- The paper introduces a two-stage approach using an anchor network and a denoising network to preserve key tokens and reduce sample complexity.
- Using the Anchored Negative ELBO and auxiliary loss, it achieves up to 25.4% lower perplexity than previous diffusion models.
- The framework extends to autoregressive tasks, enhancing chain-of-thought reasoning with notable accuracy gains in math and logic challenges.
Anchored Diffusion LLM: Theory, Algorithms, and Empirical Advances
Introduction
The "Anchored Diffusion LLM" (ADLM) (2505.18456) introduces a two-stage generative framework for discrete sequence modeling that aims to close the performance gap between diffusion-based masked LLMs (DLMs) and conventional autoregressive (AR) architectures. Diffusion LLMs enable parallel generation and bidirectional context, but historically have suffered deficits in likelihood estimation and generation quality compared to AR models. This work posits that critical information loss, incurred by early masking of semantically important tokens (anchors), is responsible for much of this deficit. ADLM addresses this issue by first using an anchor network to predict distributions over important tokens and subsequently applying a denoising network conditioned on the anchored predictions. The result is a diffusion LLM that achieves state-of-the-art perplexity and human-like text generation, and suggests a general framework for structured reasoning in both generative modeling and logical/mathematical tasks.
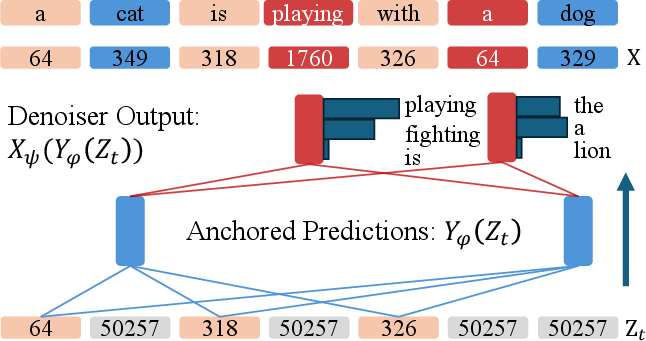
Figure 1: Anchored Diffusion LLM (ADLM) introduces an anchor network predicting important tokens, supporting targeted denoising and improved sequence estimation.
Problem Background and Diffusion Modeling Paradigm
Standard AR models maximize the likelihood of the next token by sequential decoding, using causal attention over the growing prefix. This structure is efficient for next-token prediction but suboptimal for long-range reasoning, global coherence, and parallel sampling. Diffusion LLMs generate sequences via iterative masked-token prediction and can leverage bidirectional attention over corrupted inputs, promising better context modeling and controllable generation. In practice, however, DLMs exhibit increased perplexity and less fidelity in generated text compared to AR baselines, especially when important tokens are masked early, diminishing the context available for reconstruction.
ADLM is structured as a two-stage process:
- Anchor Network: Given a partially masked sequence, an anchor network predicts a distribution over important tokens (anchors), focusing optimization capacity on key low-frequency or semantically salient tokens.
- Denoising Network: Conditioned on the anchor output, a denoiser network predicts likelihoods for the remaining masked tokens, taking advantage of structural guidance from anchors.
The reverse generative process is decomposed so that the anchor predictions serve as a latent plan, improving intermediate contextualization and enabling targeted inference throughout the reverse diffusion trajectory. The ADLM architecture is fully end-to-end trainable: the anchor and denoising networks are coupled via learnable linear projections, and gradients propagate between them.
Theoretical Guarantees: Anchored ELBO and Sample Complexity
A central theoretical contribution of the paper is the derivation of the Anchored Negative Evidence Lower Bound (ANELBO), which jointly regularizes the denoising process via anchor supervision. ANELBO decomposes into:
- Reconstruction loss for anchor-guided denoising.
- Auxiliary anchor loss encouraging early prediction of important tokens.
- Intermediate KL terms reflecting the difficulty of denoising masked tokens with and without anchor guidance.
It is shown that, under reasonable graphical model assumptions, anchoring reduces the sample complexity for maximum likelihood estimation exponentially: from O(KL) in full-context AR/DLMs to O(LKd+1) for anchored models, where d≪L is the anchor set cardinality. This yields practical scalability and tractable learning for large vocabulary, long-context settings.
Empirical Results: Likelihood Modeling and Sample Quality
ADLM demonstrates strong improvements over prior DLMs on both LM1B and OpenWebText benchmarks, achieving up to 25.4% lower perplexity versus previous diffusion models. Anchoring yields state-of-the-art zero-shot generalization, outperforming AR baselines on several domain-specific tasks including Lambada, PubMed, and ArXiv, especially in long-context and scientific domains. Generated text quality, measured in MAUVE score and GPT-2 Large perplexity, consistently exceeds previous DLMs, and for the first time, ADLM achieves better human-like generation than AR baselines under remasking sampling.
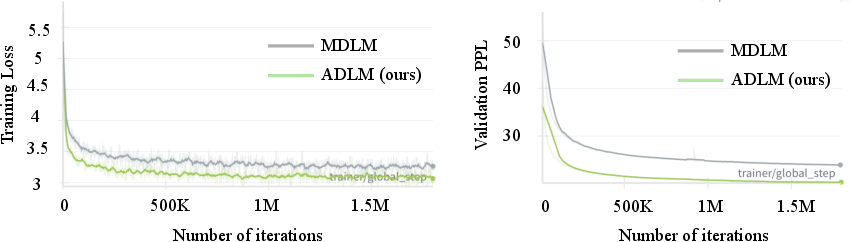
Figure 2: Training loss and validation perplexity for ADLM and baseline MDLM; anchoring delivers faster convergence and lower final perplexity on OWT.
