- The paper demonstrates that attention sinks mitigate over-mixing and collapse, preserving robust token representations in deep Transformer networks.
- Empirical validation using models like Gemma 7B and LLaMa 3.1 confirms that focusing on the BoS token reduces perturbation propagation and maintains matrix norms.
- The study reveals that fixed BoS tokens during pre-training are crucial for controlling data packing effects and ensuring overall Transformer stability.
Understanding Attention Sinks in LLMs
Introduction to Attention Sinks
LLMs exhibit an intriguing phenomenon termed "attention sinks," where attention heads frequently concentrate on the first token in a sequence. This paper posits that such attention sinks are not mere artifacts but provide a crucial mechanism for avoiding over-mixing in Transformers. Over-mixing can lead to issues such as rank collapse, representational collapse, and over-squashing, which hinder the effective propagation of information across tokens. The presence of attention sinks helps LLMs maintain robust representations amid perturbations.
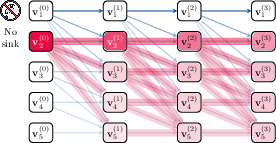
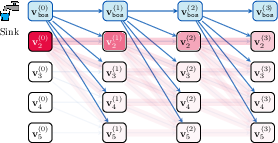
Figure 1: Illustration of attention sinks' utility in robustness against perturbations.
The Role of Attention Sinks
Attention sinks are predominantly observed at the start of sequences, where a token like the Beginning of Sequence (BoS) typically resides. The primary contribution of this paper is to demonstrate that attention sinks help mitigate the negative effects of over-mixing, particularly in deep networks with extensive context lengths. Theoretically, attention sinks slow information mixing, maintaining discrete token representations and avoiding the collapse into uninformative states.
Matrix norms examined in the study show evidence that excessive mixing, if left unchecked, leads to rank and representational collapse, where token vectors converge towards a low-rank space. By concentrating attention on the first token, Transformers can strategically limit the spread of perturbation across the network, effectively acting as an "approximate no-op" for certain computational paths.
Empirical Validation in LLMs
The empirical analysis utilizes the Gemma 7B model to evaluate how attention sinks affect sensitivity to input changes. When the BoS token is present, perturbations in token representations propagate minimally, confirming the theoretical insights.
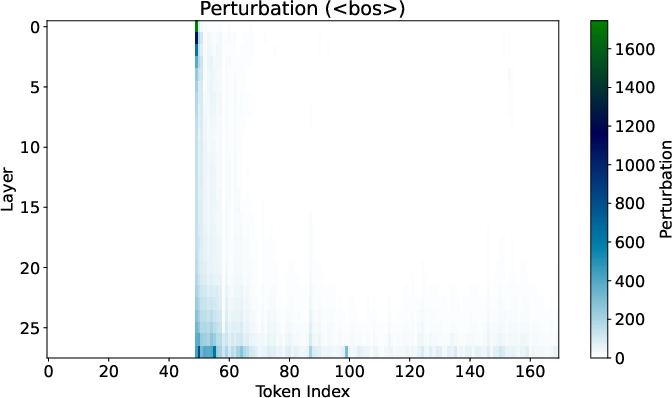
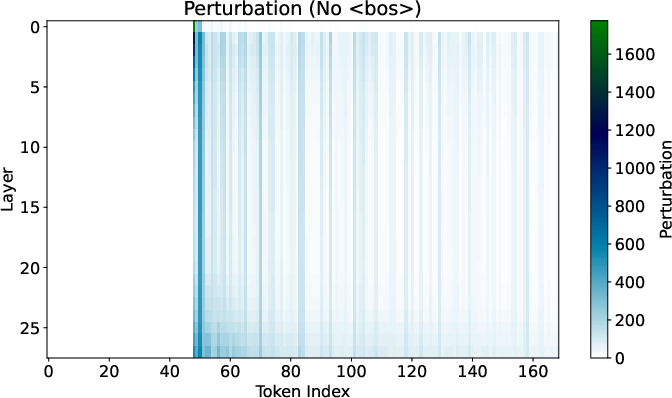
Figure 2: Effects of token perturbations with and without BoS in Gemma 7B.
