Discrete Audio Representation as an Alternative to Mel-Spectrograms for Speaker and Speech Recognition
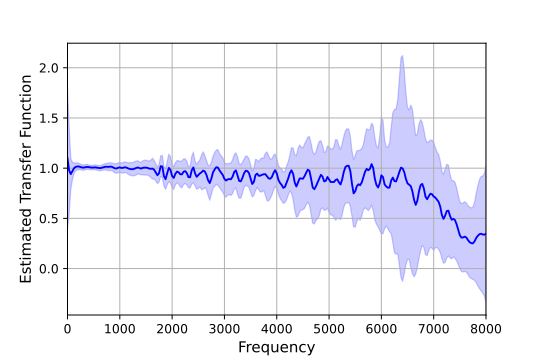
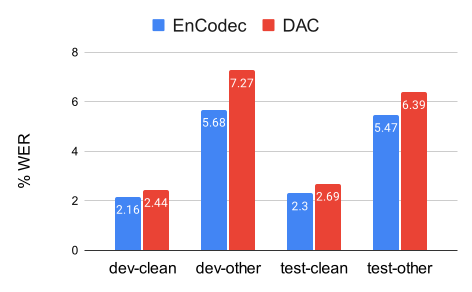
Abstract: Discrete audio representation, aka audio tokenization, has seen renewed interest driven by its potential to facilitate the application of text language modeling approaches in audio domain. To this end, various compression and representation-learning based tokenization schemes have been proposed. However, there is limited investigation into the performance of compression-based audio tokens compared to well-established mel-spectrogram features across various speaker and speech related tasks. In this paper, we evaluate compression based audio tokens on three tasks: Speaker Verification, Diarization and (Multi-lingual) Speech Recognition. Our findings indicate that (i) the models trained on audio tokens perform competitively, on average within $1\%$ of mel-spectrogram features for all the tasks considered, and do not surpass them yet. (ii) these models exhibit robustness for out-of-domain narrowband data, particularly in speaker tasks. (iii) audio tokens allow for compression to 20x compared to mel-spectrogram features with minimal loss of performance in speech and speaker related tasks, which is crucial for low bit-rate applications, and (iv) the examined Residual Vector Quantization (RVQ) based audio tokenizer exhibits a low-pass frequency response characteristic, offering a plausible explanation for the observed results, and providing insight for future tokenizer designs.
- Tom Brown et al., “Language models are few-shot learners,” Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020.
- Hugo Touvron et al., “Llama 2: Open foundation and fine-tuned chat models,” 2023.
- “Robust speech recognition via large-scale weak supervision,” 2022.
- “Hubert: Self-supervised speech representation learning by masked prediction of hidden units,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 3451–3460, 2021.
- “W2v-bert: Combining contrastive learning and masked language modeling for self-supervised speech pre-training,” in 2021 IEEE ASRU. IEEE, 2021, pp. 244–250.
- “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.
- “Google usm: Scaling automatic speech recognition beyond 100 languages,” arXiv preprint arXiv:2303.01037, 2023.
- “Neural codec language models are zero-shot text to speech synthesizers,” arXiv preprint arXiv:2301.02111, 2023.
- Ziqiang Zhang et al., “Speak foreign languages with your own voice: Cross-lingual neural codec language modeling,” arXiv preprint arXiv:2303.03926, 2023.
- “Viola: Unified codec language models for speech recognition, synthesis, and translation,” arXiv preprint arXiv:2305.16107, 2023.
- “Musiclm: Generating music from text,” arXiv preprint arXiv:2301.11325, 2023.
- “Audiolm: a language modeling approach to audio generation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2023.
- “Audiopalm: A large language model that can speak and listen,” arXiv preprint arXiv:2306.12925, 2023.
- “Soundstream: An end-to-end neural audio codec,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 495–507, 2021.
- “High fidelity neural audio compression,” arXiv preprint arXiv:2210.13438, 2022.
- “High-fidelity audio compression with improved rvqgan,” arXiv preprint arXiv:2306.06546, 2023.
- “Titanet: Neural model for speaker representation with 1d depth-wise separable convolutions and global context,” in ICASSP 2022. IEEE, 2022, pp. 8102–8106.
- “Fast conformer with linearly scalable attention for efficient speech recognition,” arXiv:2305.05084, 2023.
- “Arcface: Additive angular margin loss for deep face recognition,” in CVPR 2019, 2019, pp. 4685–4694.
- “Conformer: Convolution-augmented transformer for speech recognition,” Interspeech, 2020.
- “Sentencepiece: A simple and language independent subword tokenizer and detokenizer for neural text processing,” 2018.
- “VoxCeleb2: Deep speaker recognition,” in Interspeech, 2018.
- “Librispeech: an asr corpus based on public domain audio books,” in ICASSP 2015. IEEE, 2015, pp. 5206–5210.
- “Mls: A large-scale multilingual dataset for speech research,” arXiv preprint arXiv:2012.03411, 2020.
- “The ami meeting corpus: A pre-announcement,” in International workshop on machine learning for multimodal interaction. Springer, 2005, pp. 28–39.
- “Pyannote. audio: neural building blocks for speaker diarization,” in ICASSP 2020. IEEE, 2020, pp. 7124–7128.
- “The nist speaker recognition evaluations: 1996-2001,” in 2001: A Speaker Odyssey-The Speaker Recognition Workshop, 2001.
- “Callhome american english speech,” Linguistic Data Consortium, 1997.
- “Common voice: A massively-multilingual speech corpus,” arXiv preprint arXiv:1912.06670, 2019.
- “Voxpopuli: A large-scale multilingual speech corpus for representation learning, semi-supervised learning and interpretation,” arXiv preprint arXiv:2101.00390, 2021.
- “Fisher spanish speech (ldc2010s01),” Web Download. Philadelphia: Linguistic Data Consortium, 2010.
- “Specaugment: A simple data augmentation method for automatic speech recognition,” Interspeech, 2019.
- “NeMo: a toolkit for Conversational AI and Large Language Models,” .
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.