- The paper introduces a comprehensive categorization of knowledge distillation techniques, detailing response-based, feature-based, and relation-based methods.
- It examines offline, online, and self-KD schemes, highlighting trade-offs in computational complexity and performance gaps between teacher and student models.
- The paper reviews advanced approaches such as multi-teacher and cross-modal distillation, offering actionable insights for designing efficient neural networks.
Categories of Response-Based, Feature-Based, and Relation-Based Knowledge Distillation
This essay provides an exhaustive analysis of the paper titled "Categories of Response-Based, Feature-Based, and Relation-Based Knowledge Distillation" (2306.10687), which explores various knowledge distillation (KD) techniques. KD techniques are crucial in training efficient and lightweight deep neural networks by transferring knowledge from one network (teacher) to another (student). The paper investigates multiple dimensions of KD, offering insights into different methodologies and their advancements.
Response-Based Knowledge Distillation
Response-based KD primarily focuses on the alignment of the final output of the student network with that of the teacher. The essence is in transferring the probability distributions from the teacher to the student using techniques like softened softmax. This approach is particularly versatile, as it is outcome-driven and easily extendable to various tasks. The key challenge, as highlighted in the paper, is narrowing the performance gap due to the inherent capacity difference between the teacher and student networks.
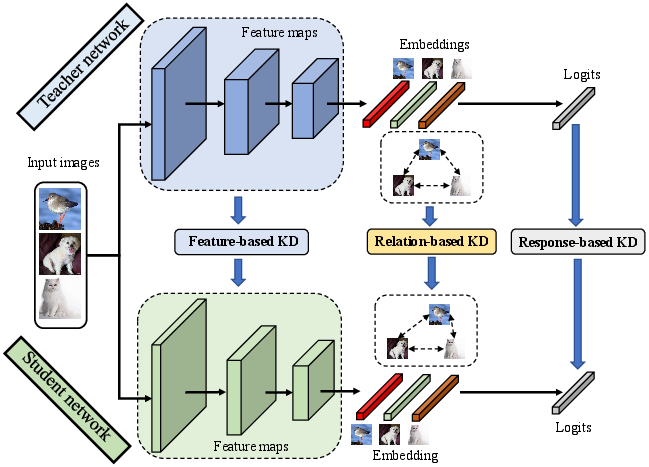
Figure 1: The schematic illustration of response-based, feature-based, and relation-based offline KD between teacher and student networks.
Advancements like the transitional use of teacher assistants (TAKD) and adaptive distillation strategies like ATKD, which uses sample-wise adaptive temperatures, aim to address this discrepancy. Nonetheless, the method predominantly relies on the endpoint outcomes, which can lead to loss of valuable intermediate knowledge.
Feature-Based Knowledge Distillation
Feature-based KD addresses the gaps in response-based methods by leveraging intermediate feature information. As opposed to only the final probabilities, this method encourages the student to learn meaningful representations throughout the network layers. Techniques like FitNet and attention transfer (AT) have been seminal in this domain, focusing on minimizing discrepancy at various layers through metrics like Mean Squared Error.
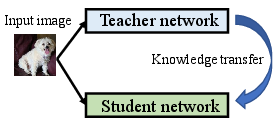
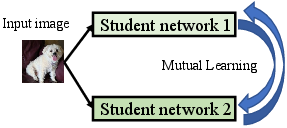
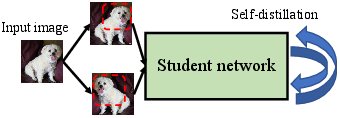
Figure 2: The schematic illustrations of three KD schemes. (a) Offline KD performs unidirectional knowledge transfer from a teacher network to a student network. (b) Online KD conducts mutual learning between two peer student networks. (c) Self-KD creates two input views and regularizes similar outputs over a single student network.
Recent efforts, such as TOFD and HSAKD, further enhance performance by leveraging auxiliary tasks and classifiers to enrich the knowledge received by a student from features across different network layers, promoting a more profound mimicking of the teacher's capabilities.
Relation-Based Knowledge Distillation
Relation-based KD introduces a paradigm shift by exploring inter-sample or inter-layer relationships as sources of knowledge. Instead of isolated data points, it focuses on the connections and relational structures within the data or across neural layers. Such approaches include RKD, which utilizes geometric relationships, and CRD, which leverages contrastive learning methods to enhance representation learning.
