- The paper introduces OrthoRank, a novel token selection method that uses sink token orthogonality to reduce redundant computations in LLM inference.
- It dynamically ranks tokens based on cosine similarity with a sink token, enabling selective layer updates and effective pruning.
- Experimental results show OrthoRank achieves lower perplexity and higher zero-shot accuracy on benchmarks like C4 and LongBench.
OrthoRank: Token Selection via Sink Token Orthogonality for Efficient LLM Inference
Introduction
The paper "OrthoRank: Token Selection via Sink Token Orthogonality for Efficient LLM Inference" presents a novel approach aimed at optimizing inference efficiency in LLMs. The primary innovation centers around the concept of an attention sink, which is observed as a phenomenon where initial tokens in a sequence receive disproportionately large attention due to their visibility to subsequent tokens. Building upon this foundation, the paper introduces OrthoRank, a dynamic token selection method that leverages token orthogonality relative to sink tokens to enhance the inference process without additional training.
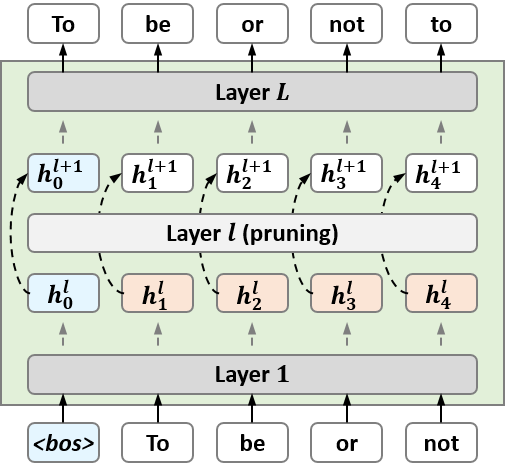
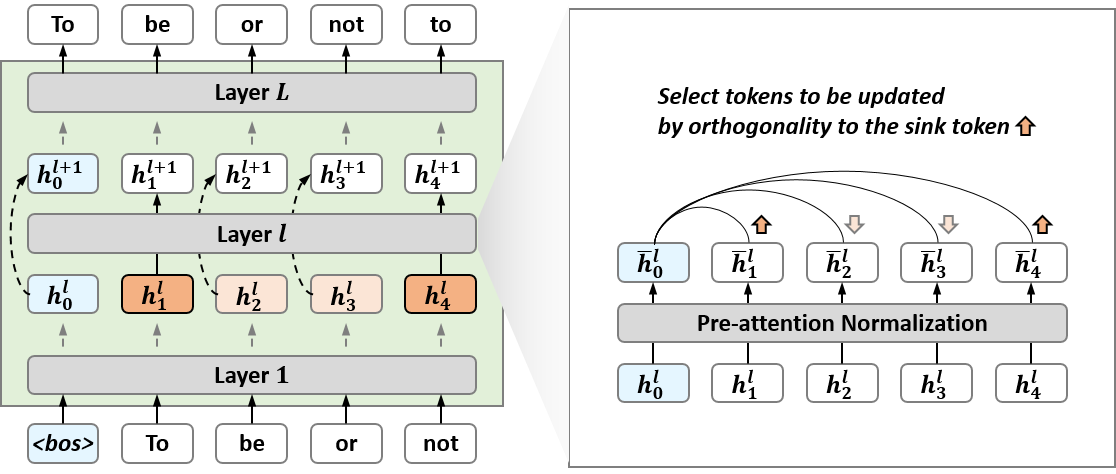
Figure 1: Overview of our approach (OrthoRank). OrthoRank first determines the orthogonality of tokens to the sink token after normalization at each layer. Based on this, the top K tokens are selected for updates, while the remaining tokens bypass the layer except for KV calculations.
Theory and Methodology
The theoretical underpinning of OrthoRank is grounded in the observed behavior of cosine similarity between normalized hidden states of the sink token and other tokens as layers deepen. Specifically, the paper finds that tokens tend to align increasingly with the sink token, suggesting that other tokens convey redundant information as layers progress. OrthoRank capitalizes on this by dynamically determining token importance based on orthogonality to the sink token. This is quantified by the gradient of the cosine similarity, which effectively indicates the speed at which tokens can align with the sink token.
