- The paper introduces outlier-driven rescaling as a unifying mechanism that controls extreme activations via normalization layers in transformer architectures.
- It empirically demonstrates that suppressing outliers degrades performance while explicit methods like GatedNorm yield stable, quantization-friendly training.
- The work reveals that normalization layers play a crucial role in dynamic feature scaling, suggesting architectural innovations to replace brittle emergent phenomena.
Overview
The paper "A Unified View of Attention and Residual Sinks: Outlier-Driven Rescaling is Essential for Transformer Training" (2601.22966) systematically investigates the role of emergent outliers—specifically, attention and residual sinks—in transformer-based LLMs. It posits that these outliers are not simply byproducts or artifacts but serve as functional rescaling mechanisms, enabled through interactions with normalization layers (softmax in attention and RMSNorm in the residual stream). The authors propose the term outlier-driven rescaling to encompass this functionality, and empirically validate its necessity across diverse architectures and regimes. Mechanistic analysis and comprehensive ablations demonstrate that outlier-driven rescaling is indispensable for stable and performant transformer training, but can be replaced with explicit architectural rescaling methods such as gated normalization, which yields more numerically robust and quantization-friendly models.
LLMs display two principal outlier phenomena:
- Attention sinks: Tokens (typically special tokens) that consistently receive substantially higher attention logits than others, leading to disproportionate, but ultimately not dominating, attention scores due to downstream normalization and suppression in value vectors.
- Residual sinks: Fixed dimensions in the residual stream that display persistently large activations across most tokens, regardless of input.
The cross-model analysis (Qwen3-235B-A22B, Qwen3-Next, GPT-OSS, and DeepSeek-V3) reveals both phenomena are widespread and coherent, with residual sinks manifesting as vertical stripes of high activation in visualization, and attention sinks resulting in clearly discernible attention logit outliers.
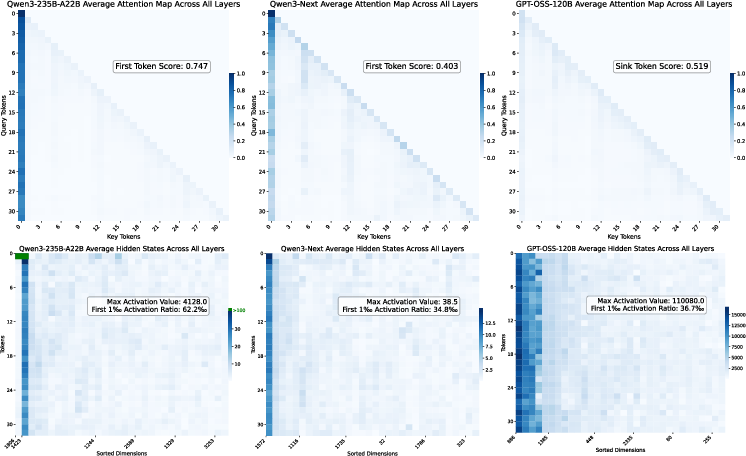
Figure 1: In the first row, all models exhibit varying degrees of attention sinks: the first token produces attention logits significantly larger than those of other tokens, dominating the attention scores. In the second row, Qwen3-235B-A22B shows massive activations, with dimensions 1806 and 1423 of the first token exceeding 1000. Beyond these extreme values, all models display consistent residual sinks: certain fixed dimensions yield persistently higher activations across all tokens compared to others.
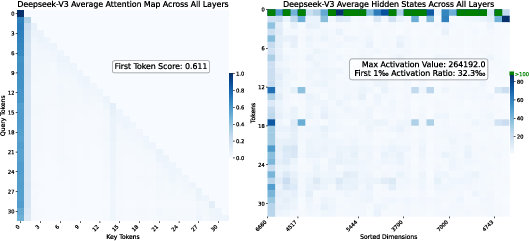
Figure 2: The activation pattern of the <begin of sentence> token is different from other tokens in DeepSeek-V3, with clear evidence of both attention and residual sinks.
The empirical evidence indicates that both attention and residual sinks, while distinctive in source (token-specific vs. dimension-specific), modulate representations by controlling feature norm at their respective normalization layers.
Outlier-Driven Rescaling: Functional Analysis
The study demonstrates that outlier dimensions/tokens do not contribute substantially to downstream computations directly—in value or feature vector magnitude—but instead serve to rescale the remaining dimensions/tokens through their disproportionate impact on normalization denominators. Notably, the suppression of outlier impact in downstream layers (e.g., small affine weights in RMSNorm for outlier dimensions) reinforces that their role is almost purely modulatory.
Fundamental observations include:
- Necessity of normalization: Removing or significantly altering normalization layers (e.g., RMSNorm replaced by pointwise Dynamic Tanh) eliminates outliers but yields highly unstable and suboptimal training dynamics.
- Invariance of downstream contribution: Outlier dimensions exhibit small norm contributions post-normalization, confirming that their function is to dynamically scale the residual rather than encode semantic information.
Ablations and Mitigations: From Outlier Suppression to Explicit Rescaling
Direct removal or suppression of outliers (e.g., via activation clipping or use of bounded activations such as sigmoid-based GLU) consistently results in degraded performance, instability, or even divergence during training. This is true for both attention and residual sinks and confirms that their elimination cannot be naively substituted without architectural adaptation.
