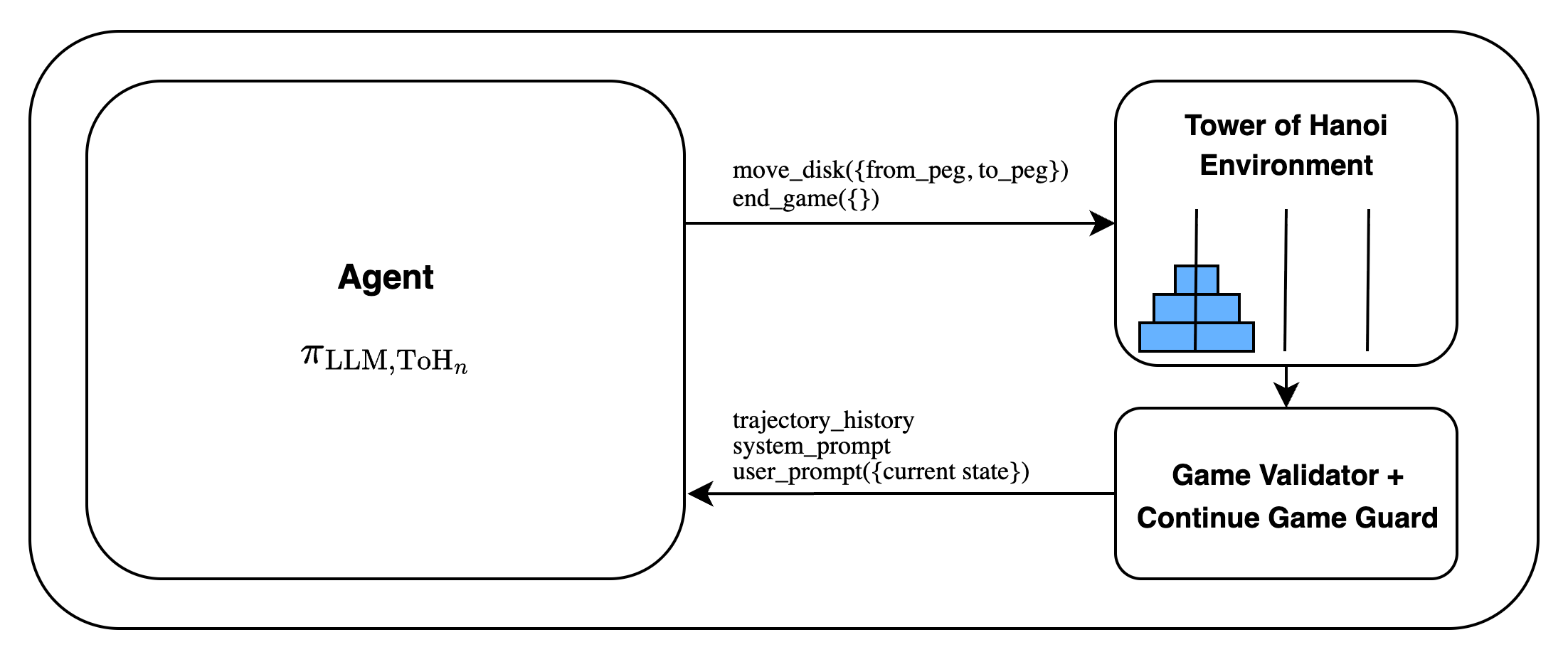
The research addresses concerns that reasoning competencies measured by existing benchmarks might conflate actual reasoning with memorization of training data. Traditional benchmarks require models to internally manage state spaces, which can obscure genuine reasoning deficits if the model fails to maintain an accurate mental representation of the environment. By leveraging an agentic framework where the model interacts with an environment, this paper seeks to distinguish genuine reasoning from limitations stemming from state-tracking inefficiencies.
