- The paper introduces a training-free, test-time register method that mitigates high-norm tokens in Vision Transformers.
- It leverages a sparse set of register neurons to shift outlier tokens, enhancing attention map clarity across classification, segmentation, and object discovery tasks.
- Experimental results show that this approach maintains or improves performance and robustness, even in multimodal and adversarial settings.
Introduction
The paper "Vision Transformers Don't Need Trained Registers" addresses the formation of high-norm tokens in the internal computation of Vision Transformers (ViTs). These tokens create artifacts in attention maps, affecting downstream visual processing. The traditional method involves retraining models with register tokens to mitigate these artifacts, but this requires starting the training process anew, limiting practical application. The paper proposes a training-free approach, leveraging a sparse set of neurons responsible for outlier formation, referred to as register neurons. By intervening on these neurons during test time, the paper claims models can achieve performance comparable to those with trained registers across various tasks.
Mechanism of High-Norm Tokens
High-norm tokens, or outlier patches, typically emerge after the MLP block within ViTs, such as in OpenCLIP ViT-B/16.
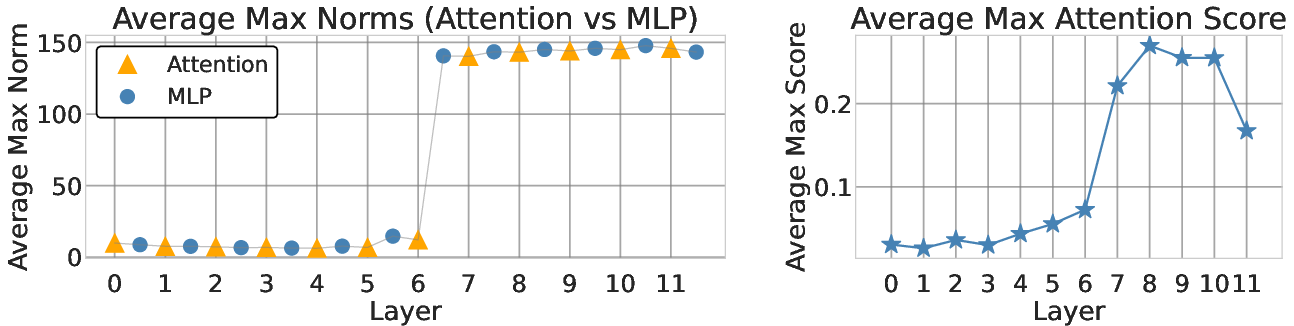
Figure 1: Outlier patches appear after MLPs; attention sinks appear after outlier patches.
A small subset of neurons consistently shows high activations before these outlier patches (Figure 2), indicating their key role in their formation.
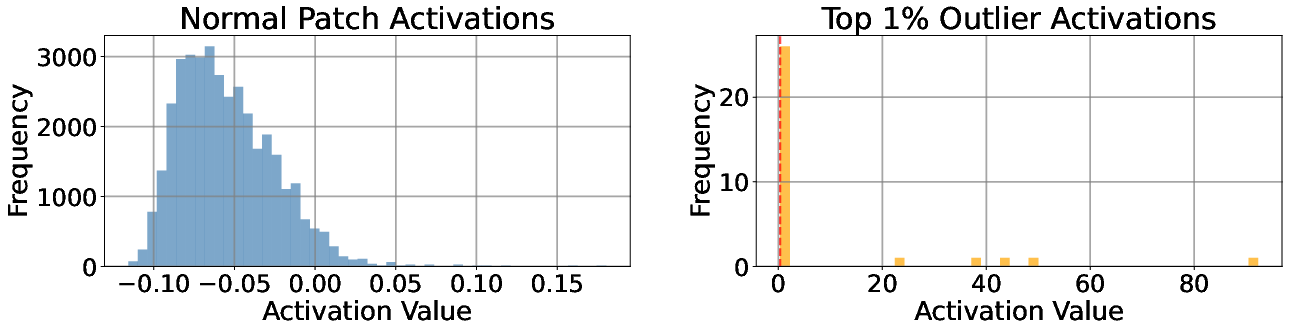
Figure 2: Neuron activation distributions differ between outlier and non-outlier patches.
These neurons, identified as register neurons, activate across various outlier locations, not being position-specific (Figure 3).

Figure 3: Highly activated neurons on the top outlier activate on all outlier positions.
Implementation of Test-Time Registers
By harnessing register neurons, the paper introduces a test-time intervention method to shift outliers to arbitrary positions or to an added test-time register token.
To achieve this, for each register neuron, the highest activation across all tokens is copied to specific positions, and other activations are cleared. This strategy effectively controls the emergence of high-norm tokens and can shift them outside the image area (Figure 4).
