- The paper introduces SDAR, integrating autoregressive training with diffusion-based parallel inference to enhance sequence generation efficiency.
- It adapts AR models into a block-wise diffusion framework by modifying attention masks and shifting the training objective from NLL to NELBO.
- Experiments demonstrate SDAR’s superior performance on benchmarks like MMLU, GPQA, and ChemBench, along with significant speedup in token generation.
SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation
The paper "SDAR: A Synergistic Diffusion-AutoRegression Paradigm for Scalable Sequence Generation" (2510.06303) introduces SDAR, a new language modeling framework that synergistically combines autoregression with diffusion models, leveraging their complementary strengths to achieve scalable and efficient sequence generation. This essay provides a detailed academic summary of the novel contributions presented in the paper, emphasizing its technical methodologies, numerical results, and broader implications in AI research.
Introduction
Traditionally, LLMs rely on autoregressive paradigms, modeling sequences in a token-by-token fashion which aligns with the sequential nature of language but limits parallelization during inference. This paper proposes SDAR, which integrates the efficiency of autoregressive (AR) training with the parallel inference capabilities of diffusion models. Unlike pure diffusion models that face challenges with ELBO-based training objectives and inference inefficiencies, SDAR uses an efficient conversion process that adapts a well-trained AR model into a block-wise diffusion model. The conversion maximizes parallel generation capabilities while retaining the autoregressive architecture's core advantages.
Methodology
The SDAR framework begins with the autoregressive training of a LLM using conventional next-token prediction (NTP). The AR model is then transformed into a diffusion model via lightweight adaptation, a process that includes modifying attention masks and adjusting the training objective from negative log-likelihood (NLL) to negative evidence lower bound (NELBO). This adaptation leverages intra-block parallelism for fast sequence generation while preserving the global autoregressive coherence necessary for context retention.
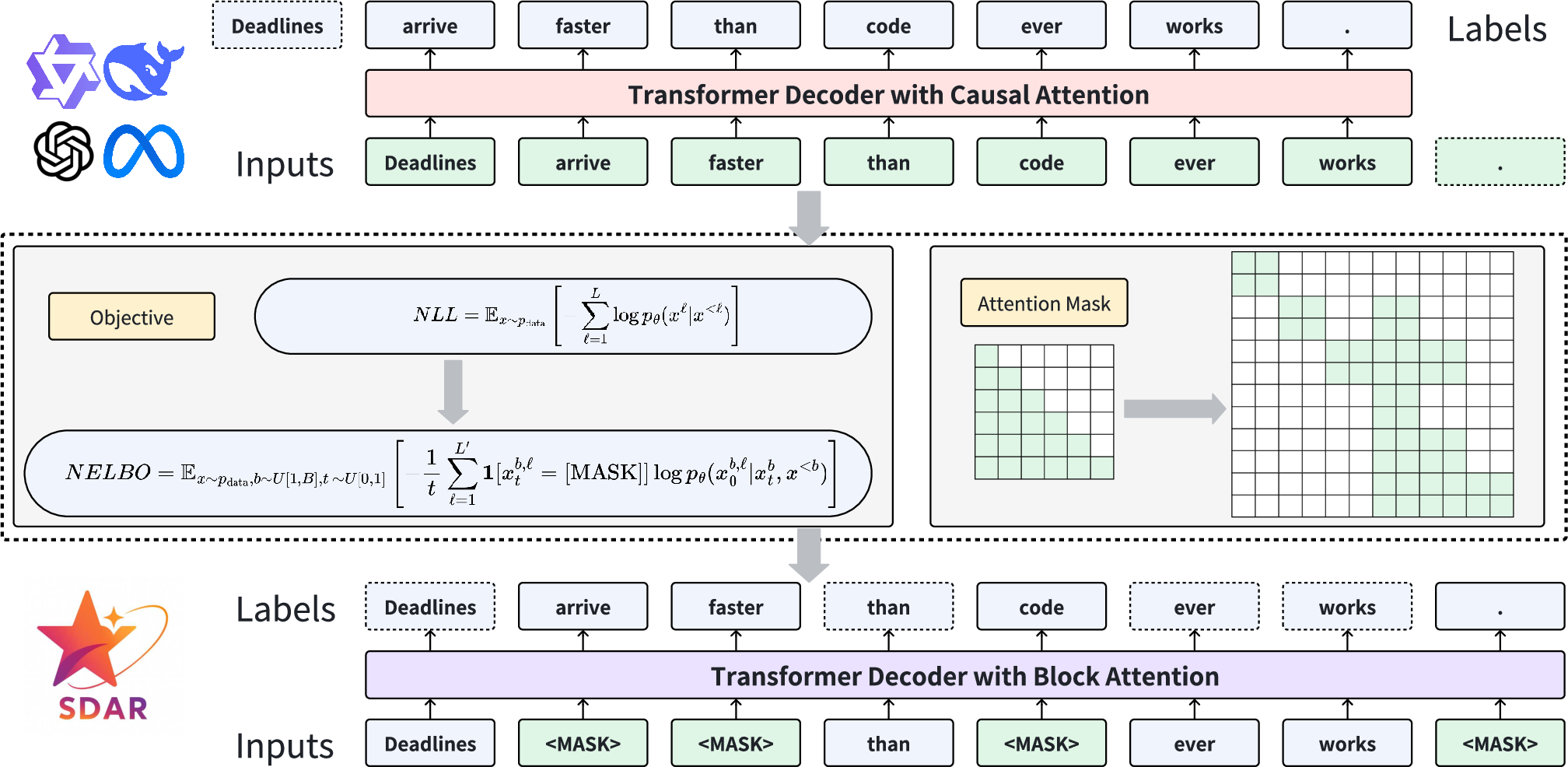
Figure 1: The training paradigm of converting AR to SDAR. First the traditional NTP training is adopted to obtain the AR base model. We then continue training the AR model by modifying the attention mask and replacing the training objective from NLL to NELBO, converting it into a block-wise diffusion model (SDAR), without logits shift or attention mask annealing.