Methodology
Tower of Hanoi as a Testbed
The Tower of Hanoi puzzle serves as the core testbed. This recursive problem, with its well-defined goal states and deterministic transitions, allows for controlled increases in complexity by varying the number of disks. The optimal solution path grows exponentially with the number of disks, providing a robust framework for examining multistep reasoning.
Experimental Setup
The researchers conduct two primary experimental setups:
Results
Baseline Analysis
Initial results indicate that at higher levels of complexity, both LLMs and their reasoning-enhanced counterparts exhibit a collapse in success rates, aligning with prior observations that highlight the challenges these models face with complex, multistep logical tasks.
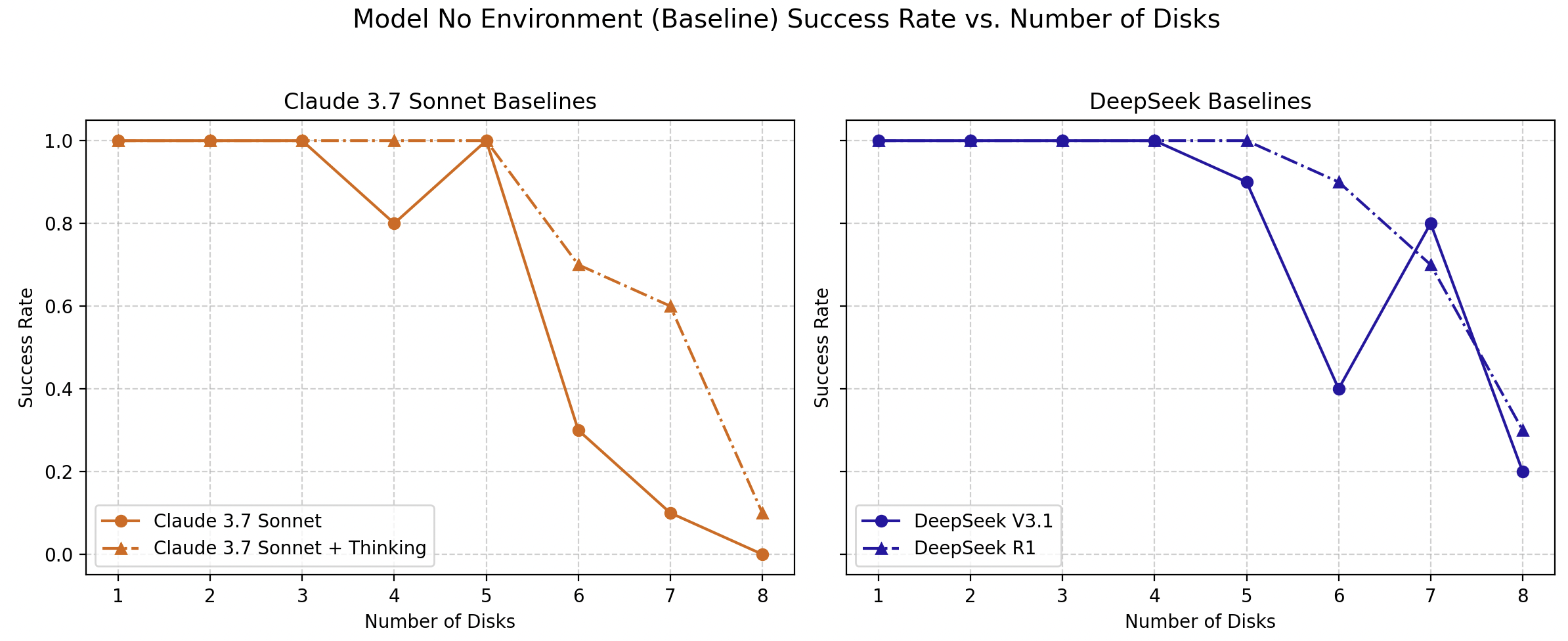
Figure 2: Comparison of success rates of LLM and LRM one-shot generation: (Left) Claude 3.7 Sonnet with and without "thinking" mechanism, (Right) DeepSeek V3.1 vs R1. Line charts display success rate as a function of puzzle complexity.
