- The paper's main contribution is the development of EzAudio, a novel text-to-audio synthesis framework integrating latent diffusion and transformer architectures to enhance both audio quality and computational efficiency.
- The methodology employs innovative techniques like AdaLN-SOLA, long-skip connections, and a three-stage training strategy including masked diffusion modeling and synthetic caption data.
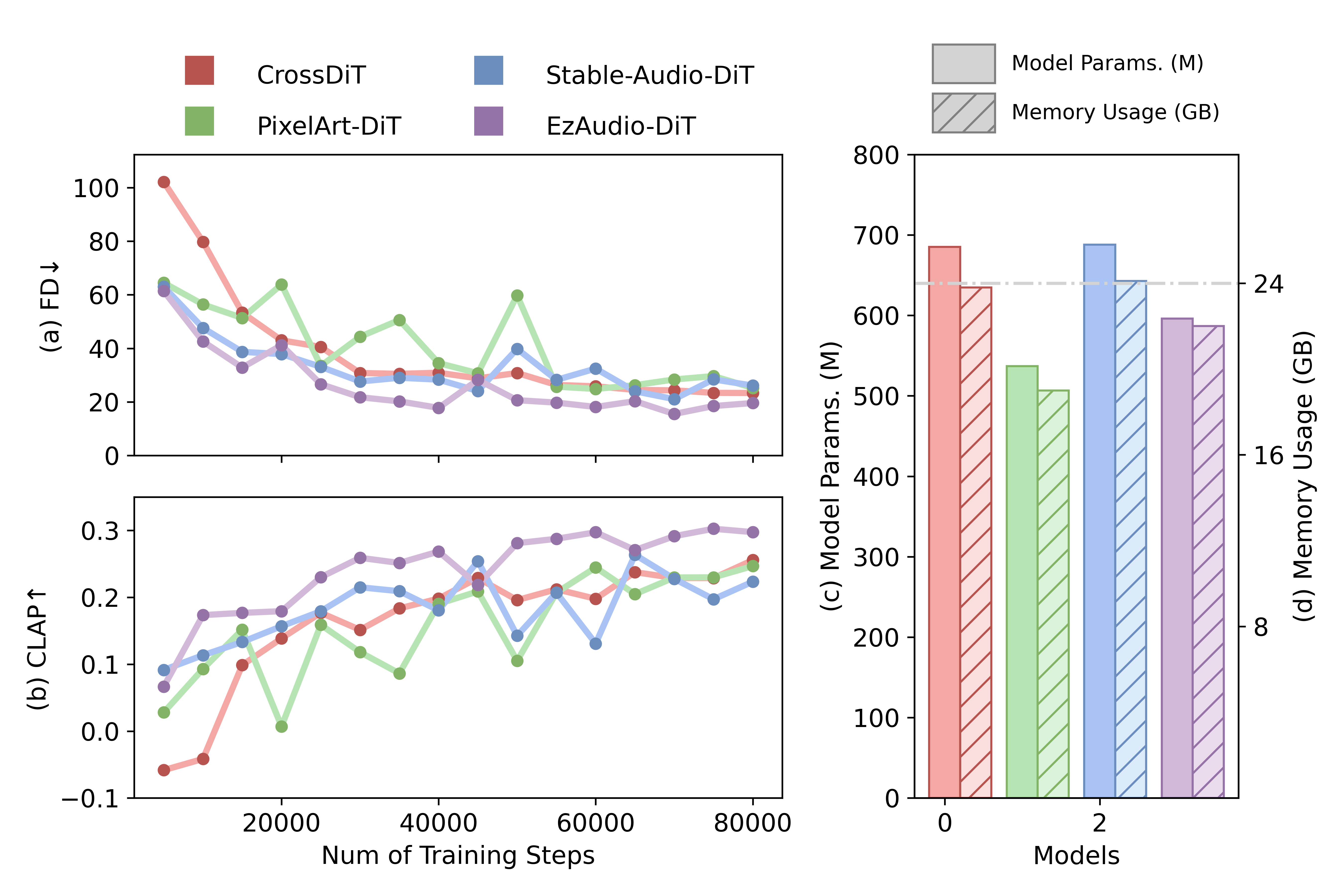
- Experimental results using metrics such as FD, KL divergence, IS, and CLAP scores demonstrate that EzAudio outperforms existing models with superior text-prompt alignment and realistic audio generation.