Attention maps from Gemma 7B reveal smoother distributions and reduced variability when BoS is excluded, evidencing the sink's role in stabilizing the Transformer’s representations.
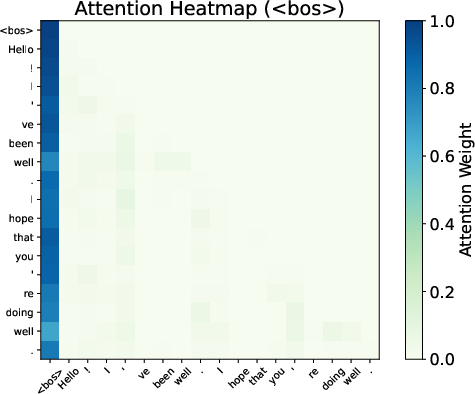
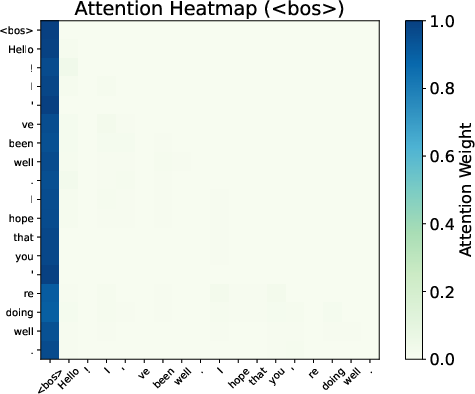
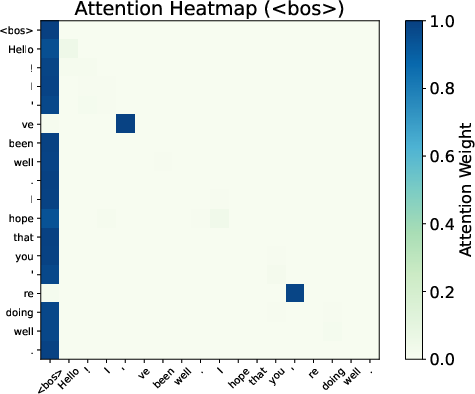
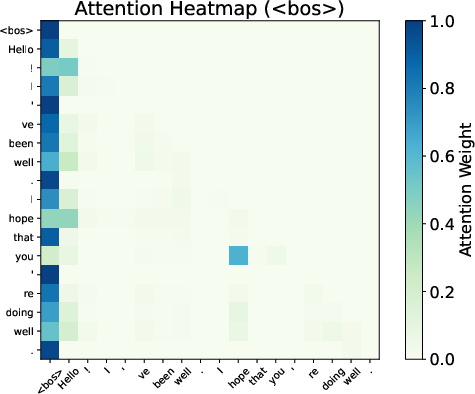
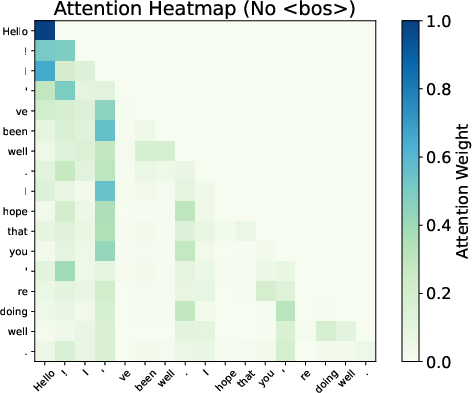
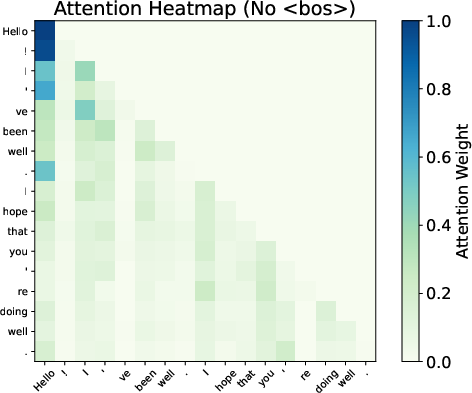
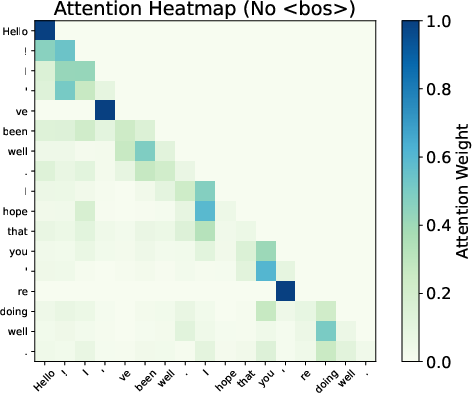
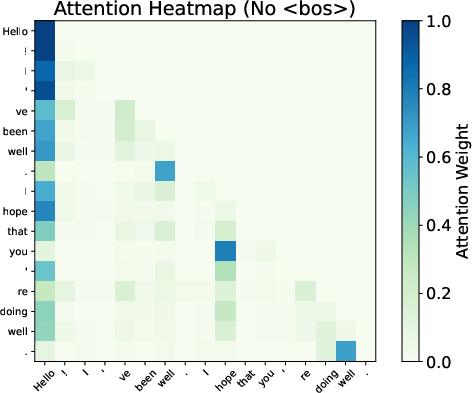
Figure 3: Attention patterns show smoothing effects with and without BoS.
Influence of Model Size and Context Length
Attention sinks are found to be more pronounced in models trained on longer contexts or larger architectures, such as those in the LLaMa 3.1 family. In larger models, with increased depth and head count, the propensity for attention sinks is enhanced, aligning with the hypothesis that they combat over-mixing through concentrated attention.
