- The paper introduces D-AR, reinterpreting diffusion as an autoregressive token prediction task to streamline visual generation.
- It employs a sequential diffusion tokenizer that converts images into discrete, coarse-to-fine token sequences, aligning with standard AR models.
- Experiments on ImageNet 256×256 show competitive FID scores and efficient streaming previews, underscoring its practical impact.
Diffusion via Autoregressive Models: A Technical Overview
Introduction
The paper "D-AR: Diffusion via Autoregressive Models" presents an innovative approach to visual generation by integrating the strengths of diffusion models and autoregressive models (AR). Autoregressive models, particularly LLMs, have proven effective in sequential data processing, mainly demonstrated in NLP tasks. However, adapting the standard next-token prediction paradigm of AR models to visual synthesis has been challenging due to the lack of inherent linear structure in images. In contrast, diffusion models, which originate from noise to refine outputs through iterative denoising, excel in creating high-quality images but suffer from inherently slow sampling processes due to their dense operational nature.
To bridge these paradigms, the authors propose the D-AR framework, which reinterprets the image diffusion process as an autoregressive token prediction task. This approach employs a sequential diffusion tokenizer that converts the visual information into a sequence of discrete tokens. Each token in the sequence corresponds to different steps in the diffusion process. By ensuring these tokens follow a coarse-to-fine ordering, the method naturally aligns with the AR paradigm, enabling efficient visual generation while leveraging the advantages of diffusion models.
Methodology
Sequential Diffusion Tokenizer
The cornerstone of the D-AR framework is the sequential diffusion tokenizer. This component encodes images into discrete token sequences, which reflect progressive denoising steps. The tokenizer operates in two main phases: encoding and decoding.
During encoding, images are transformed into a sequence of discrete tokens via a transformer-based encoder followed by vector quantization. The decoding phase utilizes a diffusion transformer model to process these tokens, resembling the denoising pathway inherent in diffusion models. Importantly, the ordering of tokens in the sequence mirrors the progression from coarse, global semantics to fine, local details.
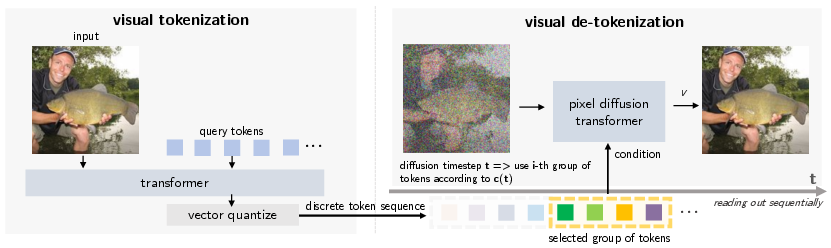
Figure 1: Sequential diffusion tokenizer structure. When training the tokenizer, the pixel diffusion transformer in the tokenizer decoder calculates the velocity loss with the selected group of tokens, c(t), as conditioning tokens.
This linearized token sequence allows standard autoregressive models to predict upcoming tokens without alterations to standard autoregressive mechanisms. Thus, the D-AR methodology retains a vanilla AR architecture, simplifying integration with existing LLM infrastructures.
Autoregressive Modeling
Once tokens are arranged by the sequential diffusion tokenizer, they are processed using a decoder-only transformer model adhering strictly to the autoregressive paradigm. This process generates images by predicting tokens sequentially, performing diffusion denoising steps simultaneously as new tokens are produced.
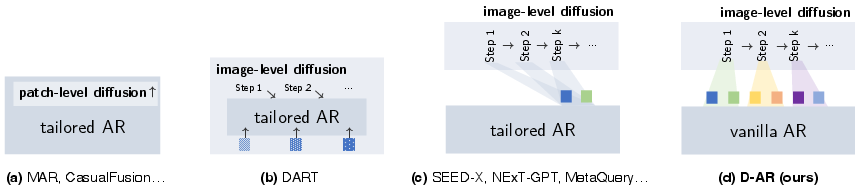
Figure 2: Different paradigms incorporating diffusion and autoregressive models for vision generation. (a) uses patch-level diffusion during every single autoregressive step to tackle continuous outputs~\cite{mar,causalfusion,diffusionforcing}; ours use vanilla AR models, which can train with discrete inputs/outputs by simply cross entropy, and sequentially decode output tokens with our diffusion tokenizer.
The critical advantage of this setup is that it maintains a Markovian diffusion sampling procedure managed by AR-induced token conditioning, which enables several sophisticated properties including fast inference compatible with KV cache, streaming pixel decoding, and zero-shot layout-controlled synthesis by prefix token conditioning.
Experimental Results
The D-AR framework was assessed on the ImageNet 256×256 benchmark, showcasing its competitive performance. The authors utilized models with 343M and 775M parameters, achieving FID scores of 2.44 and 2.09 respectively, which are competitive against existing state-of-the-art methods.

Figure 3: Uncurated generated samples from D-AR-XL with 256\times256 resolutions (CFG=4.0).
The methodology demonstrated superior efficiency in generating consistent previews from partial token sequences, highlighting its suitability for practical applications in AI-driven image synthesis.

Figure 4: Consistent previews as generation trajectories for every increment of 32 tokens (a group). Note that these previews can be generated in a streaming manner with AR tokens partially generated.
Moreover, the framework's ability to condition specific layout tokens in a zero-shot manner underscores its versatility in generating controlled image layouts without additional training, promoting its use in adaptive and creative tasks.

Figure 5: Zero-shot layout-controlled synthesis.
Conclusion
The introduction of D-AR represents a pivotal step in advancing AI-driven visual synthesis by leveraging the intrinsic strengths of both diffusion models and autoregressive frameworks. By transforming diffusion processes into token sequences, this method ensures alignment with the AR paradigm while optimizing efficiency and capability in visual generation tasks. The framework not only excels in generating high-quality images but also simplifies integration with modern LLM architectures, potentially inspiring further research into unified multimodal systems. Future research could explore extending D-AR to encompass native text-to-image generation capabilities, broadening its applicability across AI disciplines.