- The paper introduces a stable sink token that anchors shifting attention sinks in Diffusion Language Models, enhancing model robustness.
- It employs a modified attention mask in the input sequence to absorb excess attention without semantic interference.
- Experimental results demonstrate significant performance improvements, especially in intermediate transformer layers.
Enhancing Diffusion LLMs with a Stable Sink Token
Introduction
The paper "One Token Is Enough: Improving Diffusion LLMs with a Sink Token" (2601.19657) addresses a critical aspect of Diffusion LLMs (DLMs), which are increasingly utilized in parallel text generation. A key challenge in DLMs is the moving sink phenomenon, which destabilizes the inference process by causing erratic shifts in attention sink positions over diffusion timesteps. Unlike autoregressive models, which inherently stabilize attention distribution through their structure, DLMs lack a consistent mechanism to manage attention flow efficiently. This paper proposes a novel solution by introducing a stable sink token to address these instabilities and enhance model performance.
Moving Sink Phenomenon
In DLMs, attention typically drifts towards low-norm tokens, often serving as implicit sinks due to their minimal semantic content. This behavior is visualized in moving attention sinks, indicating shifting attention focus across diffusion steps (Figure 1). The lack of a fixed anchor for attention results in decreased inference robustness, a sharp contrast to autoregressive models where a consistent seed token stabilizes attention distribution.
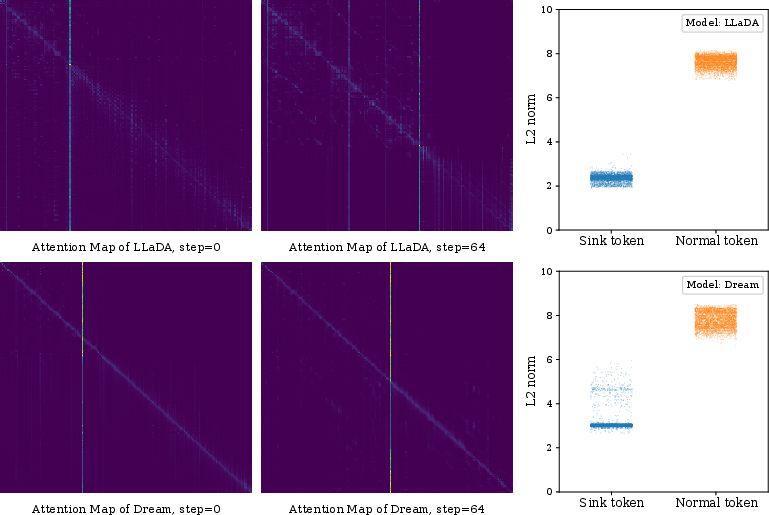
Figure 1: Moving attention sinks and their low-norm property in diffusion LLMs. Attention maps demonstrate shifting sink positions.
Methodology
The authors propose an extra sink token integrated into the input sequence via a modified attention mask. This token is designed to absorb excess attention while maintaining negligible semantic content, acting as a structural anchor. This approach transforms the moving sink into a stable one, as illustrated in the overview of the phenomenon (Figure 2). The paper highlights how this method significantly stabilizes the model without being position-dependent, marking a distinct advantage over variable sink placements.
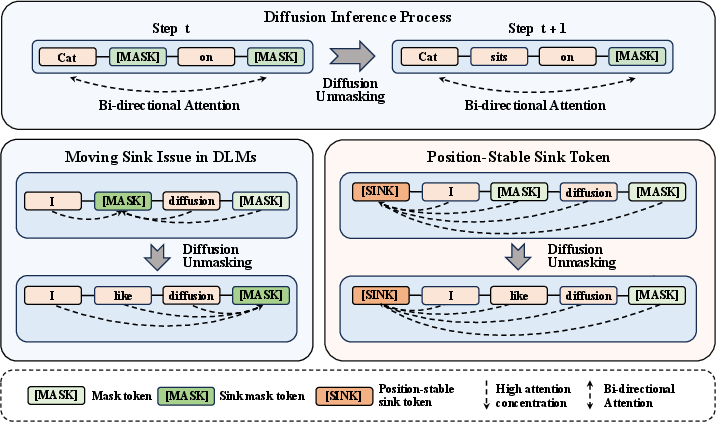
Figure 2: Overview of the moving-sink phenomenon and the implementation of a stable sink token.