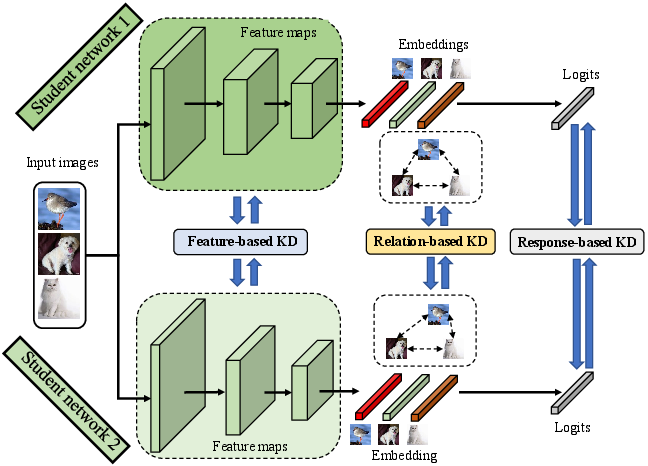
Figure 3: The schematic illustration of online KD. Compared with offline KD, online KD conducts bidirectional knowledge transfer among two student networks.
These techniques offer a distinct advantage in modeling complex dependencies inherent in natural data, providing a comprehensive supervisory approach. However, these methods often encounter complexity in consistently modeling these relationships accurately and effectively.
Distillation Schemes
The paper classifies KD techniques into three main categories: offline KD, online KD, and self-KD.
Offline Knowledge Distillation
Offline KD uses pre-trained models, primarily focusing on transferring established knowledge to a student network without further training of the teacher. It serves well where pre-trained models are available and minimizes training complexity. However, the rigidity of only using a static teacher model can be a limitation.
Online Knowledge Distillation
Online KD transforms the learning process to be more dynamic, embracing an ensemble of student models that collaboratively learn and improve each other through mutual adaptation. It eliminates reliance on pre-trained models but increases overall training time and complexity.
Self-Knowledge Distillation
Self-KD is unique in its approach where a network learns from its iterations or augmented data to refine its performance continually. It supports resource-constrained setups by avoiding the need for separate teacher models, fostering internal consistency and self-improvement.
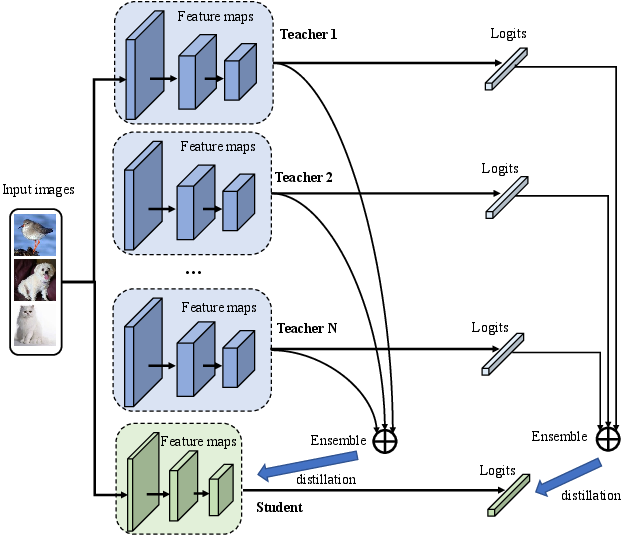
Figure 4: The schematic illustration of multi-teacher distillation. This framework assembles multiple teachers' feature maps and logits to distill a single student network.
Distillation Algorithms
Multi-Teacher Distillation
Multi-teacher KD expands the knowledge base by drawing on multiple pre-trained networks, each offering distinct insights to the student. This technique utilizes the diversity of teachers to create a robust student network, though it demands more computational resources.
Cross-Modal Distillation
Cross-modal KD extends beyond traditional methods, transferring knowledge across different data modalities. It is crucial when labeled data is limited in one modality but abundant in another, offering new avenues for dataset efficacy.
Attention-Based and Adversarial Distillation
These approaches leverage advanced mechanisms (like self-attention and adversarial networks) to refine the distillation process. Attention-based distillation focuses on crucial areas within the data, while adversarial methods increase robustness by challenging the student network through adversarial signals.
Conclusion
The deep dive into response-based, feature-based, and relation-based KD delineates their nuanced application and limitations. The comprehensive survey aids in understanding applications and innovations in improving neural network efficiency and effectiveness. By categorizing KD into diverse schemes and algorithms, the paper lays a robust foundation for future research, emphasizing optimization in computational efficiency and performance enhancement. The future trajectory in KD research promises to explore emerging models like Vision Transformers and integrate self-supervised learning paradigms, continuously adapting to evolving AI landscape challenges and opportunities.