When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation
Abstract: Graph retrieval-augmented generation (GraphRAG) has emerged as a powerful paradigm for enhancing LLMs with external knowledge. It leverages graphs to model the hierarchical structure between specific concepts, enabling more coherent and effective knowledge retrieval for accurate reasoning.Despite its conceptual promise, recent studies report that GraphRAG frequently underperforms vanilla RAG on many real-world tasks. This raises a critical question: Is GraphRAG really effective, and in which scenarios do graph structures provide measurable benefits for RAG systems? To address this, we propose GraphRAG-Bench, a comprehensive benchmark designed to evaluate GraphRAG models onboth hierarchical knowledge retrieval and deep contextual reasoning. GraphRAG-Bench features a comprehensive dataset with tasks of increasing difficulty, coveringfact retrieval, complex reasoning, contextual summarization, and creative generation, and a systematic evaluation across the entire pipeline, from graph constructionand knowledge retrieval to final generation. Leveraging this novel benchmark, we systematically investigate the conditions when GraphRAG surpasses traditional RAG and the underlying reasons for its success, offering guidelines for its practical application. All related resources and analyses are collected for the community at https://github.com/GraphRAG-Bench/GraphRAG-Benchmark.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “When to use Graphs in RAG: A Comprehensive Analysis for Graph Retrieval-Augmented Generation”
1. What is this paper about?
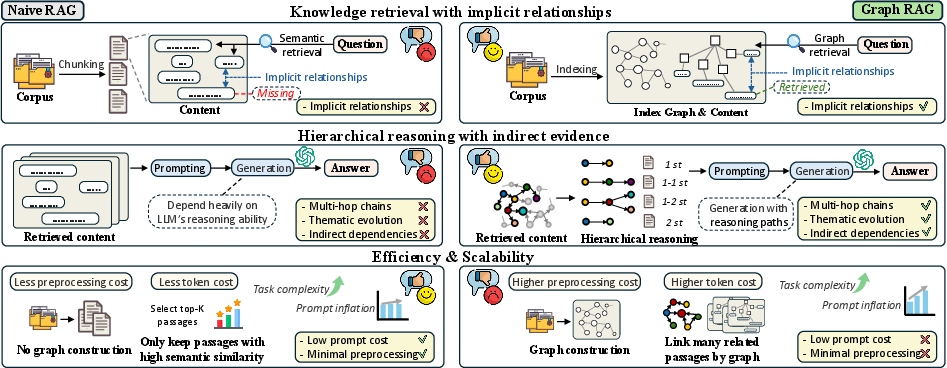
This paper looks at a way to help AI models answer questions better by letting them “look things up” while they write answers. This is called Retrieval-Augmented Generation (RAG). The authors study a special version called GraphRAG, which organizes knowledge like a map of connected ideas (a graph) instead of just a pile of text. They ask: When does using a graph actually help, and when does it not?
To answer that, they build a new test system, called GraphRAG-Bench, to fairly compare normal RAG with GraphRAG across different kinds of questions and texts.
2. What questions were the researchers trying to answer?
In simple terms, they wanted to find out:
- Is using graphs with RAG (GraphRAG) really better than regular RAG?
- What types of questions or tasks benefit most from GraphRAG?
- How should we measure the parts of a GraphRAG system (building the graph, finding info, writing the answer), not just the final answer?
- What are the trade-offs, like extra time or cost?
3. How did they study it? (Methods explained simply)
Think of answering questions like doing a school project:
- Regular RAG: You search for text chunks that look similar to your question and read them directly.
- GraphRAG: Before answering, you turn the information into a “mind map” with dots (ideas, called nodes) and lines (connections, called edges). Then, when asked a question, you can follow the connections to gather related facts that may be spread out.
To test these ideas fairly, they built GraphRAG-Bench:
- Two kinds of reading material:
- Medical guidelines (very organized and structured).
- Classic novels (messy, storytelling text with less structure).