Experimental Results
The paper's experiments highlight substantial improvements in DLM performance metrics across various benchmarks, as observed in Tables and evaluations provided. Notably, models equipped with the proposed sink token consistently outperform their vanilla DLM counterparts, affirming the token's added stability and efficiency. These results are particularly pronounced across intermediate transformer layers where the sink token reliably harnesses attention without semantic interference (Figures 3).
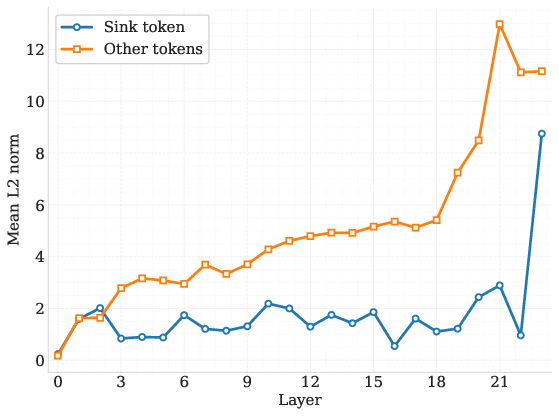
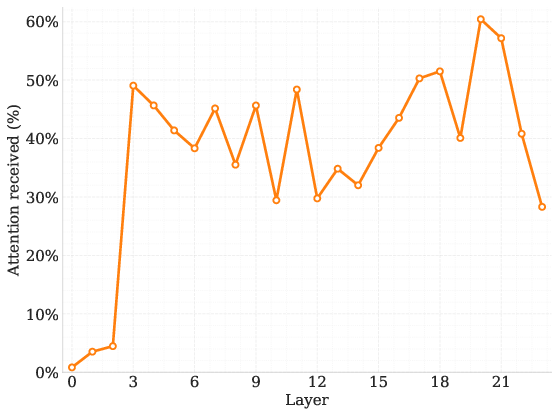
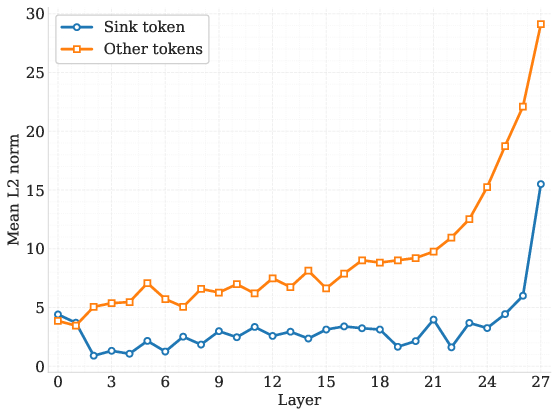
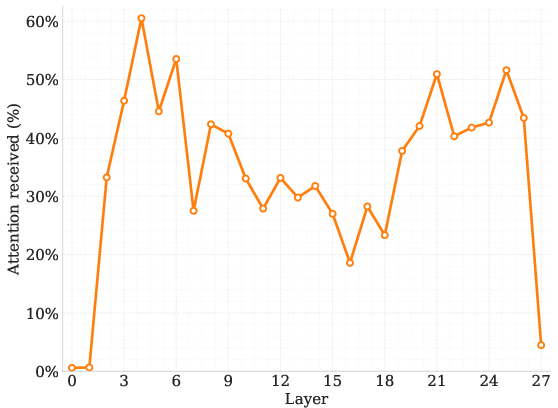
Figure 3: Mean L2 Norm per Layer: Sink vs Others (Model: 0.5B) demonstrating the low-norm characteristic of sink tokens.
Internal Analysis
Further analysis of the DLM architecture reveals that sink tokens naturally attract a significant proportion of attention mass, even when positioned variably within sequences. Trials conducted with zero-vector sink tokens also yield similar performance benefits, corroborating the hypothesis that the key advantage lies in standardizing norm states to mitigate information mixing rather than altering semantic flows.
Conclusion
The introduction of a stable sink token into Diffusion LLMs offers a practical solution for ameliorating attention instabilities inherent in current DLM designs. By ensuring minimal semantic interference and stable attention anchoring, the proposed method enhances model robustness and efficiency. This advancement is poised to inform future DLM developments, ushering in more reliable parallel text generation capabilities.