Embedding Democratic Values into Social Media AIs via Societal Objective Functions
Abstract: Can we design AI systems that rank our social media feeds to consider democratic values such as mitigating partisan animosity as part of their objective functions? We introduce a method for translating established, vetted social scientific constructs into AI objective functions, which we term societal objective functions, and demonstrate the method with application to the political science construct of anti-democratic attitudes. Traditionally, we have lacked observable outcomes to use to train such models, however, the social sciences have developed survey instruments and qualitative codebooks for these constructs, and their precision facilitates translation into detailed prompts for LLMs. We apply this method to create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes, and test this democratic attitude model across three studies. In Study 1, we first test the attitudinal and behavioral effectiveness of the intervention among US partisans (N=1,380) by manually annotating (alpha=.895) social media posts with anti-democratic attitude scores and testing several feed ranking conditions based on these scores. Removal (d=.20) and downranking feeds (d=.25) reduced participants' partisan animosity without compromising their experience and engagement. In Study 2, we scale up the manual labels by creating the democratic attitude model, finding strong agreement with manual labels (rho=.75). Finally, in Study 3, we replicate Study 1 using the democratic attitude model instead of manual labels to test its attitudinal and behavioral impact (N=558), and again find that the feed downranking using the societal objective function reduced partisan animosity (d=.25). This method presents a novel strategy to draw on social science theory and methods to mitigate societal harms in social media AIs.
- Douglas J Ahler and Gaurav Sood. 2018. The parties in our heads: Misperceptions about party composition and their consequences. The Journal of Politics 80, 3 (2018), 964–981.
- The Welfare Effects of Social Media. American Economic Review 110, 3 (March 2020), 629–76. https://doi.org/10.1257/aer.20190658
- Carolina Are. 2020. How Instagram’s algorithm is censoring women and vulnerable users but helping online abusers. Feminist media studies 20, 5 (2020), 741–744.
- Constitutional AI: Harmlessness from AI Feedback. arXiv:2212.08073 [cs.CL]
- Chris Bail. 2022. Breaking the social media prism: How to make our platforms less polarizing. Princeton University Press.
- Exposure to ideologically diverse news and opinion on Facebook. Science 348, 6239 (2015), 1130–1132.
- Digital Technology and Democratic Theory. University of Chicago Press. https://doi.org/10.7208/chicago/9780226748603.001.0001
- Embedding Societal Values into Social Media Algorithms. Journal of Online Trust and Safety 2, 1 (2023).
- Gobo: A System for Exploring User Control of Invisible Algorithms in Social Media. In Conference Companion Publication of the 2019 on Computer Supported Cooperative Work and Social Computing (Austin, TX, USA) (CSCW ’19). Association for Computing Machinery, New York, NY, USA, 151–155. https://doi.org/10.1145/3311957.3359452
- Monika Bickert. 2018. Publishing Our Internal Enforcement Guidelines and Expanding Our Appeals Process. https://about.fb.com/news/2018/04/comprehensive-community-standards/
- Reuben Binns. 2017. Fairness in Machine Learning: Lessons from Political Philosophy. CoRR abs/1712.03586 (2017). arXiv:1712.03586 http://arxiv.org/abs/1712.03586
- Cross-Country Trends in Affective Polarization. Working Paper 26669. National Bureau of Economic Research. https://doi.org/10.3386/w26669
- Overperception of moral outrage in online social networks inflates beliefs about intergroup hostility. Nature human behaviour (2023), 1–11.
- Language Models are Few-Shot Learners. Advances in neural information processing systems 33 (2020), 1877–1901.
- Controlling polarization in personalization: An algorithmic framework. In Proceedings of the conference on fairness, accountability, and transparency. 160–169.
- Uthsav Chitra and Christopher Musco. 2020. Analyzing the impact of filter bubbles on social network polarization. In Proceedings of the 13th International Conference on Web Search and Data Mining. 115–123.
- How algorithmic popularity bias hinders or promotes quality. Scientific reports 8, 1 (2018), 15951.
- James Price Dillard and Lijiang Shen. 2005. On the nature of reactance and its role in persuasive health communication. Communication monographs 72, 2 (2005), 144–168.
- The Augmented Social Scientist: Using Sequential Transfer Learning to Annotate Millions of Texts with Human-Level Accuracy. Sociological Methods & Research (2022). https://doi.org/10.1177/00491241221134526 arXiv:https://doi.org/10.1177/00491241221134526
- Correcting misperceptions of out-partisans decreases American legislators’ support for undemocratic practices. Proceedings of the National Academy of Sciences 120, 23 (2023), e2301836120.