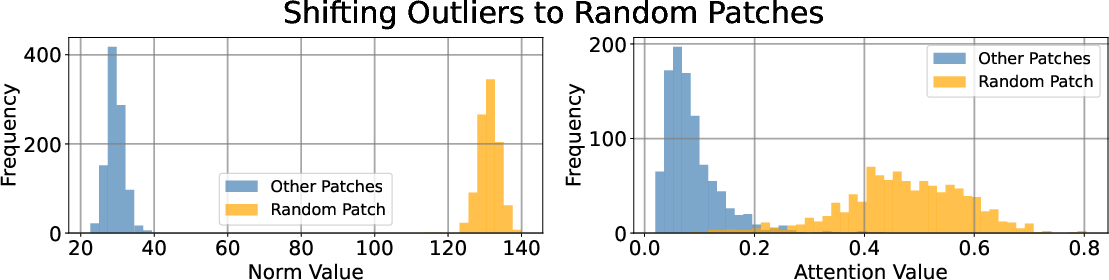
Figure 4: Intervening on activations of register neurons effectively shifts outliers to random patches and test-time registers.
Test-time registers can mimic the behavior of learned registers without needing retraining, absorbing high norms and yielding clean attention maps, as demonstrated in DINOv2 (Figure 5). Test-time registers hold global information, verified by linear probing on various datasets.
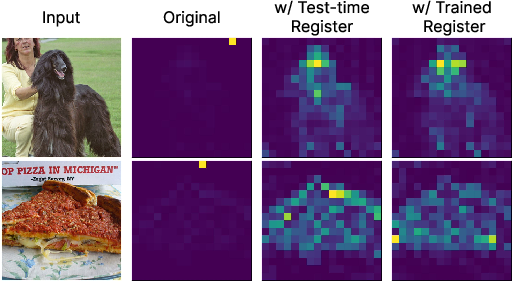
Figure 5: Qualitative results on attention maps w/ test-time registers.
Experimental Evaluation
Classification and Dense Prediction:
Models with test-time registers maintain or improve performance metrics on ImageNet classification, ADE20k segmentation, and NYUv2 depth estimation (Figure 4).
Zero-Shot Segmentation:
Attention maps become more interpretable, with test-time registers boosting mean IOU and mAP in segmentation tasks.
Unsupervised Object Discovery:
Test-time registers significantly improve performance in object discovery tasks by refining attention feature maps.
Application to Vision-LLMs
The paper extends the application of test-time registers to vision-LLMs, such as LLaVA-Llama-3-8B. Here, the introduction of a test-time register enhances interpretability without affecting performance across multimodal benchmarks, mitigating artifacts in cross-modal attention maps (Figure 6).
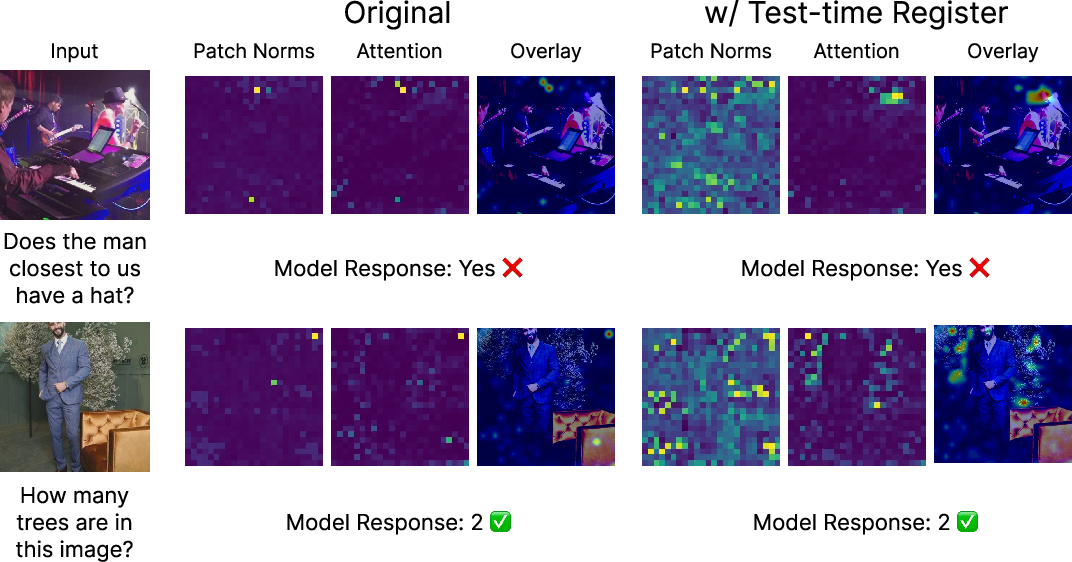
Figure 6: Test-time registers improve interpretability of LLaVA-Llama-3-8B.
Robustness to Typographic Attacks
By focusing high-norm tokens on text locations, test-time registers can mask adversarial text without affecting semantic content. This technique proves effective against typographic attacks, where traditional interventions fail, highlighting its robustness and practical applicability (Figure 7).

Figure 7: Qualitative results on typographic attacks.
Conclusion
The findings suggest that test-time registers offer a viable alternative to trained registers, providing a practical, cost-effective solution to mitigate high-norm artifacts in Vision Transformers without retraining. This methodology not only simplifies deployment in vision models but also maintains interpretability and robustness across various tasks, paving the way for future advancements in AI model architecture and interventions.

