G1: Teaching LLMs to Reason on Graphs with Reinforcement Learning
Abstract: Although LLMs have demonstrated remarkable progress, their proficiency in graph-related tasks remains notably limited, hindering the development of truly general-purpose models. Previous attempts, including pretraining graph foundation models or employing supervised fine-tuning, often face challenges such as the scarcity of large-scale, universally represented graph data. We introduce G1, a simple yet effective approach demonstrating that Reinforcement Learning (RL) on synthetic graph-theoretic tasks can significantly scale LLMs' graph reasoning abilities. To enable RL training, we curate Erd~os, the largest graph reasoning dataset to date comprising 50 diverse graph-theoretic tasks of varying difficulty levels, 100k training data and 5k test data, all drived from real-world graphs. With RL on Erd~os, G1 obtains substantial improvements in graph reasoning, where our finetuned 3B model even outperforms Qwen2.5-72B-Instruct (24x size). RL-trained models also show strong zero-shot generalization to unseen tasks, domains, and graph encoding schemes, including other graph-theoretic benchmarks as well as real-world node classification and link prediction tasks, without compromising general reasoning abilities. Our findings offer an efficient, scalable path for building strong graph reasoners by finetuning LLMs with RL on graph-theoretic tasks, which combines the strengths of pretrained LLM capabilities with abundant, automatically generated synthetic data, suggesting that LLMs possess graph understanding abilities that RL can elicit successfully. Our implementation is open-sourced at https://github.com/PKU-ML/G1, with models and datasets hosted on Hugging Face collections https://huggingface.co/collections/PKU-ML/g1-683d659e992794fc99618cf2 for broader accessibility.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new way to teach LLMs to solve “graph” problems. A graph is just a set of dots (called nodes) connected by lines (called edges). Think of:
- people and their friendships,
- cities and the roads between them,
- web pages and the links that connect them.
Many real-world problems are graph problems, like finding the fastest route, spotting communities, or predicting new connections. Today’s LLMs are good at language but still struggle with graph reasoning. The authors propose G1, a simple training method that uses reinforcement learning (RL) to help LLMs get much better at graph puzzles—without needing lots of human-written answers.
What questions did the researchers ask?
They focused on a few clear questions:
- Can we make LLMs better at graph reasoning using reinforcement learning (practice with feedback), instead of lots of human-labeled data?
- If we train on many small, synthetic (computer-made) graph puzzles, will the model also get better at new, unseen tasks and on real-world graphs?
- Can we do all this without hurting the model’s general skills in math and other subjects?
How did they study it?
They built a large set of graph puzzles and trained LLMs with RL, giving scores when the model’s answers were correct. Here’s the approach in everyday language:
Building a big “practice set” of graph puzzles
- They collected 50 different kinds of graph problems (from easy to very hard), such as:
- counting nodes or edges (easy),
- finding shortest paths or cycles (medium/hard),
- solving tougher puzzles like maximum flow or traveling salesperson (very hard).
- They created 100,000 practice questions and 5,000 test questions.
- Instead of using random toy graphs, they sampled small subgraphs from real networks (like citation networks or social graphs) to make practice more realistic.
- They used a standard graph software library (NetworkX) to compute correct answers automatically.
Training with reinforcement learning (RL)
- RL is like practicing a game: the model tries an answer; if it’s right, it gets a reward (points); if not, it doesn’t. Over time, it learns strategies that earn more points.
- Because the problems have clear right/wrong solutions, the computer can instantly check answers—no humans needed.
- They designed simple reward rules:
- Exact match for single-number answers,
- Partial credit for “set” answers (using overlap, like the Jaccard index),
- Program-based checks for problems with many possible correct solutions (like “Is this a valid Hamiltonian path?”).
A small warm-up step (optional)
- Sometimes the model is so lost at the start that it never gets rewards. To fix this, the authors sometimes gave it a short “warm-up” using supervised fine-tuning (SFT):
- Direct-SFT: show question and final answer,
- CoT-SFT: show question, step-by-step reasoning (“chain of thought”), and final answer.
- Then they switched to RL, which is what really improved graph reasoning.
What did they find?
Training with RL on these graph puzzles made a big difference. Here are the highlights:
- Strong gains on graph tasks:
- Their 7B-parameter G1 model beat many larger or popular models on the 50-task test set.
- Even their small 3B-parameter G1 model outperformed a much larger 72B model on these graph problems.
- Generalizes to new situations:
- It worked well on other graph benchmarks (GraphWiz, GraphArena) that used different styles of writing graphs (like names instead of numbers) and included unseen tasks.
- It handled larger graphs than it saw during training.
- Helps on real-world graph tasks:
- It improved on node classification and link prediction in citation networks (Cora, PubMed), which mix text and graph structure.
- Keeps or slightly improves general reasoning:
- After RL on graphs, the model’s scores on math (GSM8K, MATH) and broad knowledge tests (MMLU-Pro) stayed strong or improved, meaning the model didn’t “forget” other skills.
