- The paper demonstrates that Whisper outperforms Wav2vec2 and WavLM in semantic-content tasks under low-resource conditions.
- It reveals that Whisper's well-clustered, near-isotropic representation space enables faster convergence in tasks like ASR and keyword spotting.
- Different fine-tuning strategies, including vanilla and weighted-sum configurations, crucially impact performance across both content and speaker-focused tasks.
Investigating Pre-trained Audio Encoders in the Low-Resource Condition
This paper, "Investigating Pre-trained Audio Encoders in the Low-Resource Condition" (2305.17733), explores the operational efficacy of three pre-trained speech encoders—Wav2vec2, WavLM, and Whisper—in low-resource conditions, focusing on key speech tasks. Through extensive experiments, the study explores the relationship between pre-training protocols and representational properties, highlighting Whisper's relative superiority in low-resource contexts and its performance degradation when speaker information is paramount.
The paper investigates the performance of Wav2vec2, WavLM, and Whisper across seven speech tasks, namely Automatic Speech Recognition (ASR), Speaker Diarisation (SD), Intent Classification (IC), Slot Filling (SF), Keyword Spotting (KS), Speaker Identification (SID), and Speech Translation (ST). It employs a low-resource approach by sampling limited data (1%, 5%, and 10%) from corresponding datasets. The encoders are evaluated using standard performance metrics such as WER, DER, ACC, F1 score, and BLEU.
