- The paper introduces a novel single-stage joint speech-text fine-tuning approach using LoRA to merge speech and text capabilities without sacrificing text performance.
- The methodology integrates a speech encoder, modality adapter, and language model to process mixed-modal inputs effectively in multi-turn contexts.
- Experimental results show significant improvements in ASR and AST benchmarks, demonstrating robust multilingual and mixed-modal performance.
VoiceTextBlender: Augmenting LLMs with Speech Capabilities
This essay provides an expert analysis of the paper "VoiceTextBlender: Augmenting LLMs with Speech Capabilities via Single-Stage Joint Speech-Text Supervised Fine-Tuning" (2410.17485). The researchers present a novel methodology to integrate speech capabilities into LLMs through a single-stage joint speech-text supervised fine-tuning (SFT) approach, effectively enhancing the multi-modal capabilities of LLMs while preserving their original text functionalities.
Introduction and Motivation
The development of Speech LLMs (SpeechLMs) has progressed significantly, with methodologies extending from single-turn speech-based QA to more complex multi-turn, mixed-modal conversations. Traditional approaches rely on complex, multi-stage fine-tuning, which can inadvertently degrade a model's performance on text-only tasks due to catastrophic forgetting. This paper introduces the VoiceTextBlender (VTBlender) model, a streamlined 3B parameter LLM that leverages a single-stage SFT strategy utilizing low-rank adaptation (LoRA) techniques.
Model Architecture
VTBlender utilizes three primary components: a speech encoder, a modality adapter, and a LLM. The architecture is designed to process and integrate both speech and text inputs effectively. The speech encoder, initialized from a pre-trained Canary model, extracts continuous features from raw speech inputs. These features are then adapted and mapped into a shared embedding space along with text embeddings, facilitating seamless interaction with the LLM for text generation.
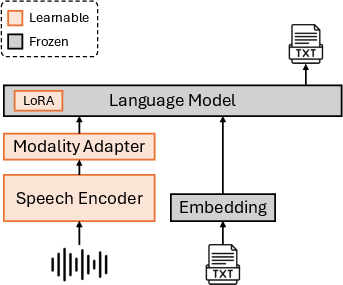
Figure 1: Model architecture. Only a pair of speech and text are depicted for simplicity, but the input can contain multiple segments of speech and text in any order.
Joint Speech-Text Supervised Fine-Tuning
The novel single-stage joint SFT approach combines multi-turn text-only data with three types of speech-related data: automatic speech recognition (ASR) and automatic speech translation (AST), speech-based QA, and mixed-modal SFT. This approach allows VTBlender to maintain strong text-only performance while enhancing speech understanding capabilities. The integration of mixed-modal interleaving speech-text inputs, synthesized through text-to-speech (TTS), expands the model’s ability to handle diverse conversational formats.
Experimental Evaluations
Evaluations reveal VTBlender's prowess, securing superior results in ASR and AST tasks with notable improvements over models like SALMONN and Qwen2-Audio. In multilingual benchmarks, the model achieved impressive Word Error Rate (WER) reductions and superior BLEU scores in translation tasks. Despite training solely on single-turn data, VTBlender adeptly handles multi-turn mixed-modal inputs, demonstrating strong generalization abilities without compromising original text-task performance.

Figure 2: Our VTBlender 3B with joint SFT enables multi-turn, mixed-modal conversations, allowing user input in the form of pure speech, pure text, or a combination of both.
Ablation Studies
A series of ablation studies underscore the efficacy of the proposed joint SFT methodology. The studies highlight how single-stage training with LoRA updates provides a balanced enhancement of both speech and text capabilities. In contrast, models that employed multi-stage training or froze LM parameters exhibited degradation in either speech or text tasks.
Demonstrations
The paper provides illustrative examples showcasing VTBlender’s capabilities in multi-turn mixed-modal dialogues, handling unseen prompts, and performing complex tasks such as mathematical problem-solving and coding based on mixed-modal inputs. These examples underscore the model's robustness and its emergent ability to generalize beyond training conditions.

Figure 3: Example of solving a math question based on mixed-modal input.
Conclusion
The introduction of VoiceTextBlender marks a significant advancement in the field of multi-modal language modeling. The model's ability to seamlessly integrate speech and text capabilities within a single-stage fine-tuning framework presents a compelling alternative to traditional multi-stage methods. Future developments could focus on scaling the model and extending its functional domain to encapsulate more specialized speech tasks and reinforcing pre-training stages with speech input. The release of pre-trained models and code is expected to support further research and innovation in the burgeoning field of SpeechLMs.