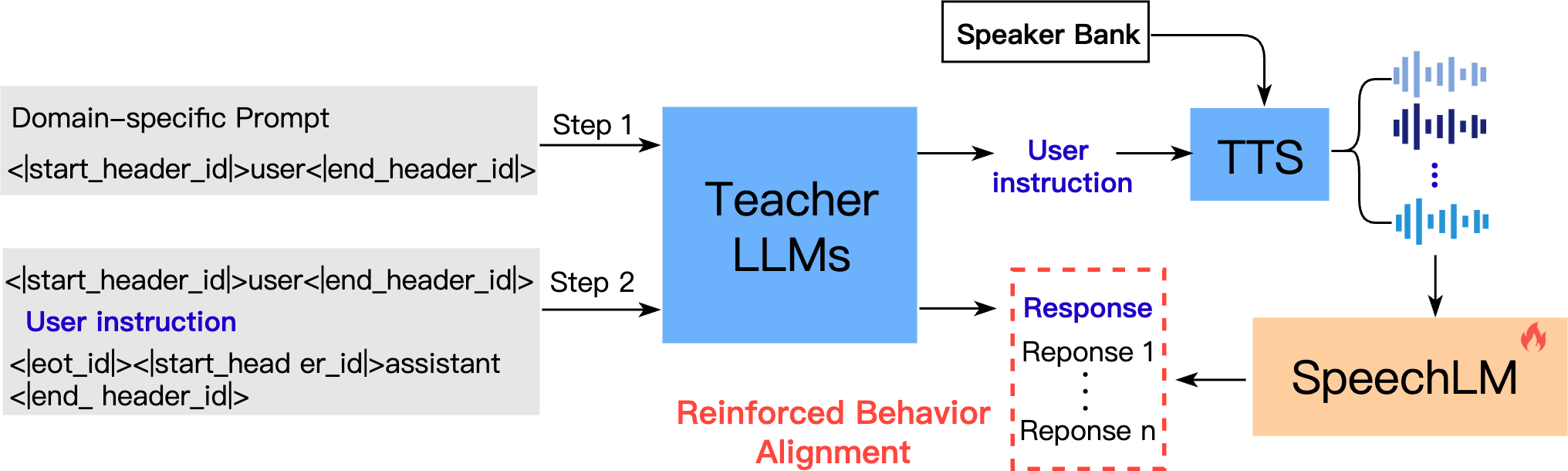
- The paper improves Speech LLMs by introducing Reinforced Behavior Alignment, aligning them with advanced text-based models to enhance instruction-following.
- It employs self-synthesis data generation and reinforcement learning methodologies to bridge inter-modal performance gaps with high-quality synthetic instruction-response pairs.
- Results demonstrate significant performance gains in spoken question answering and speech-to-text translation, underlining its potential in multimodal applications.
Enhancing Speech LLMs through Reinforced Behavior Alignment
Introduction
The paper "Enhancing Speech LLMs through Reinforced Behavior Alignment" (2509.03526) presents an innovative approach to improving the capability of Speech LLMs (SpeechLMs) to perform instruction-following tasks using a framework called Reinforced Behavior Alignment (RBA). This research addresses the notable performance gap between SpeechLMs and their text-based counterparts in handling instructions, a discrepancy largely attributed to inter-modal differences. SpeechLMs often struggle with the variability inherent to spoken language. To bridge this gap, the authors propose aligning SpeechLM behavior with that of advanced text-based teacher models through reinforcement learning techniques, facilitated by high-quality synthetic data generation.
Methodology
The study introduces RBA, a two-step framework that significantly enhances SpeechLM performance:
1. Self-Synthesis Data Generation:
RBA constructs a large-scale instruction dataset through self-synthesis, eliminating the need for manual annotation. This involves using a text-based LLM, specifically a high-capacity aligned LLM, to generate pairs of instructions and their corresponding responses.
2. Reinforcement Learning for SpeechLMs:
The second phase employs reinforcement learning to align the behavior of SpeechLMs with that of the teacher LLM:
- Reward Modeling: The alignment process uses a pre-trained reward model to evaluate speech-generated responses. Two strategies, RBA-Group and RBA-Single, are introduced for positive-negative sampling based on multi-speaker inputs. RBA-Group focuses on choosing the best result from a set, while RBA-Single uses teacher LLM-generated data as a baseline for comparison.
- Optimization Process: Reinforcement learning techniques adjust the SpeechLM to align closely with the sophisticated responses of LLMs, overcoming biases and improving the model's performance in generating human-like responses across different speech tasks.
Results and Discussion
The paper reports significant improvements in accuracy and robustness of SpeechLMs, outperforming traditional text-to-speech fine-tuning approaches. Key performance gains are observed across various benchmarks in spoken question answering (SQA) and speech-to-text translation (S2TT) tasks. Notably, the self-synthetic dataset used in RBA facilitates substantial speech model improvements without requiring extensive annotated data, showcasing the efficacy of using self-synthesized data for behavioral alignment.
- Instruction-Following: The RBA framework, particularly the RBA-Single variant, achieves higher win rates and better generalization across domains when evaluated against baseline models.
- Adaptation to Downstream Tasks: The method's adaptability allows it to perform exceptionally well in SQA and S2TT tasks, highlighting its effectiveness in multimodal applications.
Conclusion
The proposed RBA method successfully addresses the challenge of inter-modal discrepancies in SpeechLMs by aligning their behavior with advanced LLMs through reinforcement learning. This alignment significantly enhances instruction-following capabilities, effectively closing the gap between speech-based and text-based models. The study demonstrates the potential of self-synthesized data in avoiding the limitations of conventional annotated datasets and opens pathways for adapting RBA to other speech and multimodal tasks. Future research could explore expanding this framework to include additional modalities and refining model efficiency further.