Surprisingly, the agentic framework, rather than alleviating reasoning crises, exacerbates them. Models often become trapped in deterministic loops where they repeatedly revisit prior states without progress, suggesting that agentic interaction does not inherently enhance emergent reasoning capabilities.
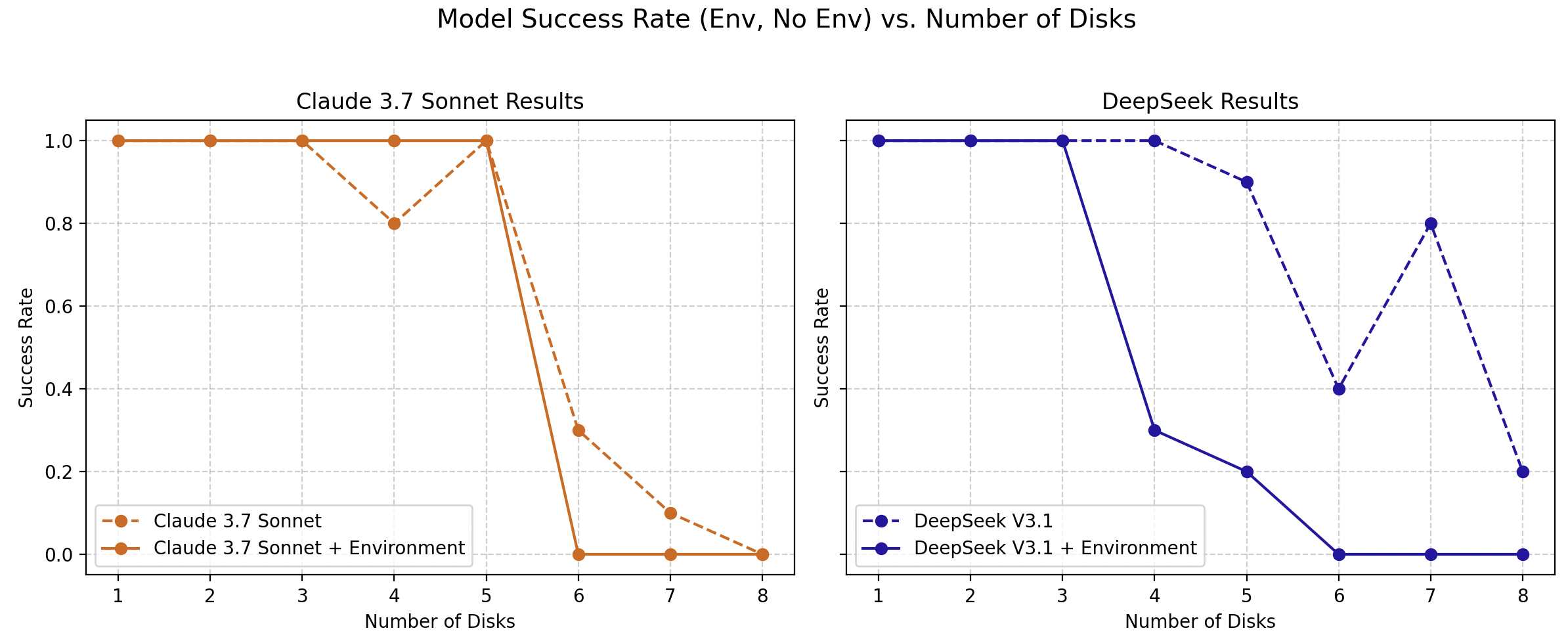
Figure 3: Success rate of models in an agentic framework (Claude 3.7 Sonnet + environment, DeepSeek V3.1 + environment) in comparison to the baseline (Claude 3.7 Sonnet, DeepSeek V3.1) at increasing complexity levels.