Rigorous ablations show anchoring is not merely an increase in model capacity. Incorporation of anchor tokens and auxiliary loss achieves substantial gains compared to capacity-matched baselines. Importantly, the model performs robustly across locked-in and remasking sampling procedures, enhancing expressivity and diversity without sacrificing MAUVE score or entropy.
Anchored Reasoning: Auto-Regressive Models and Chain-of-Thought
Beyond the diffusion context, the paper demonstrates the utility of anchoring in AR architectures for mathematical and logical reasoning tasks. Inserting [ANT] tokens (anchors) before reasoning traces in chain-of-thought (CoT) prompts enables more structured intermediate computation. Anchored Chain-of-Thought (ACoT) delivers notable improvements in accuracy for GSM8K (+2.3% absolute over CoT), ProntoQA (100% accuracy), and ProsQA (97.3%, surpassing Coconut and Pause baselines).
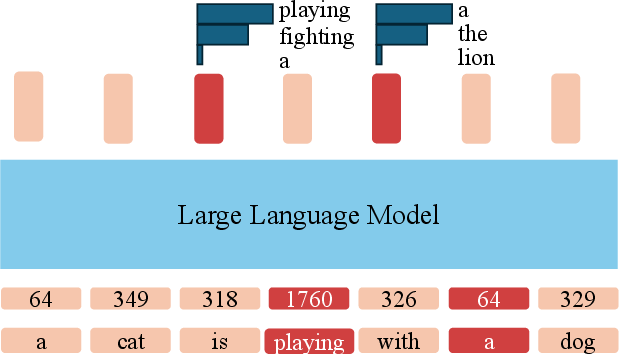
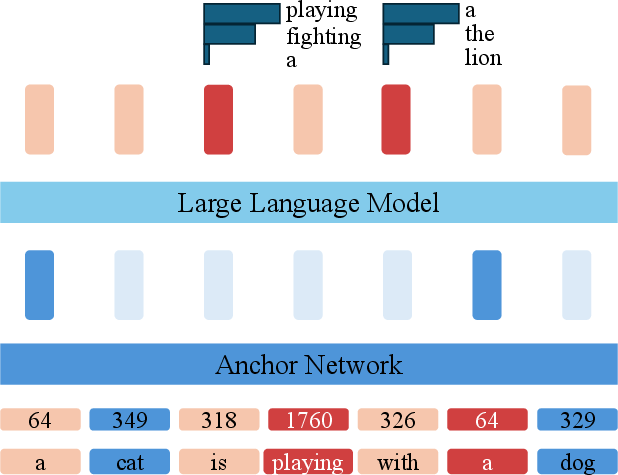
Figure 3: Standard AR training treats each token uniformly, while anchored AR guides modeling via selective anchoring of informative tokens.
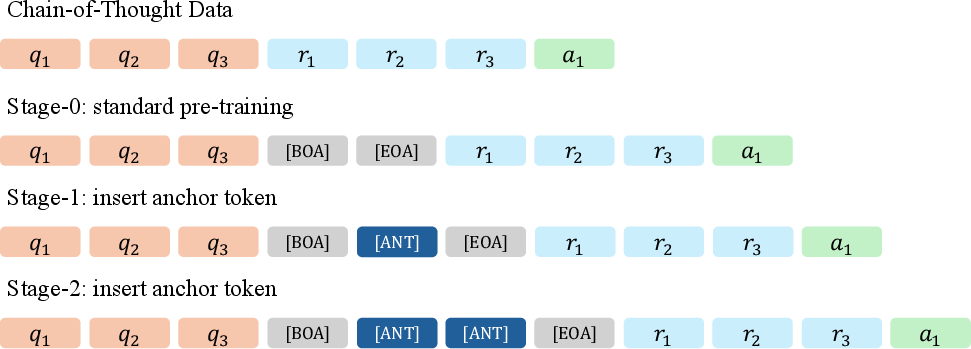
Figure 4: Multi-stage ACoT training pipeline supervises intermediate reasoning computations via anchor insertion and semantic pruning, improving planning and inference.
Anchoring is agnostic to model class—whether AR or DLM—and supports information-theoretic guidance for both generative modeling (likelihood, sample quality) and complex reasoning (logic, planning, math).
Practical and Theoretical Implications
The ADLM paradigm demonstrates that diffusion models can match and, in some metrics, surpass AR LLMs in both unconditional and conditional generation, provided intermediate reasoning and contextual guidance are introduced via anchors. The generality of the anchoring approach enables its application to any discrete structured prediction problem where important variables govern downstream inference.
Practically, anchoring provides a scalable avenue for efficient training in long-context, large-vocabulary settings, and facilitates controllable, interpretable generation. Theoretically, it opens up new directions in combining latent variable modeling, graphical model structure, and deep sequence modeling, suggesting further investigation into adaptive or LLM-informed anchor selection, multi-hop reasoning, and generative planning.
Conclusion
The Anchored Diffusion LLM delivers a principled, theoretically-justified framework that elevates diffusion LLMs to parity and beyond with autoregressive methods in both likelihood estimation and sample quality. The anchor-based two-stage parameterization leads to exponentially improved sample complexity, strong empirical performance across standard and zero-shot evaluation benchmarks, and robust reasoning gains in math and logic via ACoT. These advances position anchoring as a promising general-purpose technique for high-fidelity sequence modeling and structured reasoning in AI. Future work may address adaptive anchor identification, scaling to ultra-long contexts, and further integration with continuous and multimodal reasoning architectures.