Instead, the absorption of outlier functionality into explicit, learnable parameters (PreAffine) or explicit architectural components (GatedNorm) provides a robust and interpretable alternative:
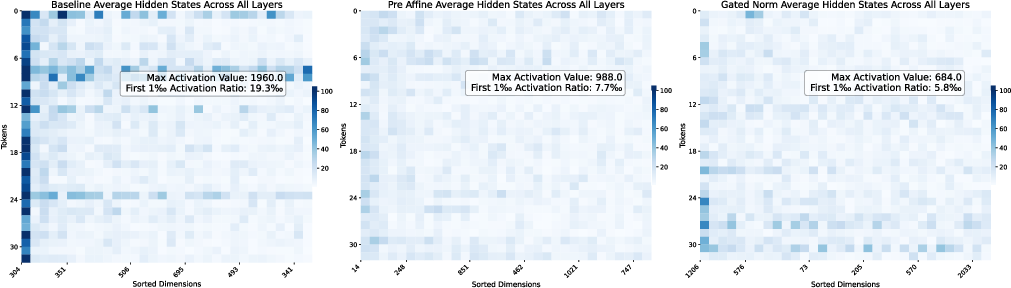
Performance and weight analysis further supports these interpretations: baseline models with residual sinks display tiny RMSNorm weights in the outlier dimensions, PreAffine pushes these deviations to the pre-normalization scaling factors, and GatedNorm yields nearly uniform, unit-norm weights, indicating an absence of residual sinks.
Figure 4: RMSNorm weights for the baseline—note the strong deviation from 1 in outlier dimensions.
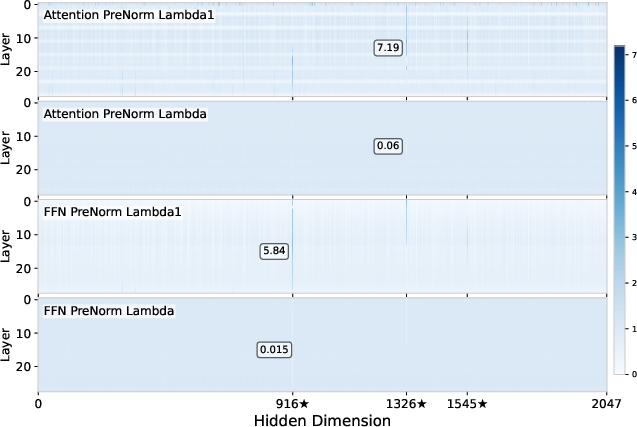
Figure 5: In PreAffineRMSNorm, the magnitude of deviation is moved from RMSNorm weights to the PreAffine scaling parameters.
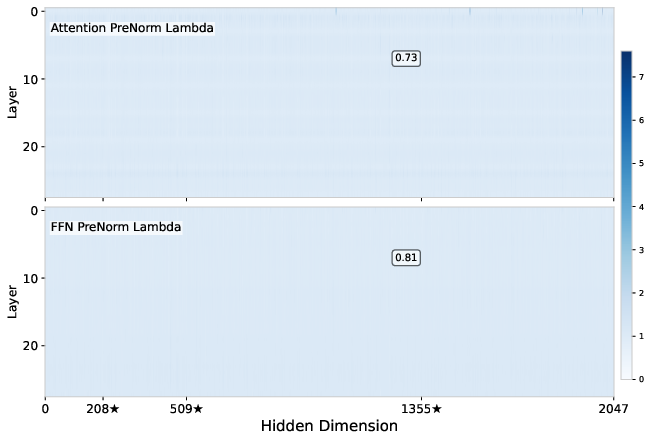
Figure 6: GatedRMSNorm yields weights close to 1 in almost all dimensions, with the largest deviation only 0.73, indicating suppression of residual sinks.
Numerical Results and Quantization Robustness
Strong performance improvements are reported for explicit rescaling architectures:
- GatedNorm yields average performance gains of 2 points in pretraining and maintains quantization robustness under aggressive W4A4 (4-bit weight and activation) quantization, with only 1.2-point degradation, outperforming both PreAffine and baseline methods.
- Explicit rescaling eliminates sharp performance sensitivity to architectural choices: GLU, typically inferior to SwiGLU due to its limited outlier generation, matches or surpasses SwiGLU when augmented with GatedNorm.
These results indicate that, once outlier-driven rescaling is replaced with explicit mechanisms, model performance becomes less sensitive to details of activation nonlinearity or outlier-producing architectural features.
Implications and Future Directions
The findings have several immediate implications:
- Practical: Explicit gating-based rescaling should be considered a standard architectural feature for robust, quantization-friendly transformer models. This is particularly urgent for models deployed in resource-constrained hardware, where numerical instabilities due to outliers are problematic.
- Theoretical: The role of normalization is recast from simple variance control to a functional enabler of dynamic feature scaling—realized through outlier-driven rescaling and now, via gated pathways.
- Architectural robustness: Explicit rescaling reduces reliance on brittle emergent phenomena, increasing model robustness to architectural and hyperparameter choices.
From a broader perspective, these observations suggest that further theoretical work is required to clarify why such rescaling, either via emergent outliers or explicit gates, is essential for efficient representation learning and optimization in overparameterized deep networks.
Conclusion
This work advances a unified framework for understanding the emergence and necessity of outliers in transformer LLMs as instances of outlier-driven rescaling. It demonstrates, via analytic and empirical means, that these outliers interact crucially with normalization to ensure stable and effective training, and that naïvely clipping or suppressing outliers is detrimental. By introducing explicit parameterizations such as PreAffine or GatedNorm, it is possible to eliminate pathological activation outliers and achieve comparable or superior performance and quantization robustness. The insights point to explicit rescaling as a preferred design principle for future robust and scalable LLMs, and motivate further mechanistic investigations into the interplay between normalization, outlier emergence, and deep optimization.