- The paper introduces a novel ToP method that combines layer gate masking and token ranking to prune tokens and enhance transformer efficiency.
- Experimental results demonstrate up to a 12.6x reduction in FLOPs and 7.4x speedup on real CPU tests with less than 1% accuracy drop on GLUE and SQuAD v2.0.
- The ranking distillation process aligns early layer token importance with final outputs, ensuring robust pruning decisions under predefined computational constraints.
Introduction
The paper addresses the challenge of deploying transformer models in resource-constrained environments, particularly focusing on reducing the inference costs associated with these models. By proposing a novel method named Token Pruning (ToP), the paper introduces mechanisms to selectively remove tokens based on their importance, which is dynamically assessed during model inference. This approach aims at improving the inference speed while maintaining the model's accuracy across various downstream tasks.
Methodology
Overview of ToP
ToP deploys a two-tier mechanism that leverages L0 regularization to learn optimal token pruning strategies. This method combines coarse-grained layer gate masking with fine-grained token ranking masks. The decision for token removal is determined dynamically to adhere to a specified computation constraint.
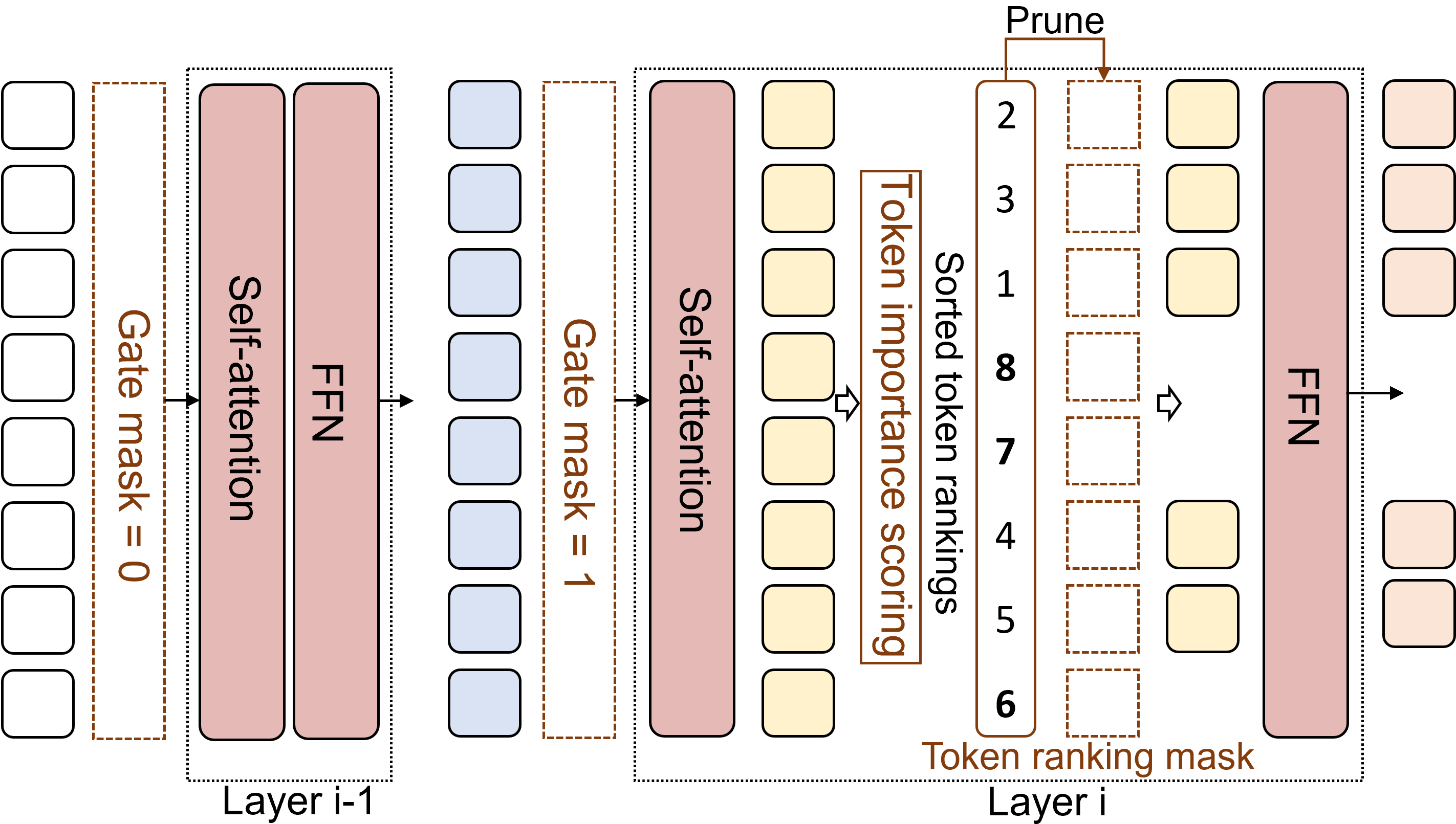
Figure 1: Our approach learns layer gate masks and token ranking masks to prune tokens under a desired constraint. When a layer gate turns off (i.e., mask=0), we skip the current layer. When a layer gate turns on (i.e., mask=1), unimportant tokens are removed after the self-attention mechanism.
