- The paper introduces a novel latent diffusion-based T2A framework that integrates LLMs for enhanced temporal modeling in audio generation.
- The methodology employs a dual text encoder—combining a frozen CLAP and a trainable T5 encoder—and a feed-forward Transformer-VAE backbone to support variable-length audio synthesis.
- Experimental results on datasets like AudioCaps and Clotho demonstrate superior performance with improved semantic alignment, sound quality, and temporal consistency.
Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation
In this detailed review, we will examine the paper titled "Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation" (2305.18474), which presents advancements in the field of text-to-audio synthesis through a novel approach that enhances temporal modeling. This paper builds upon previous methodologies by incorporating LLMs to address semantic misalignment and temporal consistency issues, proposing several innovative techniques that improve audio generation quality and diversity.
Background and Motivation
Text-to-audio (T2A) synthesis is a complex task that involves generating audio content from textual input, playing a crucial role in applications such as sound effect generation, virtual reality, and multimedia production. Existing methods often struggle with semantic misalignment and poor temporal consistency due to limitations in natural language understanding and the reliance on 2D spatial structures for T2A tasks. "Make-An-Audio 2" addresses these challenges by focusing on temporal enhancement and novel architectural features.
The key motivations for this work include:
- Semantic Misalignment and Temporal Disorder: Previous models often fail to align the semantic content of text with the temporal order of audio events, leading to disordered sound sequences.
- Inadequate Handling of Variable-Length Audios: Conventional models rely on 2D spatial processing, which inadequately captures temporal details necessary for variable-length audio generation.
- Data Scarcity: The lack of high-quality, temporally aligned audio-text pairs impedes model training and generalization.
Methodology
The authors introduce "Make-An-Audio 2," a latent diffusion-based T2A framework that enhances temporal information capture using the following innovations:
- Temporal Enhancement Using LLMs: Pre-trained LLMs are utilized to parse text inputs into structured captions as <event {content} order> pairs, thereby aiding the model in capturing intricate temporal relations. This parsing allows the synthesis model to better understand and replicate the timing of events.
- Dual Text Encoder Architecture: A dual encoder approach is adopted, combining a frozen CLAP encoder for overall text understanding with a trainable T5 encoder for detailed temporal information extraction. This setup ensures comprehensive text-to-embedding translation that integrates semantic and temporal information effectively.
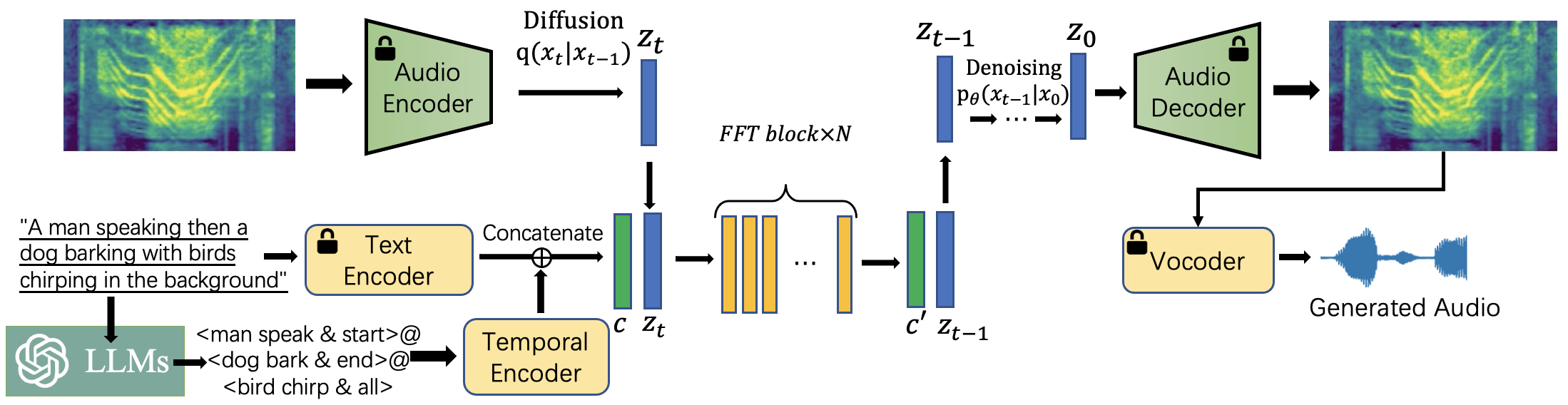
Figure 1: A high-level overview of Make-An-Audio 2. Note that modules printed with a lock are frozen when training the T2A model.