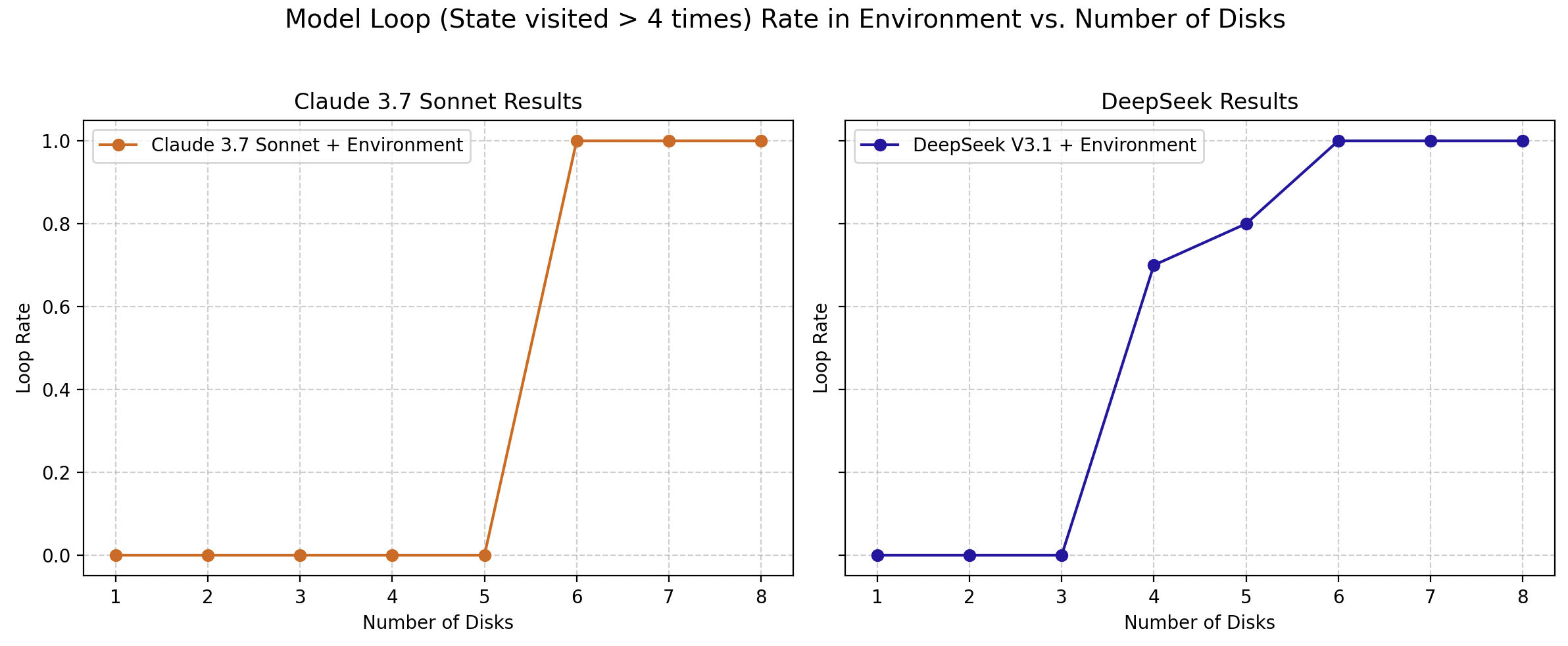
Figure 4: Loop rate of the models in an agentic framework (Claude 3.7 Sonnet + environment, DeepSeek V3.1 + environment) at increasing complexity levels.
Policy Analysis and Divergence
Using Jensen-Shannon divergence, the study quantifies divergence in model-parameterized policies from both optimal and random agents. As complexity increases, policies deviate significantly, reinforcing the notion that current LLMs lack the robust reasoning faculties necessary for optimal problem-solving in dynamic environments.