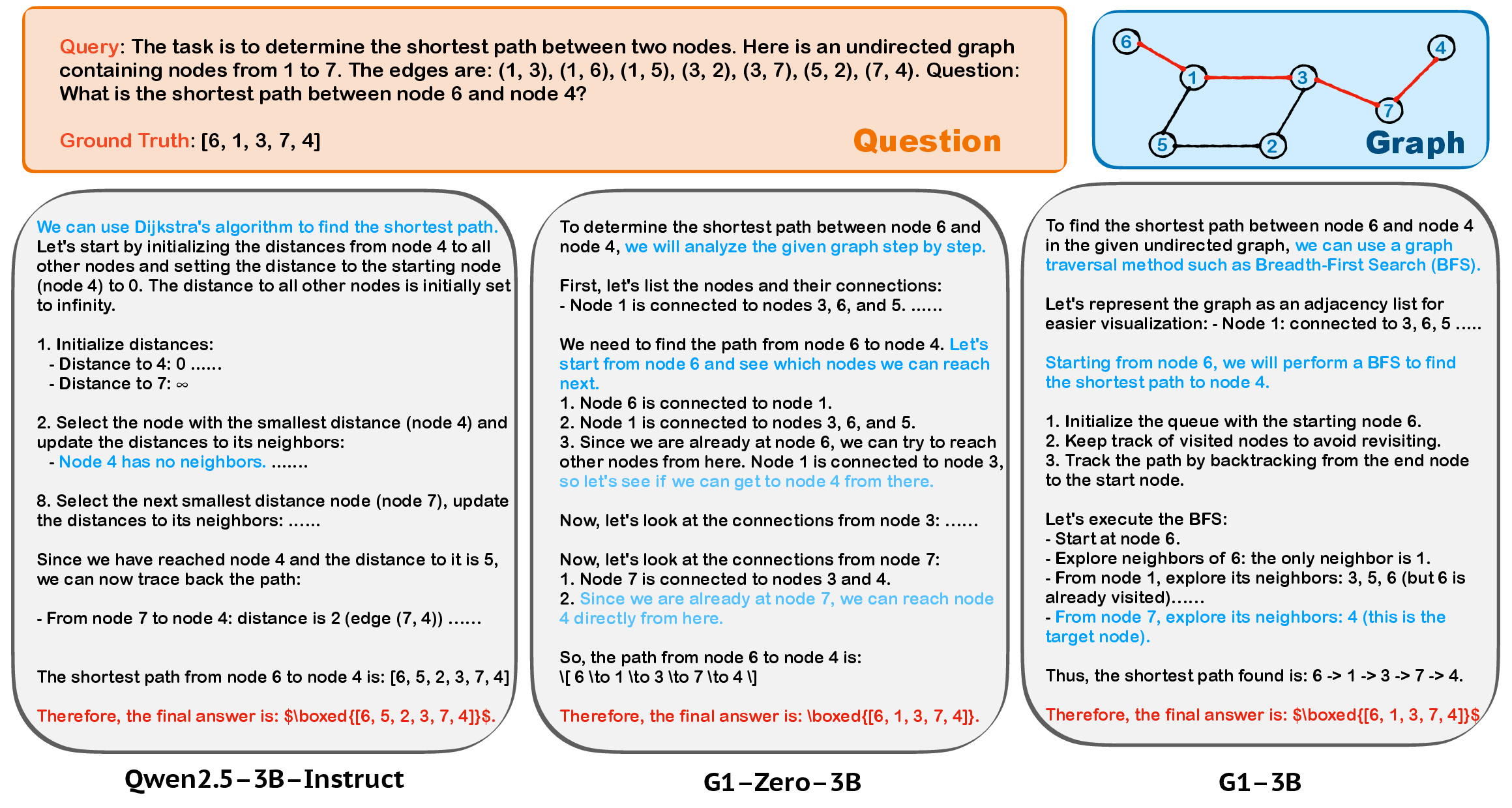
- Learns smarter strategies:
- For shortest path problems, the RL-trained model moved away from clumsy, error-prone methods and leaned into cleaner, more reliable strategies (like BFS for unweighted graphs), much like a student discovering which tools fit best.
Why does this matter?
- It shows a scalable, low-cost way to teach LLMs graph reasoning using computer-generated practice and automatic checks, instead of expensive human labels.
- It suggests today’s LLMs already have some buried “graph sense” that RL can bring out.
- Better graph reasoning matters everywhere: social networks (community detection, recommendations), biology (protein interaction networks), maps and routing, cybersecurity, and more.
- The method didn’t hurt general intelligence—and sometimes even helped—so it’s a promising step toward more versatile, general-purpose AI.
In short: By letting an LLM “play” thousands of graph puzzles and rewarding correct solutions, G1 turns a LLM into a strong graph reasoner that generalizes to new tasks and real data—without needing humans to hand-craft lots of training answers.
Collections
Sign up for free to add this paper to one or more collections.