During inference, SDAR employs a hierarchical strategy, generating text autoregressively at the block level and decoding all tokens within each block parallelly. This mechanism allows for efficient generation without sacrificing sequence coherence. The paper also discusses two remasking strategies—Static Low Confidence Remasking and Dynamic Low Confidence Remasking—used to enhance decoding performance based on prediction confidence thresholds.
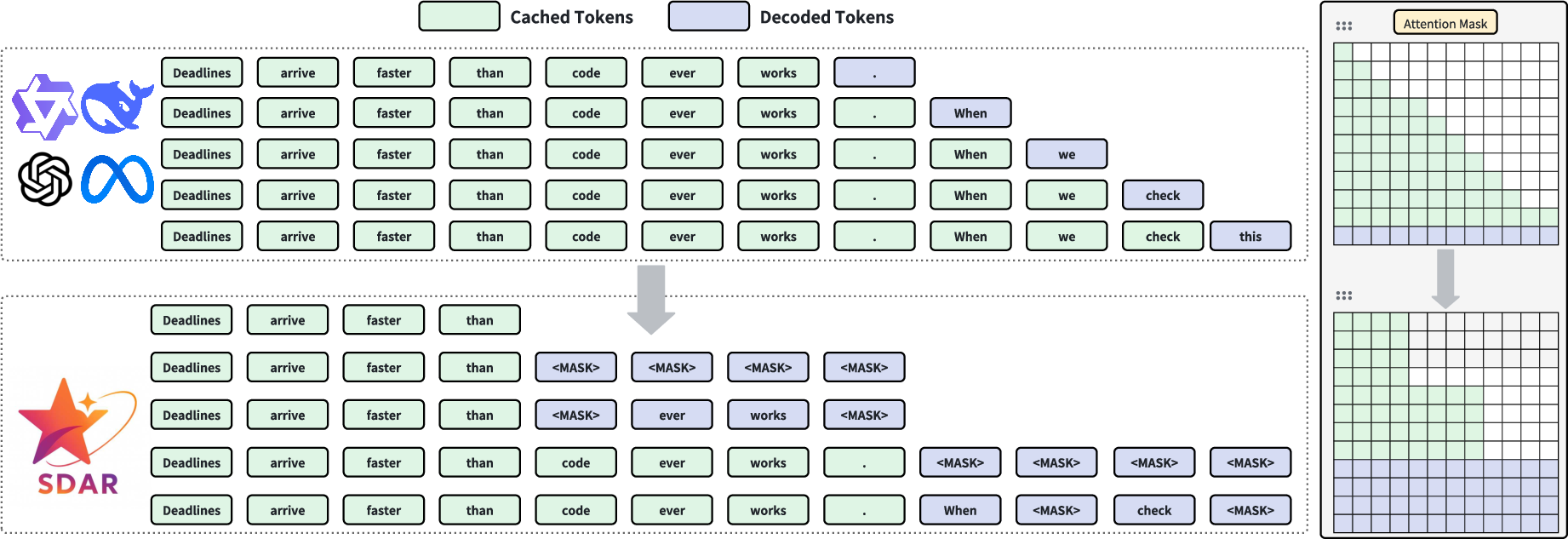
Figure 2: Contrasting inference paradigms between AR and SDAR. SDAR adopts a block-wise causal attention mechanism to enable inter-block causal autoregression and intra-block parallel diffusion. The KV cache from previously generated blocks is reused, while the block currently being decoded does not store KV cache.
Experimental Results
The experimental evaluation highlights SDAR's ability to maintain autoregressive performance while enabling substantial parallel decoding efficiency. Performance assessments using benchmarks such as MMLU, GPQA, and ChemBench illustrate that SDAR models not only match but often surpass their AR counterparts, particularly in reasoning tasks benefiting from bidirectional context.
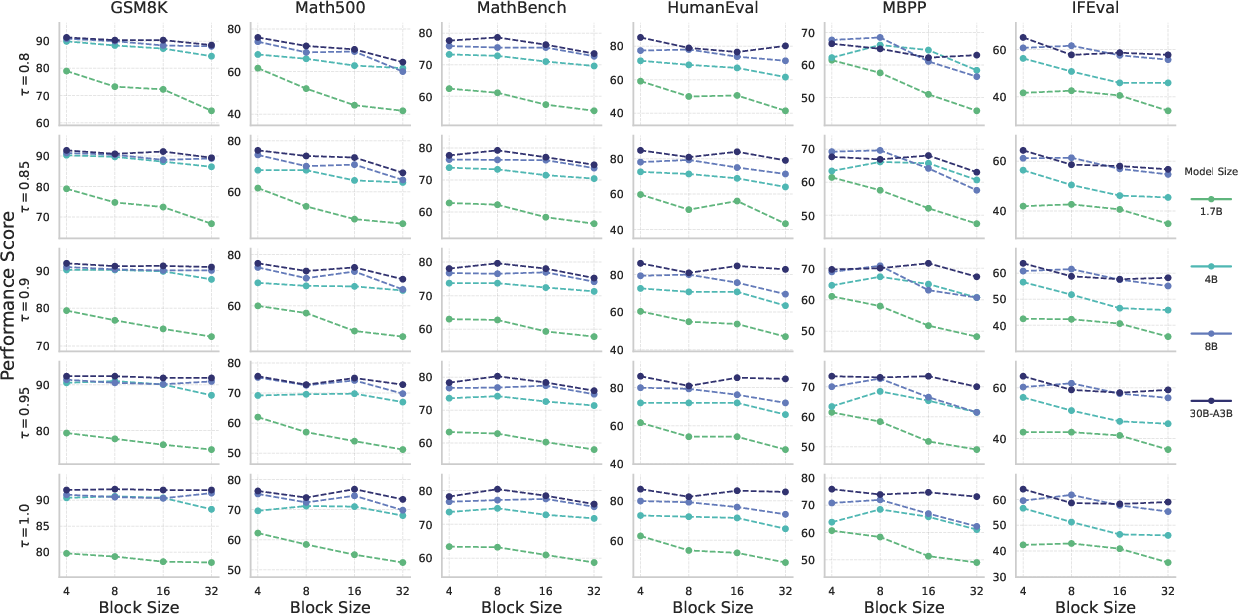
Figure 3: Performance on various benchmarks as a function of architectural block size (B) across different model scales and various confidence thresholds (τ).