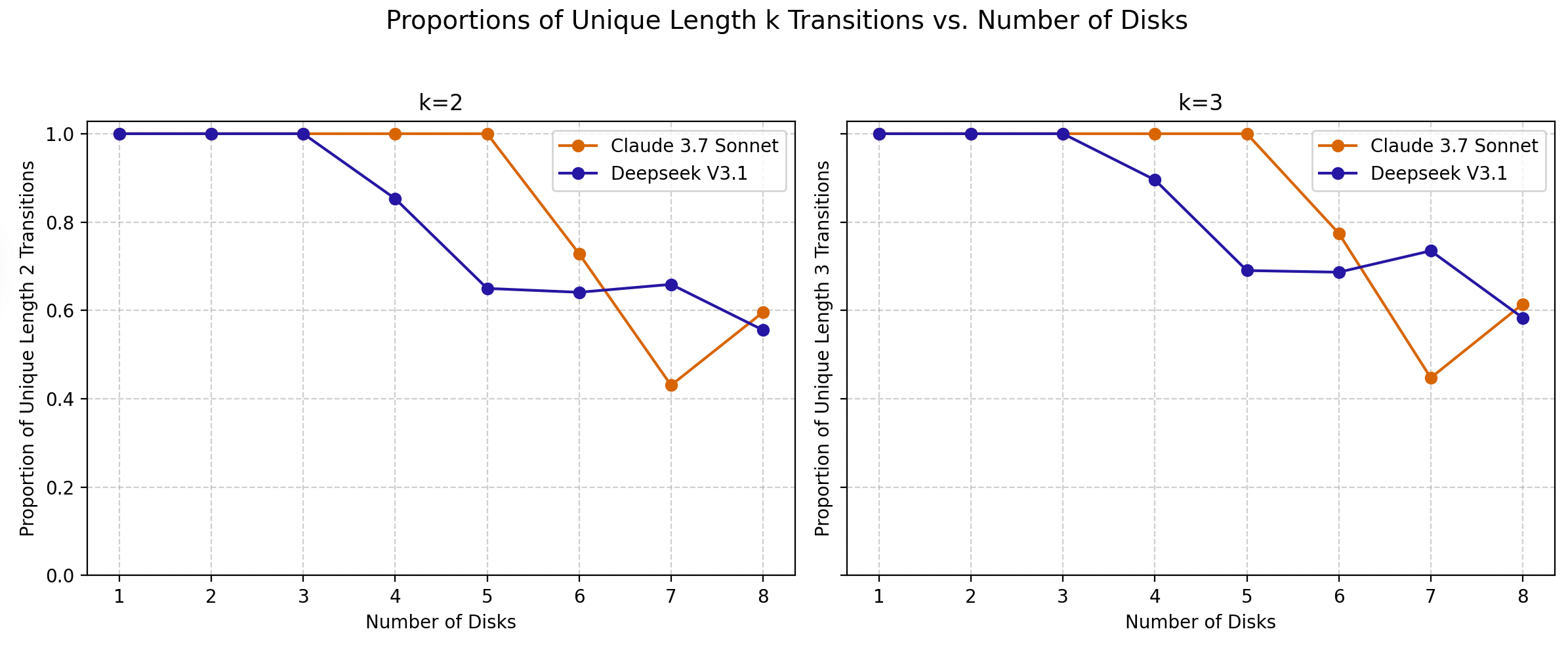
Figure 5: Proportion of unique length k transitions taken from state s, given that s was visited by the model at least twice. Lower values mean that the model takes less unique length k trajectories. These graphs are similar since every k=3 subsequence from s also contains the k=2 subsequence from s.
