- The paper's main contribution is integrating a conformer-based audio encoder with LLaMA to enable ASR with an 18% improvement in WER on multilingual datasets.
- It employs a methodology that first trains the audio encoder using a CTC loss and then stacks and projects audio embeddings to match LLaMA's text embeddings.
- Experimental results on the Multilingual LibriSpeech dataset highlight efficient parameter usage and the scalability of combining audio and text modalities.
Prompting LLMs with Speech Recognition Abilities
This essay provides a detailed examination of the paper titled "Prompting LLMs with Speech Recognition Abilities" (2307.11795). The paper explores the extension of LLMs with a speech recognition capability by incorporating an audio encoder, fundamentally transforming LLMs into Automatic Speech Recognition (ASR) systems. The authors provide empirical evidence to validate their approach and offer insights into optimizing its performance on multilingual speech datasets.
Introduction
LLMs, like GPT, PaLM, and LLaMA, are pivotal in addressing a multitude of generative language tasks. These models, by predicting successive tokens from vast amounts of unsupervised textual data, encode comprehensive world knowledge in their network parameters. However, textual interactions limit their capacity to capture expressive modalities like audio or visual data that encode unique information. The paper presents a novel methodology to directly attach a small audio encoder to LLaMA, enabling it to recognize speech and outperform monolingual models by 18% in word error rate (WER) during multilingual ASR tasks. The proposed conformer-based encoder effectively converts speech into embeddings compatible with LLMs, facilitating a seamless integration of audio data for expanded capabilities.
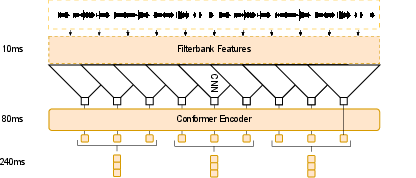
Figure 1: Audio encoder architecture. The initial conformer is trained on a CTC loss. Thereafter the outputs are stacked and projected to the dimension of the LLM to ensure compatibility. This figure showcases a stacking factor of 3 resulting in 240ms embeddings.
Methodology
The paper's methodology hinges on embedding sequences generated by a trained conformer-based audio encoder, which are subsequently prepended to existing text embeddings for input into LLaMA—a decoder-only LLM. This technique allows the LLM to process speech recognition and perform other speech tasks with equal facility as text-based operations. Notably, each component's embeddings occupy the same latent space, promoting seamless integration.
The audio encoder, tasked initially with a Connectionist Temporal Classification (CTC) loss, extracts audial embeddings from 80-d filterbank features. These embeddings are variably stacked to adjust sequence length, projected to match LLaMA's hidden dimensions, and merged with text embeddings (Figure 2).
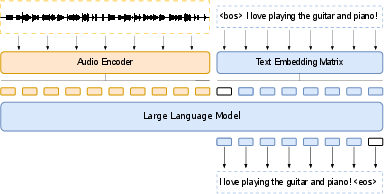
Figure 2: Model architecture. The embedding sequence generated from the audio encoder is directly prepended to the text embeddings sequence. This is directly fed into the decoder-only LLM, tasked with predicting the next token. The LLM can be frozen, adapted with parameter-efficient approaches such as LoRA or fully fine-tuned. This work investigates the former two.
Experimental Evaluation
Experiments conducted using the Multilingual LibriSpeech (MLS) dataset demonstrate the approach's efficacy. The embedding techniques enabled LLaMA-7B to reach competitive WER scores across languages while significantly reducing training parameter requirements. The evaluation considered different audio encoder configurations, striding levels, and low-rank adaptations, offering a comprehensive analysis across multilingual scenarios.
The paper illustrates that utilizing larger models and increasing low-rank adaptation parameters, like LLaMA and BLOOM, improves recognition performance without extensively tuning all LLM parameters—a crucial consideration for practical implementations.
Implications and Future Directions
This approach heralds significant enhancements in multilingual ASR systems, emphasizing efficient parameter usage and high adaptability. The alignment studies suggest further improvements could stem from training audio embeddings to be directly aligned with their text counterparts. Such methodologies hint at future innovations that could integrate varied modalities, promoting deeper LLM interactivity beyond textual confines.
Conclusion
The authors successfully illustrate an efficient procedure for transforming LLMs into powerful ASR systems by integrating an audio encoder. Through comprehensive experiments and ablation studies, the paper identifies key factors influencing performance and delineates promising avenues for future research, such as enhancing audio-text alignment. This represents a meaningful step towards developing adaptable and resource-efficient LLMs that can more comprehensively interpret human language across diverse modalities.