- This lets them see how both methods work on tidy vs messy information.
- Four levels of tasks that get harder and more “thinky”:
- Level 1: Fact retrieval — simple facts (like “Where is Mont St. Michel?”).
- Level 2: Complex reasoning — connecting multiple ideas across texts.
- Level 3: Contextual summary — pulling together scattered details into a clear summary.
- Level 4: Creative generation — writing something new that still stays true to the facts.
- Measuring the whole pipeline (not just the final answer):
- Graph quality: How good is the mind map?
- Nodes (how many ideas were found).
- Edges (how many connections).
- Average degree and clustering (how well ideas are woven together).
- Retrieval quality: Did it find the right info?
- Evidence recall (did it grab all the important pieces?).
- Relevance (is what it grabbed actually on-topic?).
- Generation quality: Is the answer good?
- Accuracy and ROUGE (matches the reference answer).
- Faithfulness (does the answer stick to the retrieved info, no made-up stuff?).
- Evidence coverage (does it cover all the key points?).
They then compared popular systems (like Microsoft GraphRAG, HippoRAG, LightRAG, RAPTOR, etc.) with regular RAG.
Helpful analogies for terms:
- Graph (nodes and edges): A mind map or a city map (cities are nodes, roads are edges).
- Recall: Did you collect all the puzzle pieces?
- Relevance: Are those pieces from the right puzzle?
- Faithfulness: Did you only use the pieces you actually collected (no guessing)?
- Tokens: The number of words the AI reads and writes. More tokens = more cost/time.
4. What did they find, and why does it matter?
Key results you can remember:
- For simple facts, regular RAG is as good or better.
- If you just need a quick fact, the extra graph work can add noise or overhead and doesn’t help much.
- For harder thinking (multi-step reasoning, summaries, creative tasks), GraphRAG often wins.
- When you must connect many ideas spread across different places, a mind map helps you find and link them.
- GraphRAG tends to be more factually careful in creative tasks.
- It can keep stories grounded in real details, but sometimes covers fewer different points than regular RAG.
- Retrieval trade-offs:
- Regular RAG is strong for simple questions where the answer is in one place.
- GraphRAG shines when info is scattered, because it follows connections to gather what’s needed.
- For very open-ended or creative tasks, GraphRAG may pull in more total evidence but also more redundancy.
- Graph design matters a lot.
- Systems that build richer, denser graphs (more useful connections) tend to retrieve better and answer better. For example, a method called HippoRAG2 built very connected graphs and did well.
- Cost and efficiency are real issues.
- Some GraphRAG systems make extremely long prompts (the amount of text the AI must process), which can be expensive and slow.
- A few systems manage to stay more efficient, but in general, using graphs adds token cost, especially as tasks get harder.
- Existing benchmarks weren’t great for testing GraphRAG.
- Many past tests focused too much on simple retrieval and used text without clear hierarchies. This paper’s new benchmark fixes that by including structured and unstructured texts and by measuring each step of the process.
5. Why does this research matter? What’s the impact?
- Practical guidance: Use regular RAG for quick fact questions. Use GraphRAG for tasks that require tying together many related ideas, building explanations, or staying highly faithful to complex sources.
- Better testing tools: Their new GraphRAG-Bench gives the AI community a fair, detailed way to measure where graph-based methods help, and where they don’t.
- Smarter systems: Builders of AI assistants can design better graphs (richer connections) and control costs by avoiding overly long prompts.
- Real-world benefit: In fields like medicine or law, where knowledge is structured and relationships matter, GraphRAG can improve accuracy, reasoning, and trustworthiness.
If you think of RAG as looking up a quote in a book, then GraphRAG is like using a carefully drawn map of the whole library to find not just the quote, but also the related chapters and references that help you truly understand the bigger picture. This paper shows when that map is worth using—and gives a strong way to test it.
Collections
Sign up for free to add this paper to one or more collections.