Constraint-aware Token Pruning
The model introduces binary mask variables for each layer and token, where gate masks determine whether to conduct pruning, and token masks decide which specific tokens are to be pruned. This approach directly calculates token importance scores using attention mechanisms and uses L0 regularization to optimize masks under a given computational budget.
Ranking Distillation
The weakness of early layer attention scores in predicting token importance is addressed by distilling ranking knowledge from deeper layers to early layers. Ranking-aware token distillation improves early layer ranking abilities by aligning them with the final output's token importance rankings. The LambdaRank loss is employed to minimize differences between teacher and student teacher ranking outputs.
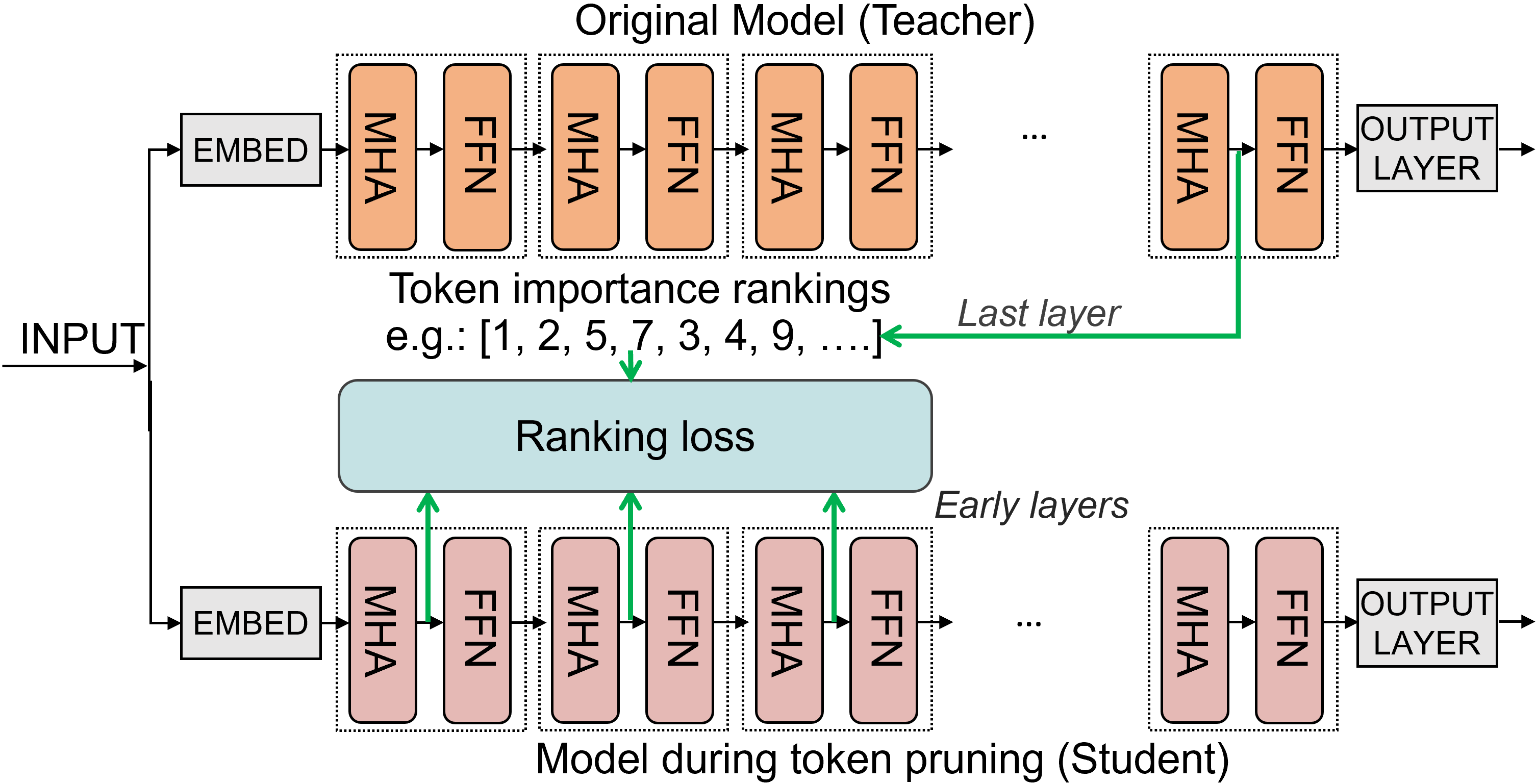
Figure 2: Our ranking-aware token distillation uses importance rankings generated from the unpruned model's final layer and distill it to early layers during the training.