A Technical Analysis of "EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer" (2409.10819)
Introduction
The paper "EzAudio: Enhancing Text-to-Audio Generation with Efficient Diffusion Transformer" investigates the enhancement of text-to-audio (T2A) generation using a diffusion transformer framework. It specifically addresses challenges in generation quality, computational efficiency, and model structure simplification. The authors propose EzAudio, a novel approach integrating latent diffusion models with transformer-based architectures, moving T2A synthesis away from 2D spectrogram representations toward 1D waveform latent embeddings to achieve superior audio generation.
Methodology
Model Architecture
EzAudio innovatively utilizes a latent diffusion model that operates within the latent space of a 1D waveform VAE, eschewing the complexity of 2D spectrograms and neural vocoders. This approach facilitates efficient handling of audio processing tasks, improving convergence speed and reducing memory demands.
Figure 1: The framework of the proposed EzAudio and the architectural details of EzAudio-DiT.
The paper introduces EzAudio-DiT, an optimized diffusion transformer tailored for audio latent representations. Key enhancements include:
Data-Efficient Training Strategy
EzAudio employs a novel training strategy leveraging three stages:
- Masked Diffusion Modeling: Pre-training using masked modeling on large unlabeled audio datasets.
- Synthetic Caption Data: Training on synthetically generated audio captions, improving text-to-audio alignment.
- Fine-tuning: Enhancing model precision with human-labeled audio caption datasets.
Classifier-Free Guidance Rescaling
An innovative rescaling technique is proposed to refine the classifier-free guidance (CFG) process, ensuring robust prompt alignment without compromising audio fidelity, even at high CFG scores.
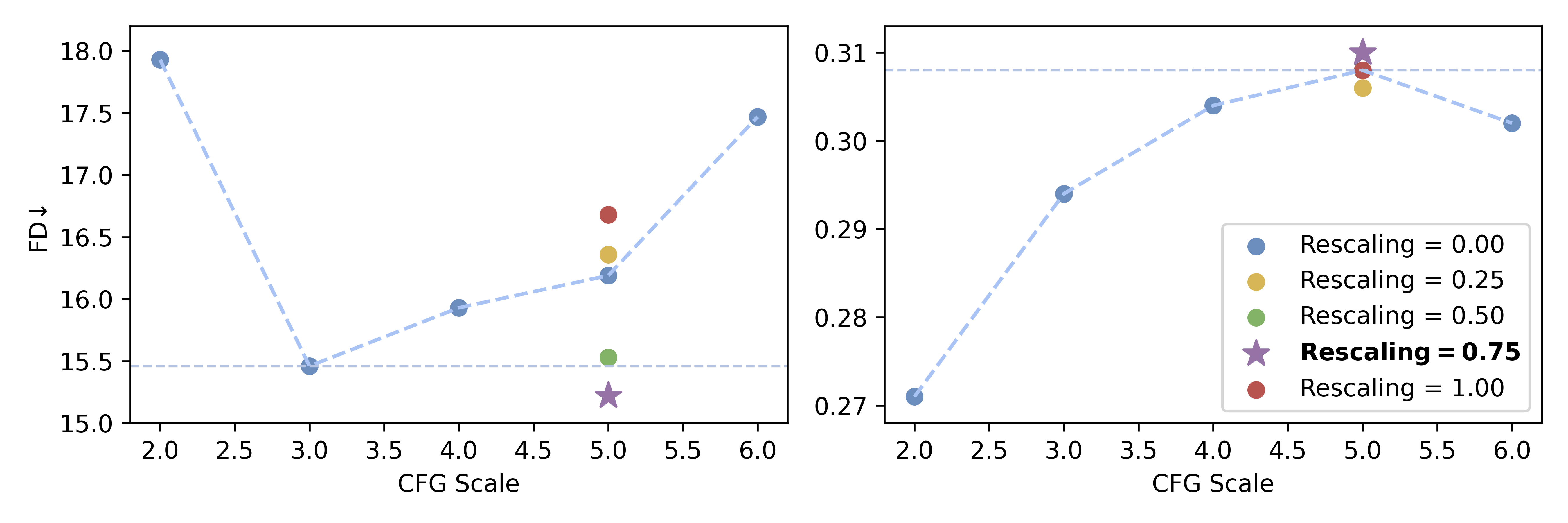
Figure 3: FD and CLAP scores across CFG scales and rescaling factors.