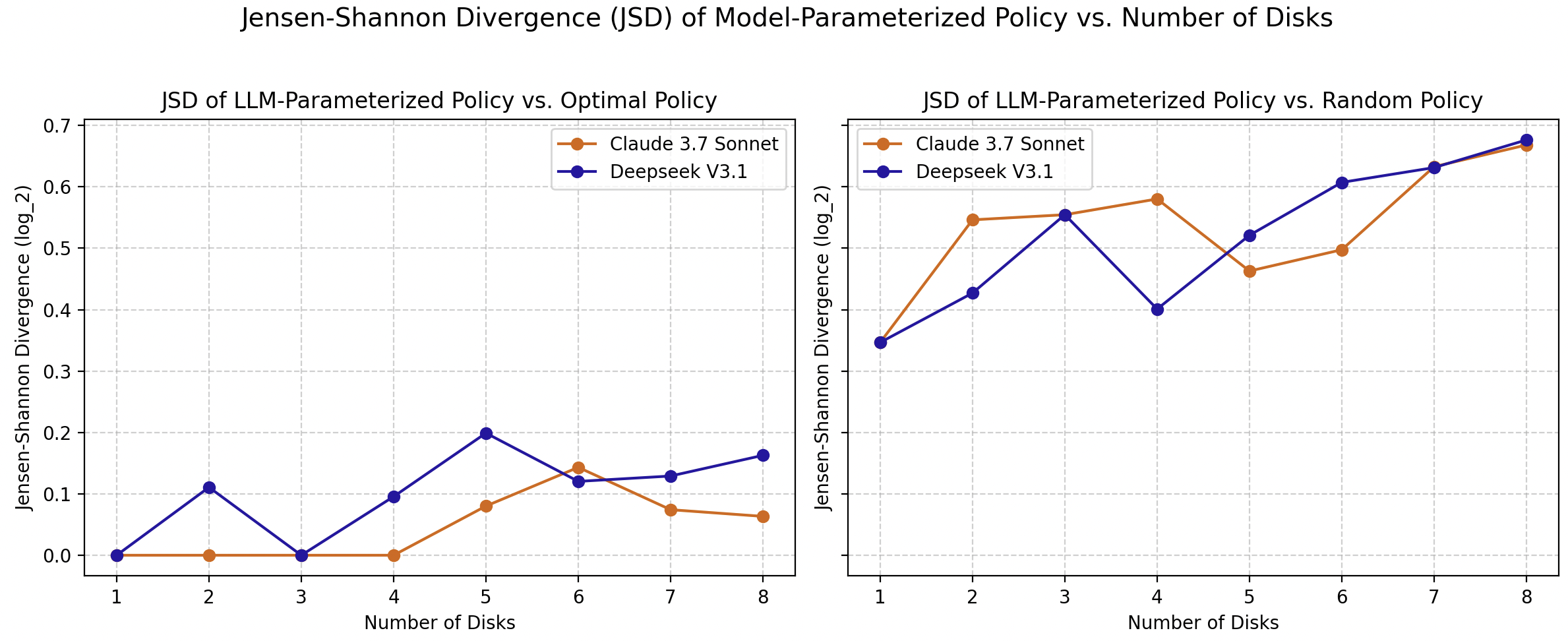
Figure 6: Jensen Shannon Divergences of LLM-Parameterized policies against Optimal policies and Random policies.
Discussion
The paper's findings suggest that apparent reasoning capabilities are in reality manifestations of high-probability mode following rather than authentic reasoning. The agentic framework exposes deficiencies in stepwise planning and logical correction, where models fail to adaptively modify behavior in light of previous errors or new state information. Such deterministic behaviors underscore the brittleness of presumed reasoning capabilities.
Conclusion
The critique of LLMs in these complex settings highlights the limitations of emergent reasoning in current architectures. This research suggests that the reasoning exhibited by these models is largely superficial, often governed by distributional patterns learned during training rather than genuine problem-solving strategies. Achieving robust reasoning capabilities remains a significant challenge, one that will require methodological innovation beyond mere scaling of existing architectures.