- Dean Eckles. 2022. Algorithmic transparency and assessing effects of algorithmic ranking. https://doi.org/10.31235/osf.io/c8za6
- Will the crowd game the algorithm? Using layperson judgments to combat misinformation on social media by downranking distrusted sources. In Proceedings of the 2020 CHI conference on human factors in computing systems. 1–11.
- Political sectarianism in America. Science 370, 6516 (2020), 533–536.
- Measuring the reach of” fake news” and online disinformation in Europe. Australasian Policing 10, 2 (2018).
- Erin D Foster and Ariel Deardorff. 2017. Open science framework (OSF). Journal of the Medical Library Association: JMLA 105, 2 (2017), 203.
- Tarleton Gillespie. 2018. Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media. Yale University Press.
- Asymmetric ideological segregation in exposure to political news on Facebook. Science 381, 6656 (2023), 392–398.
- Algorithmic content moderation: Technical and political challenges in the automation of platform governance. Big Data & Society 7, 1 (2020), 2053951719897945. https://doi.org/10.1177/2053951719897945 arXiv:https://doi.org/10.1177/2053951719897945
- How accurate are survey responses on social media and politics? Political Communication 36, 2 (2019), 241–258.
- How do social media feed algorithms affect attitudes and behavior in an election campaign? Science 381, 6656 (2023), 398–404.
- Reshares on social media amplify political news but do not detectably affect beliefs or opinions. Science 381, 6656 (2023), 404–408.
- Trans time: Safety, privacy, and content warnings on a transgender-specific social media site. Proceedings of the ACM on Human-Computer Interaction 4, CSCW2 (2020), 1–27.
- Evaluating Large Language Models in Generating Synthetic HCI Research Data: A Case Study. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems (Hamburg, Germany) (CHI ’23). Association for Computing Machinery, New York, NY, USA, Article 433, 19 pages. https://doi.org/10.1145/3544548.3580688
- Psychological well-being and social media use: a meta-analysis of associations between social media use and depression, anxiety, loneliness, eudaimonic, hedonic and social well-being. Anxiety, Loneliness, Eudaimonic, Hedonic and Social Well-Being (March 9, 2022) (2022).
- The Oxford handbook of Internet studies.
- Interventions to reduce partisan animosity. Nature Human Behaviour 6, 9 (2022), 1194–1205.
- Anna Lauren Hoffmann. 2019. Where fairness fails: data, algorithms, and the limits of antidiscrimination discourse. Information, Communication & Society 22, 7 (2019), 900–915. https://doi.org/10.1080/1369118X.2019.1573912 arXiv:https://doi.org/10.1080/1369118X.2019.1573912
- Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes. In Findings of the Association for Computational Linguistics: ACL 2023. Association for Computational Linguistics, Toronto, Canada, 8003–8017. https://aclanthology.org/2023.findings-acl.507
- Is ChatGPT Better than Human Annotators? Potential and Limitations of ChatGPT in Explaining Implicit Hate Speech. In Companion Proceedings of the ACM Web Conference 2023 (Austin, TX, USA) (WWW ’23 Companion). Association for Computing Machinery, New York, NY, USA, 294–297. https://doi.org/10.1145/3543873.3587368
- Algorithmic amplification of politics on Twitter. Proceedings of the National Academy of Sciences 119, 1 (2022), e2025334119.
- The origins and consequences of affective polarization in the United States. Annual review of political science 22 (2019), 129–146.
- Shanto Iyengar and Sean J. Westwood. 2015. Fear and Loathing across Party Lines: New Evidence on Group Polarization. American Journal of Political Science 59, 3 (2015), 690–707. https://doi.org/10.1111/ajps.12152 arXiv:https://onlinelibrary.wiley.com/doi/pdf/10.1111/ajps.12152
- Dietmar Jannach and Gediminas Adomavicius. 2016. Recommendations with a purpose. In Proceedings of the 10th ACM conference on recommender systems. 7–10.
- Understanding Effects of Algorithmic vs. Community Label on Perceived Accuracy of Hyper-partisan Misinformation. Proceedings of the ACM on Human-Computer Interaction 6, CSCW2 (2022), 1–27.
- Exploiting Programmatic Behavior of LLMs: Dual-Use Through Standard Security Attacks. arXiv:2302.05733 [cs.CR]
- Jon Keegan. 2016. Blue Feed, Red Feed. http://graphics.wsj.com/blue-feed-red-feed/
- Junsol Kim and Byungkyu Lee. 2023. AI-Augmented Surveys: Leveraging Large Language Models for Opinion Prediction in Nationally Representative Surveys. arXiv:2305.09620 [cs.CL]
- How affective polarization undermines support for democratic norms. Public Opinion Quarterly 85, 2 (2021), 663–677.