The operational mechanism of OrthoRank involves token selection at each layer while only computing a minimal set of tokens fully, thus maintaining computational efficiency. Token importance is ranked based on their orthogonality to the sink token, with more orthogonal tokens noted as more relevant and hence more deserving of computational resources in subsequent layers (Figure 2).
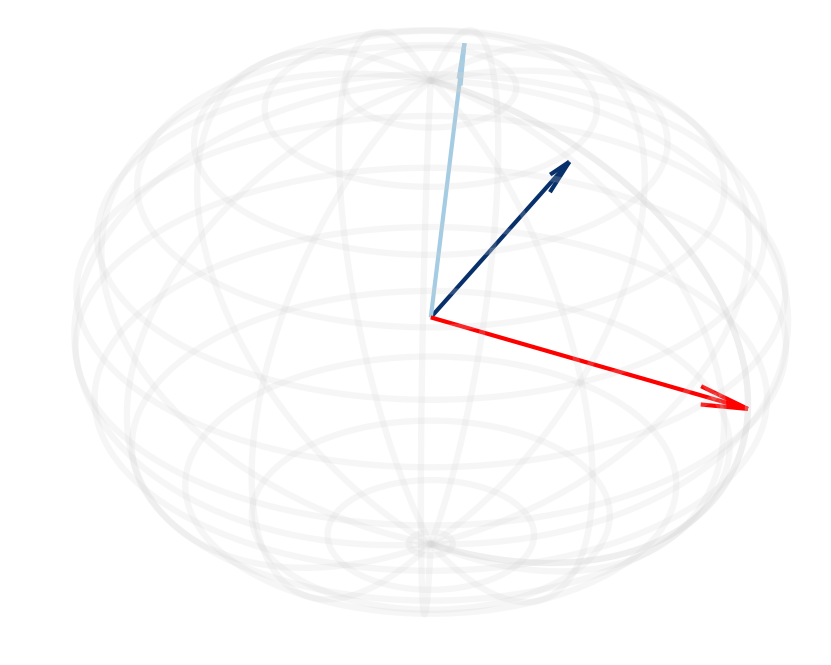
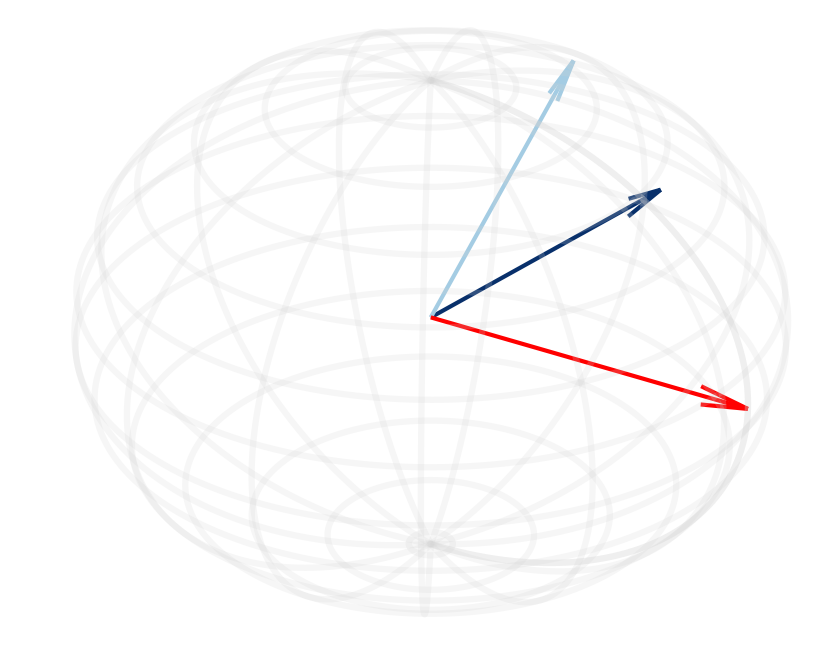
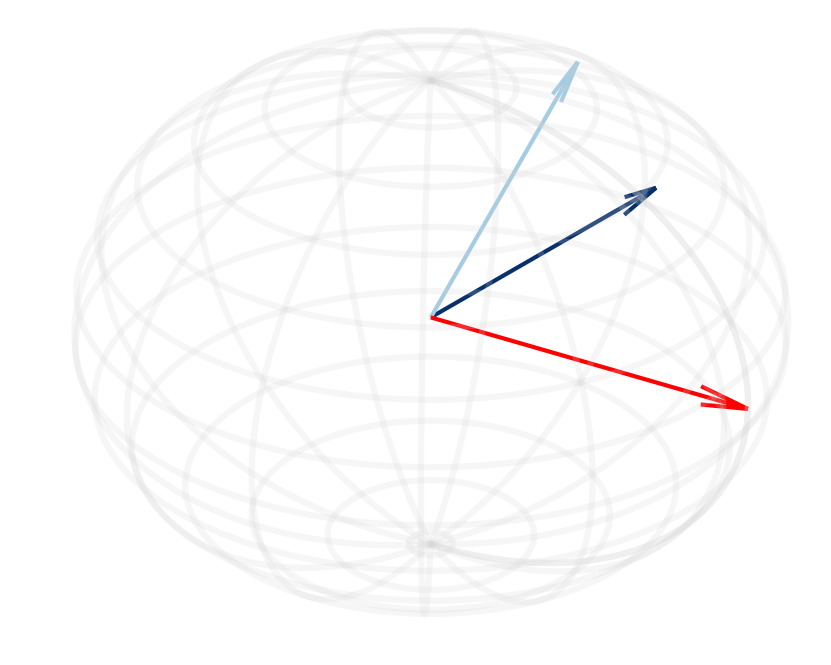
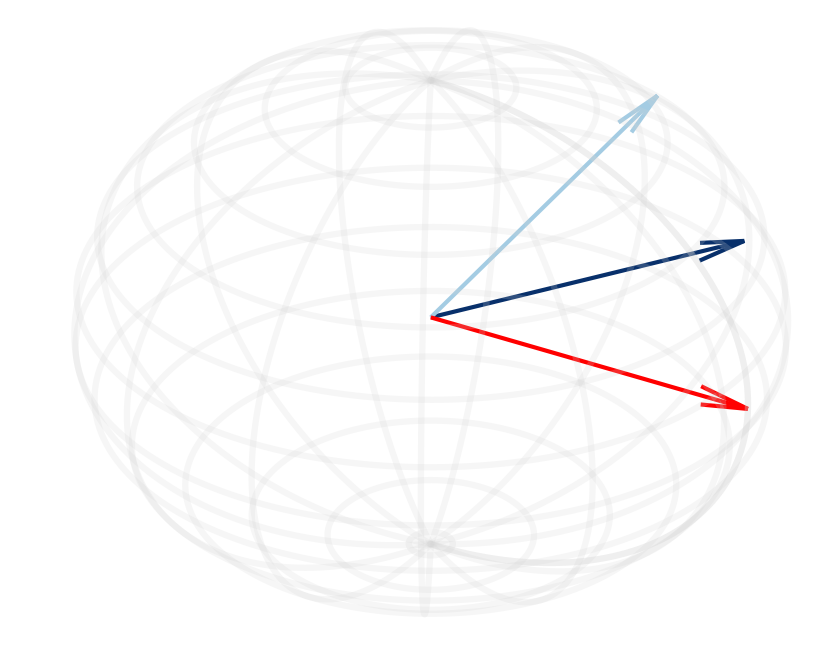
Figure 2: (a, d) Cosine similarity between the normalized hidden states of the sink token and other tokens shows an increase as die layers progress in Llama-2-13B and Mistral-7B models.