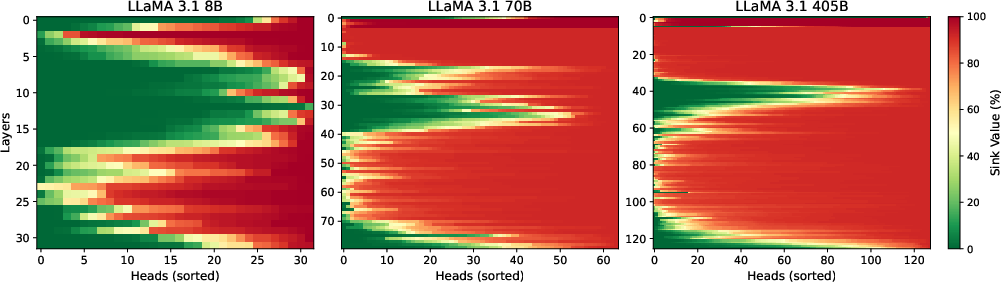
Figure 4: Sink metric percentage across LLaMa 3.1 models, with stronger sinks in larger models.
Data Packing and Attention Sinks
The paper further investigates different data packing strategies to ascertain the role of the BoS token in forming attention sinks. Findings indicate that if the BoS is fixed during pre-training, its removal leads to significant performance drops, underscoring its role in controlling over-mixing (Table: Impact of data packing and attention masking).
Conclusion
This work provides a comprehensive exploration of attention sinks in LLMs, offering both theoretical insights and empirical evidence for their role in preventing over-mixing. Attention sinks emerge naturally as an essential mechanism for managing information propagation in Transformers, ensuring robust performance, particularly in long-context scenarios. Future research may explore optimizing these mechanisms to exploit their benefits fully in large-scale models.