Experiments and Results
Comprehensive experiments demonstrate EzAudio's effectiveness. Using metrics like Frechet Distance (FD), KL divergence, Inception Score (IS), and CLAP scores, EzAudio consistently outperforms existing T2A models such as Tango and Make-An-Audio, delivering superior text-prompt alignment and audio quality. Subjective evaluations further corroborate these findings, positioning EzAudio as a leading framework in T2A synthesis.
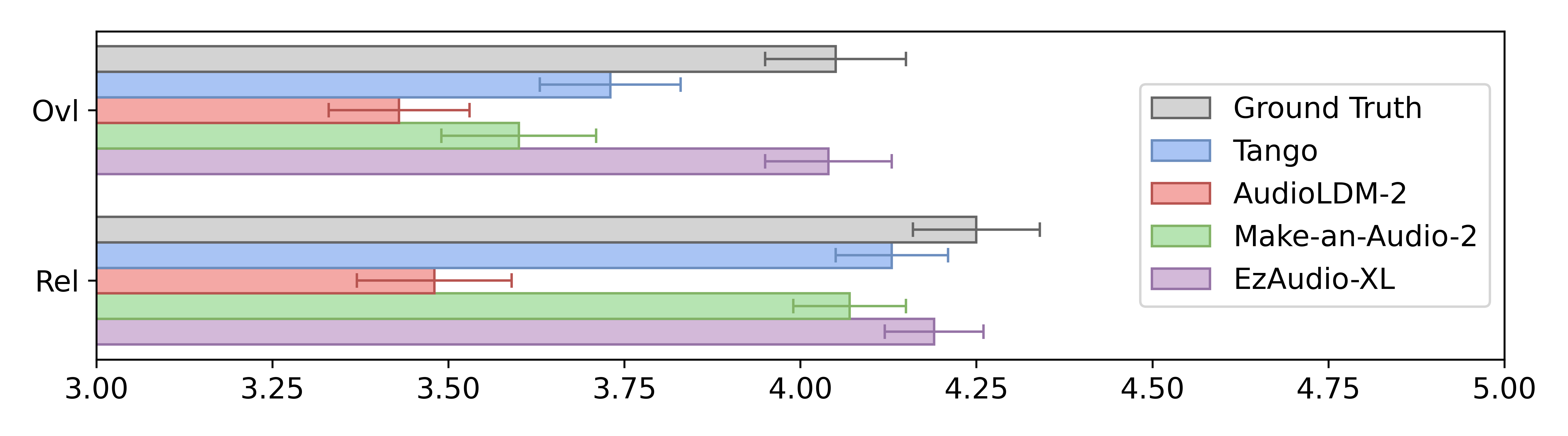
Figure 4: Mean subjective scores with 95% confidence intervals.
Conclusion
EzAudio sets a new benchmark in T2A generation by integrating a diffusion transformer design with innovative architectural improvements and training strategies. Its ability to deliver high-quality, realistic audio with efficient computational requirements makes it a valuable contribution to audio synthesis research. Future work may explore its applications in video-to-audio synthesis, leveraging ControlNet and DreamBooth advancements for even broader and more innovative uses in audio-generative tasks.