- The paper demonstrates that Codex fixed an average of 10.2 Java vulnerabilities, outperforming other LLMs in automated security repair.
- It utilizes dual benchmarks, Vul4J and VJBench (with transformations), to assess model performance and mitigate data contamination.
- Fine-tuning LLMs with APR data enhances repair capabilities, yet complex vulnerabilities remain challenging for current neural network approaches.
How Effective Are Neural Networks for Fixing Security Vulnerabilities
Introduction
The paper "How Effective Are Neural Networks for Fixing Security Vulnerabilities" examines the application of neural networks, specifically LLMs and deep learning (DL)-based automated program repair (APR) techniques, to fix security vulnerabilities in Java programs. This study evaluates various pre-trained LLMs and APR methods on real-world Java vulnerability benchmarks. The authors explored two primary benchmarks: Vul4J and a newly created benchmark, VJBench, to assess the performance of these models, as well as introduced transformed versions of these benchmarks to address potential data contamination in model training.
Benchmarks and Methodology
The paper focuses on developing and utilizing comprehensive benchmarks to aid in evaluating Java vulnerability repair capabilities. Two primary benchmarks were analyzed:
- Vul4J: A dataset of 79 reproducible Java vulnerabilities covering 25 CWE types, making it pertinent for evaluating existing APR mechanisms.
- VJBench: A new benchmark introduced by the authors, consisting of 42 real-world Java vulnerabilities spanning 23 CWE types, including 12 not covered by Vul4J.
To mitigate the risk of training-test data contamination, VJBench-trans was created by applying code transformations such as identifier renaming and code structure changes to the existing benchmark datasets.
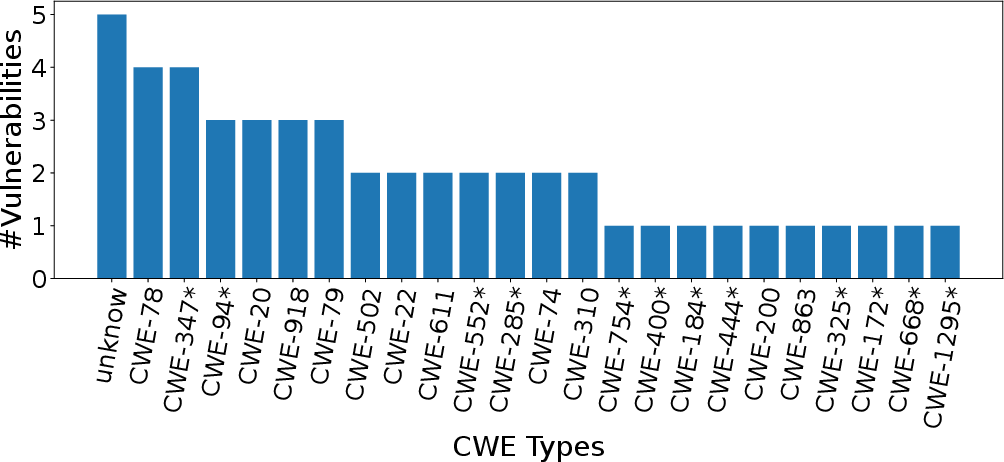
Figure 1: CWE Type Distribution of VJBench (
denotes the new CWE types not included in Vul4J).*
LLMs and APR Techniques
Various LLMs and APR techniques were evaluated:
- LLMs Studied: Codex, PLBART, CodeT5, CodeGen, and InCoder. These models are assessed in their original form and after fine-tuning with general APR data.
- APR Techniques: CURE, Recoder, RewardRepair, and KNOD.
The evaluation focused on fixing capabilities, measuring both correct fixes and plausibly fixed vulnerabilities. LLMs were assessed for robustness specifically against potential data leakage and transformations.
Findings and Observations
The study yielded several key findings:
- Fixing Capabilities: Codex demonstrated the highest fixing capabilities among LLMs with an average of 10.2 vulnerabilities fixed, whereas InCoder followed with 5. It was noted that APR methods had limited success with these Java vulnerabilities, highlighting a scope for improvement in both areas.
- Fine-Tuning Benefits: LLMs fine-tuned with APR data showed enhanced capacities, indicating that such tuning can adapt models for the specific task of vulnerability repair, despite a lack of specialized vulnerability datasets.
- Vulnerability Complexity: Codex was unique in fixing vulnerabilities that required complex repairs beyond simple deletions or variable changes. Most models, without extensive context or domain-specific guidance, faltered with more complex fixes.
- Data Transformation and Generalization: The study confirmed that transformations like identifier renaming could reduce model performance by obfuscating cues leveraged during training. Nonetheless, some transformed vulnerabilities were easier to fix, pointing toward possible simplifications aiding repair.
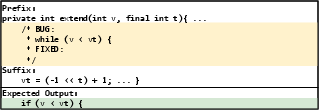
Figure 2: An example input to Codex and its expected output.
Implementation and Further Research
Practitioners wishing to implement these findings can utilize the study's open datasets and evaluation scripts, which provide a framework for continued exploration. Additionally, researchers are encouraged to develop enhanced LLM fine-tuning methods and to construct larger, context-rich vulnerability datasets. Moreover, the promising direction of utilizing code transformations to ease repair tasks merits further investigation.
Conclusion
The research underscores both the potential and the limitations of current neural network-based techniques for repairing software vulnerabilities. While LLMs like Codex show considerable promise, there is a significant need for advancement in training data quality and model robustness. Future efforts should focus on leveraging domain-specific knowledge, refining fine-tuning processes, and exploring innovative strategies like code transformations to enhance automated repair efficacy.