- Feed-Forward Transformer-Based Diffusion Backbone: The conventional U-Net backbone is replaced with a feed-forward Transformer and 1D-convolution-based audio variational autoencoder (VAE). This change improves the processing and generation of variable-length audio sequences, effectively addressing the shortcomings of past 2D approaches.
- LLM-Based Data Augmentation: The work leverages LLMs to enrich audio-text datasets by generating diverse natural language captions from structured data. This strategy addresses the data scarcity by creating a rich set of temporally informed audio-text pairs, essential for robust model training.
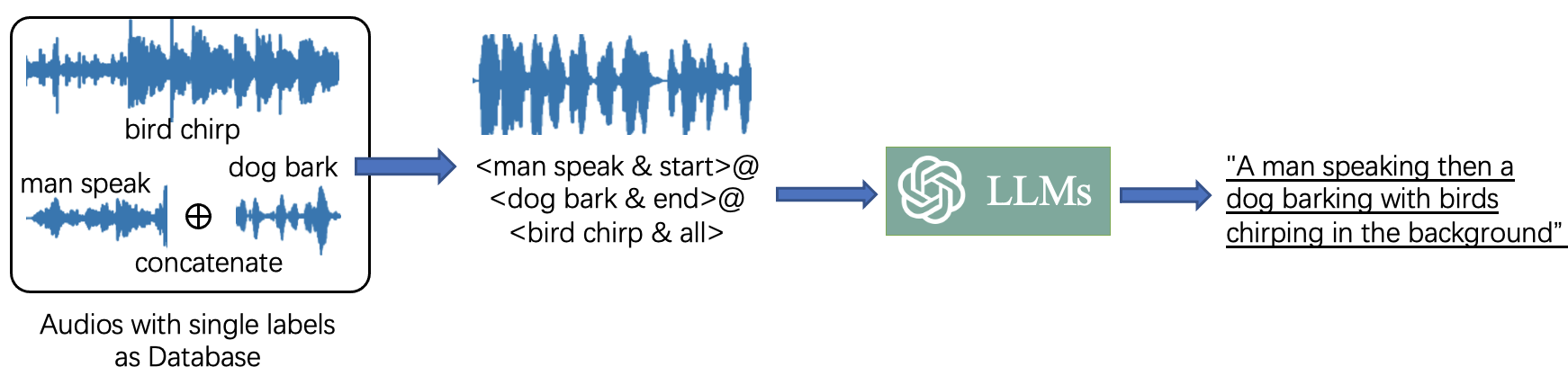
Figure 2: Overview of LLM-based data augmentation. We use single-labeled audios and their labels as a database. Composing complex audios and the structured captions with these data. We then use LLM to generate diverse natural language captions by the constructed captions and appropriate prompt.
Experimental Evaluation
The performance of Make-An-Audio 2 is extensively evaluated against several baseline models such as AudioLDM and TANGO. The experiments are conducted on datasets like AudioCaps and Clotho, focusing on both objective measures (e.g., Fréchet Audio Distance, inception score) and subjective assessments (e.g., human-evaluated mean opinion scores).
The findings show that Make-An-Audio 2 outperforms competitors by notable margins across key metrics, particularly demonstrating superior temporal understanding and sound quality. The model attains high fidelity in semantic consistency and generates realistic audio samples that align well with their textual descriptions.
Implications and Future Directions
The Make-An-Audio 2 framework introduces a significant step forward in T2A synthesis by enhancing temporal consistency and semantic alignment. The integration of LLMs for data augmentation and structure parsing represents a promising avenue for further exploration in the synthesis of multimodal content.
Potential future developments could explore the model's application to speech synthesis tasks, support for real-time audio generation, and incorporation into interactive AI applications, thus expanding the model's utility and accessibility across diverse domains.