Implementation Strategy
Practically, OrthoRank is implemented by evaluating token orthogonality through cosine similarity and operationalizing this via framework integrations such as PyTorch, optimizing for hardware accelerations. The implementation eschews additional model layers or routers, markedly simplifying deployment and enhancing compatibility with existing pretrained LLM architectures. The approach iterates over each token within selected layers, computing the orthogonal score to the sink token and leveraging this to rank tokens by their relevance.
One of the notable computational advantages of OrthoRank is its compatibility with layer-wise pruning strategies, allowing it to be applied selectively across specific layers to achieve optimal trade-offs in computational load and inference speed without sacrificing accuracy or necessitating additional training. The framework can be easily adapted into current LLM deployment pipelines, aligning with established norms for inference optimization in transformer-based models.
Experimental Results
The empirical evaluations demonstrated that OrthoRank consistently outperformed traditional layer pruning methods on benchmarks such as C4 and LongBench. Specifically, it achieved lower perplexity and higher zero-shot accuracy at equivalent sparsity levels, underscoring its effectiveness in real-world settings characterized by stringent latency and throughput requirements (Figure 3).
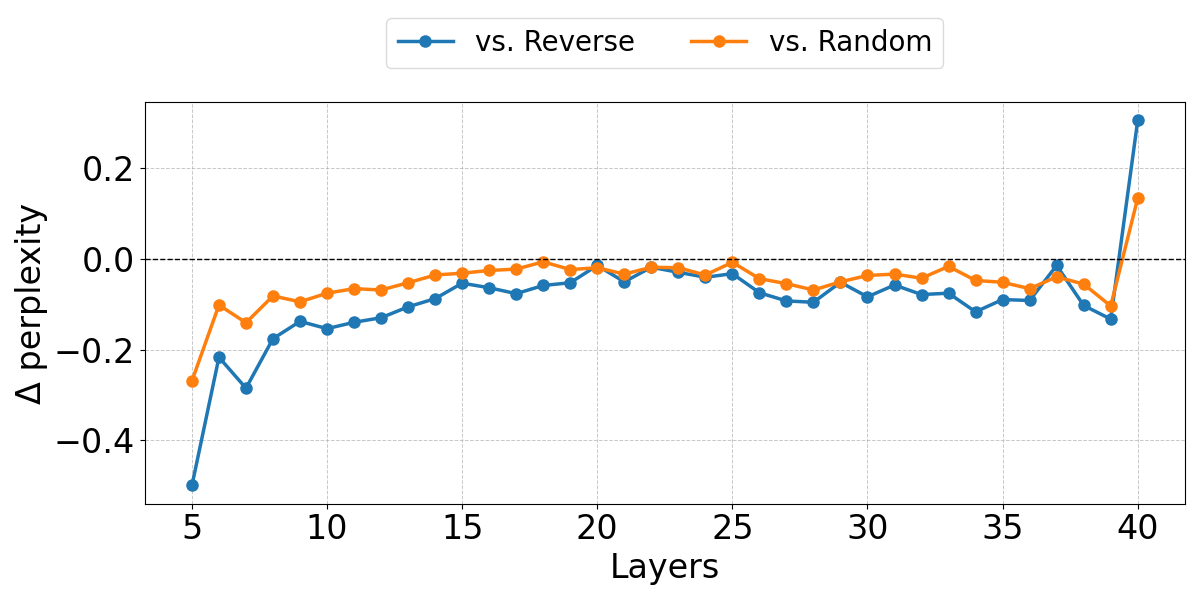
Figure 3: Layer-wise performance by token selection criteria highlights our method achieving lower perplexity across most layers compared to random token selection and the Reverse criteria.
Conclusion
OrthoRank presents a significant contribution to the field of machine learning by optimizing token processing at a micro-level within LLM layers based on orthogonality measures. This reduces unnecessary calculations, preserves model performance, and maintains robust accuracy across tasks. In conclusion, OrthoRank offers a promising framework for efficient LLM deployment, especially in scenarios where computational resources and latency are constraints. The orthogonality-based selection approach paves the way for further research into token dynamics and interactions within transformers, broadening the understanding of their internal mechanisms in ways that improve efficiency and precision.