- Affective polarization or partisan disdain? Untangling a dislike for the opposing party from a dislike of partisanship. Public Opinion Quarterly 82, 2 (2018), 379–390.
- The Challenge of Understanding What Users Want: Inconsistent Preferences and Engagement Optimization. In Proceedings of the 23rd ACM Conference on Economics and Computation (Boulder, CO, USA) (EC ’22). Association for Computing Machinery, New York, NY, USA, 29. https://doi.org/10.1145/3490486.3538365
- Large Language Models are Zero-Shot Reasoners. In Advances in Neural Information Processing Systems, Vol. 35. 22199–22213.
- Rotating Online Behavior Change Interventions Increases Effectiveness But Also Increases Attrition. Proc. ACM Hum.-Comput. Interact. 2, CSCW, Article 95 (nov 2018), 25 pages. https://doi.org/10.1145/3274364
- Resolving content moderation dilemmas between free speech and harmful misinformation. Proceedings of the National Academy of Sciences 120, 7 (2023), e2210666120.
- Social media use and depressive symptoms among United States adolescents. Journal of Adolescent Health 68, 3 (2021), 572–579.
- TurkPrime. com: A versatile crowdsourcing data acquisition platform for the behavioral sciences. Behavior research methods 49, 2 (2017), 433–442.
- Personalized news recommendation based on click behavior. In Proceedings of the 15th international conference on Intelligent user interfaces. 31–40.
- A systematic review of worldwide causal and correlational evidence on digital media and democracy. Nature human behaviour 7, 1 (2023), 74–101.
- Li Lucy and David Bamman. 2021. Gender and Representation Bias in GPT-3 Generated Stories. In Proceedings of the Third Workshop on Narrative Understanding. Association for Computational Linguistics, Virtual, 48–55. https://doi.org/10.18653/v1/2021.nuse-1.5
- Christoph Lutz. 2022. Inequalities in Social Media Use and their Implications for Digital Methods Research. 679–690.
- Hybrid media consumption: How tweeting during a televised political debate influences the vote decision. In Proceedings of the 17th ACM conference on Computer supported cooperative work & social computing. 1422–1432.
- From Optimizing Engagement to Measuring Value. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (Virtual Event, Canada) (FAccT ’21). Association for Computing Machinery, New York, NY, USA, 714–722. https://doi.org/10.1145/3442188.3445933
- Twitter’s Algorithm: Amplifying Anger, Animosity, and Affective Polarization. arXiv preprint arXiv:2305.16941 (2023).
- Emily Moyer-Gusé and Robin L Nabi. 2010. Explaining the effects of narrative in an entertainment television program: Overcoming resistance to persuasion. Human communication research 36, 1 (2010), 26–52.
- Luke Munn. 2020. Angry by design: Toxic communication and technical architectures. Humanities and Social Sciences Communications 7, 1 (2020), 1–11.
- Encouraging reading of diverse political viewpoints with a browser widget. In Proceedings of the international AAAI conference on web and social media, Vol. 7. 419–428.
- Sean A Munson and Paul Resnick. 2010. Presenting diverse political opinions: how and how much. In Proceedings of the SIGCHI conference on human factors in computing systems. 1457–1466.
- StereoSet: Measuring stereotypical bias in pretrained language models. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics, Online, 5356–5371. https://doi.org/10.18653/v1/2021.acl-long.416
- Arvind Narayanan. 2023. Understanding Social Media Recommendation Algorithms. https://knightcolumbia.org/content/understanding-social-media-recommendation-algorithms.
- Social media is polarized, social media is polarized: towards a new design agenda for mitigating polarization. In Proceedings of the 2018 designing interactive systems conference. 957–970.
- (Re) Design to Mitigate Political Polarization: Reflecting Habermas’ ideal communication space in the United States of America and Finland. Proceedings of the ACM on Human-computer Interaction 3, CSCW (2019), 1–25.
- Like-minded sources on Facebook are prevalent but not polarizing. Nature 620, 7972 (2023), 137–144.
- OpenAI. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
- Training Language Models to Follow Instructions with Human Feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Training language models to follow instructions with human feedback. arXiv:2203.02155 [cs.CL]
- Aviv Ovadya and Luke Thorburn. 2023. Bridging Systems: Open Problems for Countering Destructive Divisiveness across Ranking, Recommenders, and Governance. arXiv preprint arXiv:2301.09976 (2023).
- Predicting the importance of newsfeed posts and social network friends. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 24. 1419–1424.