Moreover, the paper reports major improvements in algorithmic speedup measured in Tokens Per Forward Pass (TPF), with larger models exhibiting increased robustness to block size and dynamic decoding thresholds, hence facilitating greater parallel speedups without loss of accuracy.
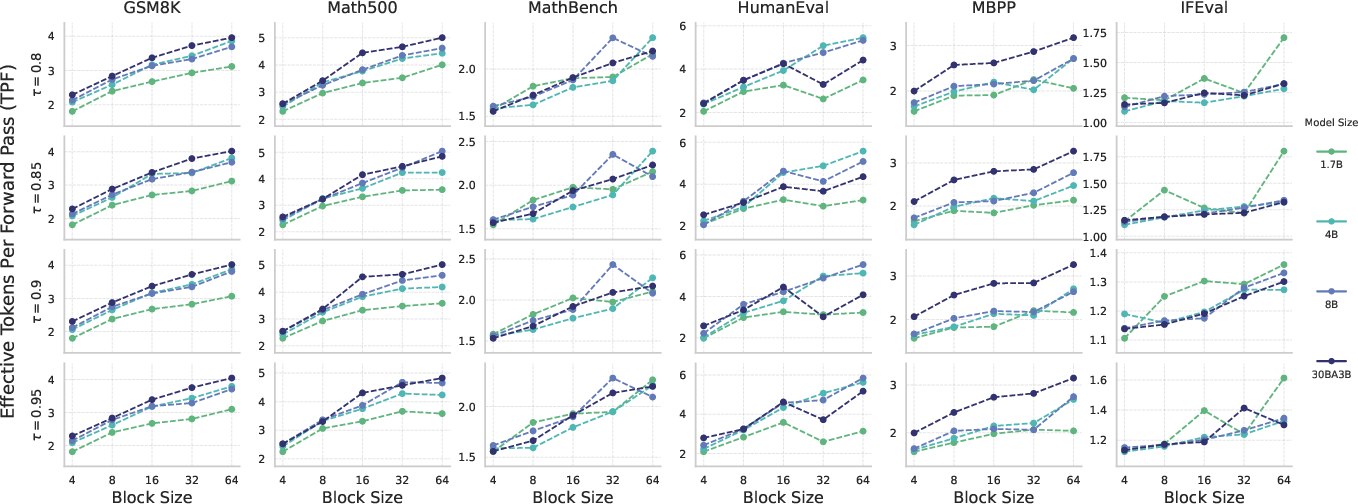
Figure 4: Algorithmic speedup, measured in Effective Tokens Per Forward Pass (TPF), as a function of architectural block size (B) across different model scales and various confidence thresholds (tau).
Implications and Future Directions
The results position SDAR as a promising alternative to conventional autoregressive models, with implications for reduced inference costs and enhanced reasoning capabilities in scientific domains. The integration of test-time scaling strategies, such as majority voting and pass@k, further accentuates SDAR's potential for efficient reinforcement learning optimization.
Looking forward, the SDAR framework could be pivotal in advancing AI applications where quick and accurate sequence generation is paramount. The synergy between autoregression and diffusion paradigms presents a pathway for overcoming the limitations of sequential token generation, fostering AI models adept at complex reasoning and domain-specific tasks.
Conclusion
SDAR introduces a novel paradigm in language modeling by effectively merging autoregressive training efficiency with diffusion-based inference parallelism. Through rigorous experiments, the paper demonstrates that SDAR scales effectively across model sizes and architectures, offering an efficient and practical solution for high-throughput sequence generation. This research provides a robust foundation for the future exploration of hybrid generative models in AI, notably enhancing the intersection of training efficiency and inference speed.