Key Findings
Whisper, despite its compact architecture, outperforms its counterparts significantly in tasks requiring semantic-content understanding such as ASR, KS, and IC. Specifically, Whisper's superior clustering in representation spaces facilitates faster convergence and higher accuracy in low-resource settings.



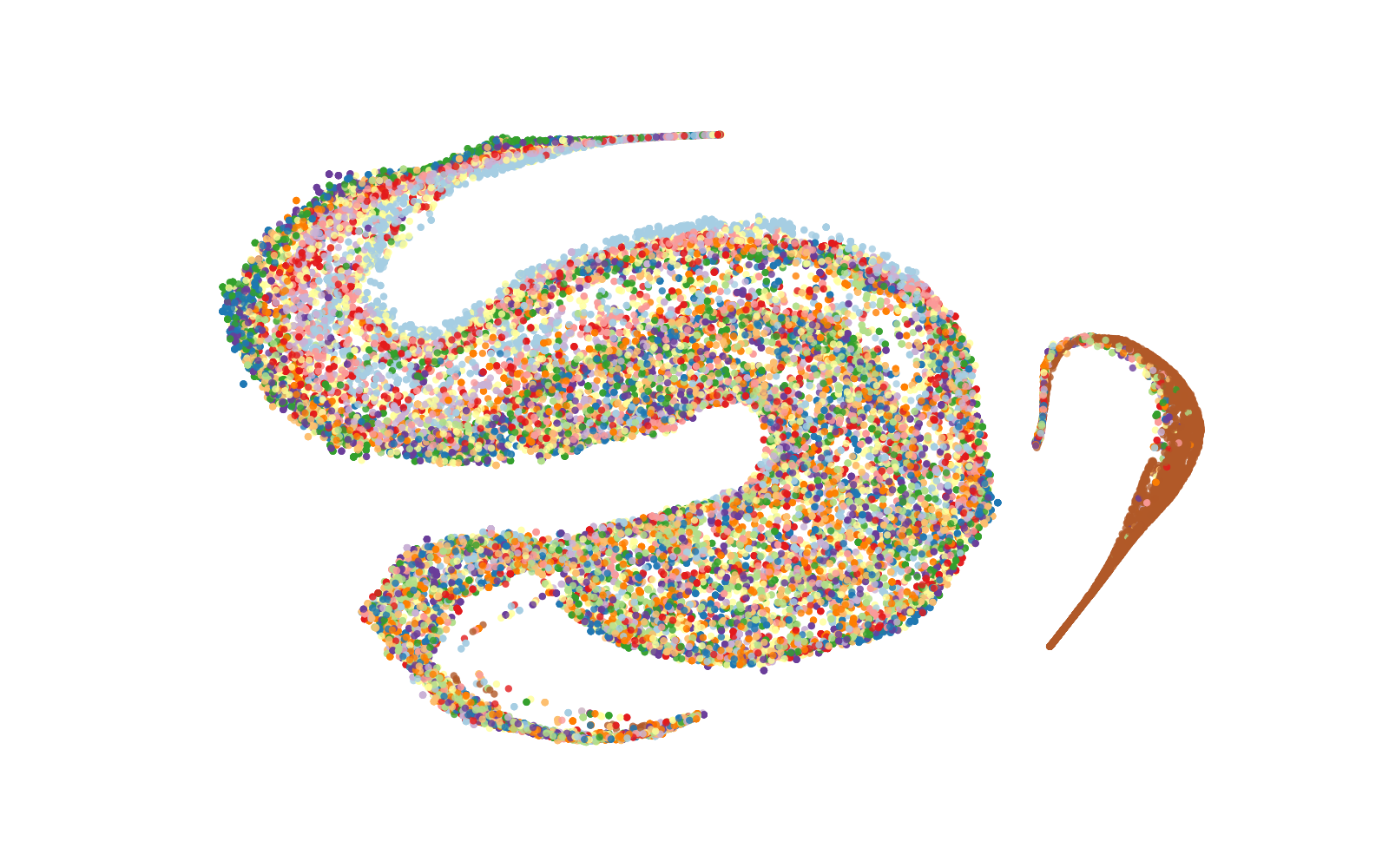


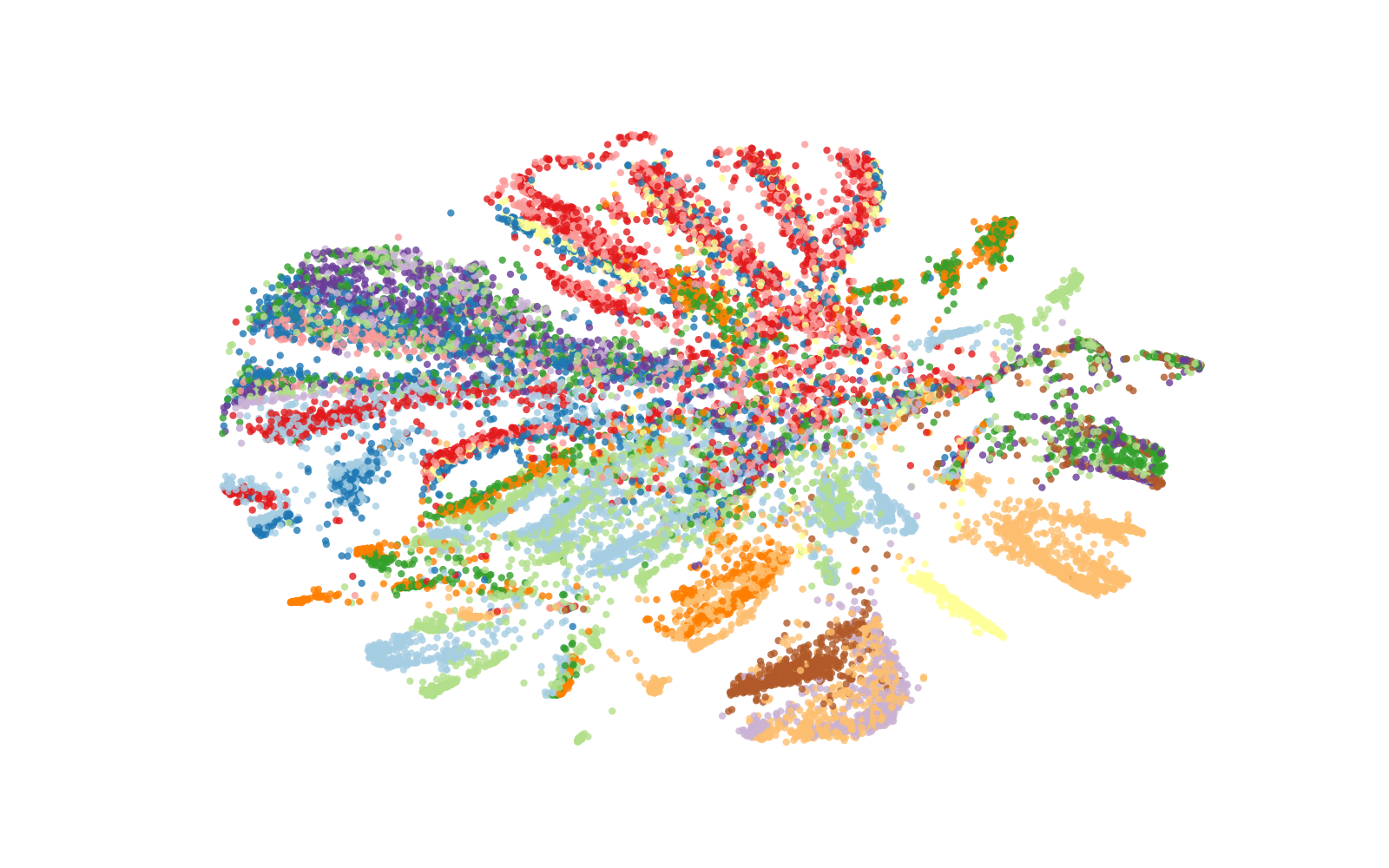


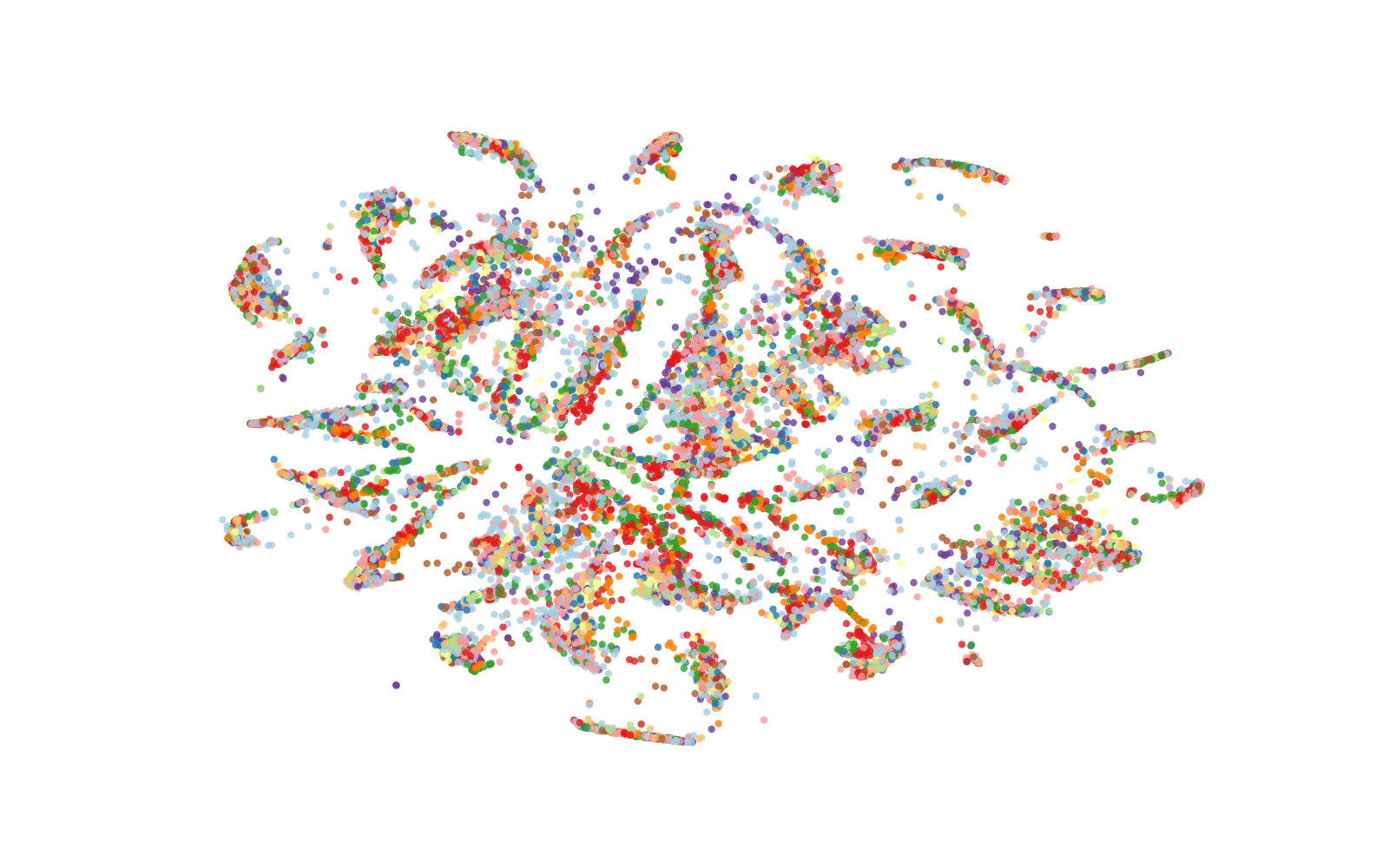
Figure 1: t-SNE visualisation of the representation spaces produced by the encoders on KS (top) and IC (bottom) tasks training set (prior to fine-tuning) with colours indicating class labels.
Conversely, in speaker-focused tasks such as SID, Whisper's performance lags behind, attributed to its pre-training emphasis on content representation rather than speaker features.
Representation Space Analysis
The paper offers a qualitative and quantitative analysis of representation spaces using techniques like t-SNE visualization and isotropy measurement. Whisper demonstrates well-defined clustering and near-isotropic distribution in representation spaces, enhancing its utility in semantic-content tasks. Its isotropy approaches that of top-performing text-based models, indicating a well-utilized representation space.
Task Fine-tuning Strategies
Comparative analysis of different task fine-tuning approaches—Vanilla, Weighted-sum, and Fine-tuning—suggests that Whisper's Vanilla setup performs optimally for content-related tasks. In contrast, the Weighted-sum configuration improves SID task outcomes, which aligns with the model's distribution of speaker information across intermediate layers.
The distribution of weight coefficients across layers indicates diverse contributions in task performance, with a marked importance of final layers in content tasks and shifted emphasis in speaker tasks.
Implications and Future Work
These findings elucidate the nuanced capabilities of pre-trained encoders in resource-constrained environments, hinting at strategic fine-tuning approaches. It underscores the potential of Whisper's architecture in optimizing semantic-content tasks and presents avenues for improving its speaker-focused task performance.
Future research may explore hybrid models that integrate Whisper's semantic strengths with enhanced speaker representation capabilities, as well as adaptive pre-training protocols that balance content and speaker information capture.
Conclusion
The study provides valuable insights into the deployment of pre-trained audio encoders in low-resource speech tasks, revealing Whisper's competitive edge in semantic-content tasks. It lays the groundwork for deliberate pre-training and fine-tuning strategies that optimize representational properties for diverse task requirements.