- The paper demonstrates that combining hard prompts and soft prompt tuning enables effective detection of online policy violations with minimal supervision.
- It details an approach utilizing large pre-trained models, significantly reducing the need for extensive labeled datasets while achieving high AUC and accuracy.
- The research reveals nuanced model behaviors, highlighting potential improvements for scalable, efficient content moderation systems.
Using Foundation Models to Detect Policy Violations with Minimal Supervision
The paper "Using Foundation Models to Detect Policy Violations with Minimal Supervision" (2306.06234) explores the application of foundation models for identifying policy violations without significant human supervision. By leveraging large pre-trained neural networks, the authors propose a framework combining hard and soft prompting techniques to effectively classify policy violations such as toxicity in online comments. This essay provides a comprehensive analysis of the methodologies, experiments, and implications discussed in the paper.
Foundation Models and Prompting Techniques
Foundation models, exemplified by LLMs such as GPT-3, have become instrumental in natural language processing tasks due to their ability to perform a wide range of language understanding and generation tasks. The paper capitalizes on two specific strategies: hard prompting and soft prompt tuning. Hard prompting involves designing specific textual prompts to coax the model into providing desired outputs, while soft prompt tuning subtly adjusts the model with minimal data inputs through specialized prefixed tokens.
In this research, the authors develop a hard prompt tailored to policy violation detection, notably in the context of online toxicity. This prompt allows for dual modes of response: generative in natural language explanations and extractive concerning keywords. The inclusion of extractive explanations, consisting of 'Keywords' and 'Citations', refines the model's interpretative capabilities.
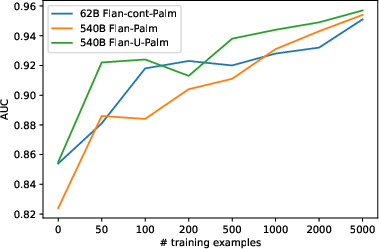
Figure 1: AUC for different training examples sizes, for three different models. 0 indicates no prompt tuning.
Soft Prompt Tuning and Experimental Insights
Soft prompt tuning stands out as a parameter-efficient method, enabling the adaptation of the foundation model to specific tasks with a limited dataset. Unlike traditional fine-tuning, where model weights are updated, this approach adjusts a few additional embeddings, maintaining the model's original parameters unchanged. The study utilizes finely tuned prompts over datasets ranging from 50 to 5000 samples, demonstrating significant performance improvements, notably with minimal data.
The experiments conducted across various models, particularly the 62B FLAN-cont-PaLM and 540B FLAN-PaLM, exhibit high accuracy and Area Under the Curve (AUC) improvements, illustrating the effectiveness of combining hard and soft prompts. Results show substantial classifier performance with surprisingly few labeled data points, indicating the efficiency and feasibility of deploying large models for nuanced tasks with constrained resources.

Figure 2: Balanced accuracy for different training examples sizes, for three different models. 0 indicates no prompt tuning.
Ablation Studies and Observations
The paper conducts several ablation studies to validate the design choices of the proposed prompting methods. These experiments underscore the importance of various components of the prompts, such as XML-like tagging for structural integrity and the inclusion of guideline explanations for context.
Moreover, the authors report intriguing behaviors of foundation models, such as the impact of example extremities on prediction tendencies. Adding examples from extreme cases tends to diminish the detection of neutral or less severe cases, demonstrating a behavior analogous to human exemplar learning. This observation highlights the model’s ability to derive nuanced understandings from the few examples provided.
Implications and Future Directions
The findings of this work present practical implications for content moderation and automated compliance systems. By minimizing the reliance on extensive human labeling and leveraging foundation models’ capabilities, product teams can rapidly deploy policy violation detectors that are adaptive to new or altered guidelines with minimal intervention.
This research opens avenues for further exploration into the resilience and robustness of foundation models against adversarial inputs. Additionally, expanding this approach to a multilingual context could significantly enhance the versatility and applicability of such models in global settings.
Conclusion
"Using Foundation Models to Detect Policy Violations with Minimal Supervision" provides a compelling exploration into employing advanced LLMs for online policy adherence checks. By ingeniously combining hard and soft prompting strategies, the authors demonstrate the viability of using large pre-trained models to achieve high levels of performance with limited labeled data. This approach offers a promising pathway for developing efficient, scalable, and intelligent content moderation systems.