In summary, Make-An-Audio 2 stands out as a robust synthesis model that effectively bridges gaps in temporal audio-text alignment, setting a new standard for future research in T2A systems.
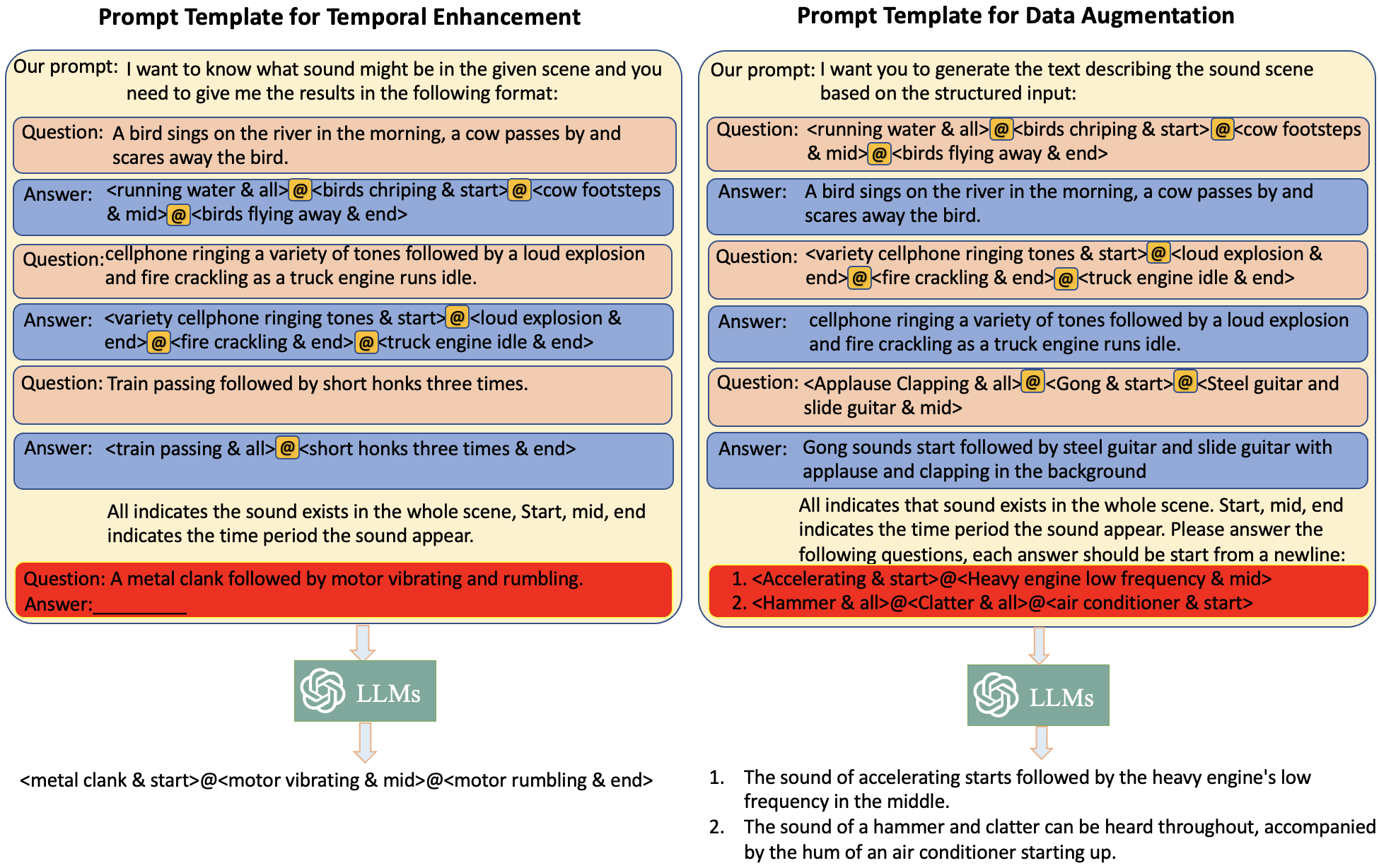
Figure 3: The prompt templates we used for temporal enhancement and data augmentation. We use the symbol '{additional_guidance}' to split the sound event and the time order. We use the symbol '@' to split <event {additional_guidance} order> pairs.