Experiments and Results
ToP was tested on the GLUE benchmark and SQuAD v2.0 datasets, demonstrating significant improvements in inference speed without sacrificing accuracy. The method achieved up to a 12.6x reduction in FLOPs for BERT models with less than 1% accuracy drop, outperforming existing methods like PoWER-BERT and Transkimmer.
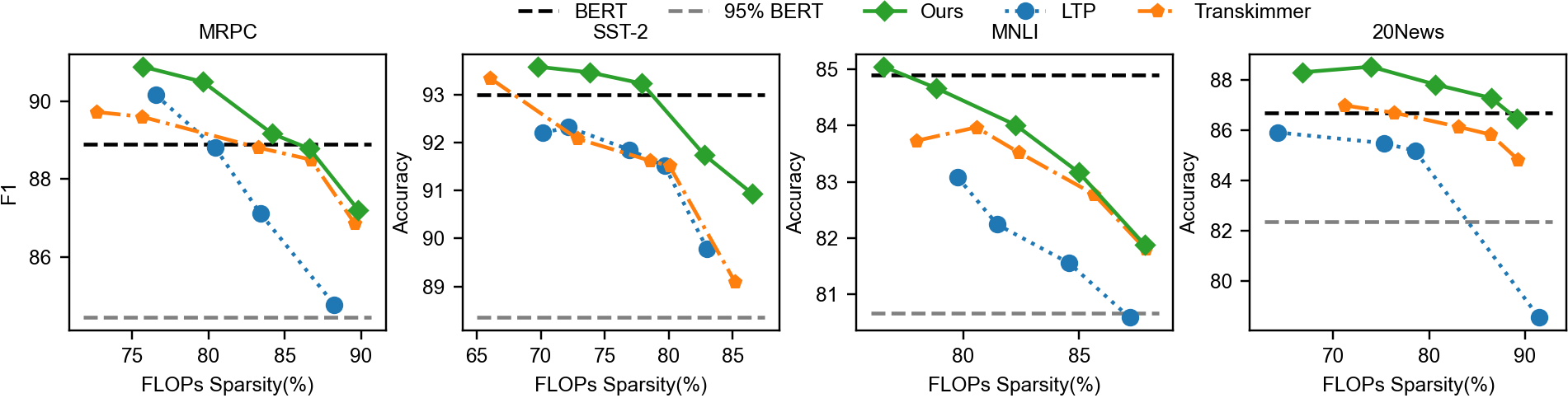
Figure 3: Comparison of token pruning methods under various FLOPs sparsity ratios.
Real-world Implications and Future Work
The results confirm the potential of ToP for real-time applications, offering reduced latency in CPU-bound environments, notably achieving up to a 7.4x real-world speedup on an Intel CPU. Future work might enhance GPU-supported implementations, optimizing memory operations like token removal to leverage high-performance computation environments better.
Conclusion
The study develops a robust strategy for effective token pruning in transform inference, achieving meaningful acceleration in computation without undermining accuracy. By using a multi-faceted approach involving L0 regularization and ranking-aware distillation, the paper provides a significant step forward in deploying transformer models efficiently in resource-constrained environments. The contribution is especially noteworthy given the strong empirical performance and potential to adapt this pruning method across various domains and settings.