- Nitish Pahwa. 2021. Facebook Asked Users What Content Was “Good” or “Bad for the World.” Some of the Results Were Shocking. https://slate.com/technology/2021/11/facebook-good-bad-for-the-world-gftw-bftw.html
- Automated Annotation with Generative AI Requires Validation. arXiv:2306.00176 [cs.CL]
- Fábio Perez and Ian Ribeiro. 2022. Ignore Previous Prompt: Attack Techniques For Language Models. https://doi.org/10.48550/ARXIV.2211.09527
- Jay Peters. 2022. Twitter makes it harder to choose the old reverse-chronological feed. https://www.theverge.com/2022/3/10/22971307/twitter-home-timeline-algorithmic-reverse-chronological-feed
- Pew Research Center. 2019. Partisan Antipathy: More Intense, More Personal. Technical Report. Washington, D.C. https://www.pewresearch.org/politics/2019/10/10/the-partisan-landscape-and-views-of-the-parties/
- Google Transparency Report. 2023. YouTube Community Guidelines enforcement. https://transparencyreport.google.com/youtube-policy/removals
- Antecedents of support for social media content moderation and platform regulation: the role of presumed effects on self and others. Information, Communication & Society 25, 11 (2022), 1632–1649.
- Users choose to engage with more partisan news than they are exposed to on Google Search. Nature (2023), 1–7.
- Digital inequalities and why they matter. Information, Communication & Society 18, 5 (2015), 569–582. https://doi.org/10.1080/1369118X.2015.1012532 arXiv:https://doi.org/10.1080/1369118X.2015.1012532
- Fred Rowland. 2011. The filter bubble: what the internet is hiding from you. portal: Libraries and the Academy 11, 4 (2011), 1009–1011.
- Whose Opinions Do Language Models Reflect? arXiv:2303.17548 [cs.CL]
- Perspective-taking to reduce affective polarization on social media. In Proceedings of the International AAAI Conference on Web and Social Media, Vol. 16. 885–895.
- Michael Scharkow and Marko Bachl. 2017. How measurement error in content analysis and self-reported media use leads to minimal media effect findings in linkage analyses: A simulation study. Political Communication 34, 3 (2017), 323–343.
- Nick Seaver. 2017. Algorithms as culture: Some tactics for the ethnography of algorithmic systems. Big data & society 4, 2 (2017), 2053951717738104.
- Designing political deliberation environments to support interactions in the public sphere. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems. 3167–3176.
- The Woman Worked as a Babysitter: On Biases in Language Generation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 3407–3412. https://doi.org/10.18653/v1/D19-1339
- Charles Percy Snow. 1959. Two cultures. Science 130, 3373 (1959), 419–419.
- Building Human Values into Recommender Systems: An Interdisciplinary Synthesis. arXiv preprint arXiv:2207.10192 (2022).
- Cass R Sunstein. 2001. http://Republic. com.
- Cass R Sunstein. 2015. Partyism. U. Chi. Legal F. (2015), 1.
- Distilling Task-Specific Knowledge from BERT into Simple Neural Networks. arXiv:1903.12136 [cs.CL]
- The YouTube Team. 2019. The Four Rs of Responsibility, Part 1: Removing harmful content. https://blog.youtube/inside-youtube/the-four-rs-of-responsibility-remove/
- Petter Törnberg. 2022. How digital media drive affective polarization through partisan sorting. Proceedings of the National Academy of Sciences 119, 42 (2022), e2207159119.
- Manipulating Twitter Through Deletions. In Proceedings of the International AAAI Conference on Web and Social Media, Vol. 16. 1029–1039.
- Twitter Transparency. 2021. Rules Enforcement. https://transparency.twitter.com/en/reports/rules-enforcement.html
- David van Mill. 2021. Freedom of Speech. In The Stanford Encyclopedia of Philosophy (Spring 2021 ed.), Edward N. Zalta (Ed.). Metaphysics Research Lab, Stanford University.
- Social media use and risky behaviors in adolescents: A meta-analysis. Journal of Adolescence 79 (2020), 258–274.
- Megastudy identifying effective interventions to strengthen Americans’ democratic attitudes. (2023).
- Want To Reduce Labeling Cost? GPT-3 Can Help. In Findings of the Association for Computational Linguistics: EMNLP 2021. Association for Computational Linguistics, Punta Cana, Dominican Republic, 4195–4205. https://doi.org/10.18653/v1/2021.findings-emnlp.354
- Magdalena Wojcieszak and Benjamin R Warner. 2020. Can interparty contact reduce affective polarization? A systematic test of different forms of intergroup contact. Political Communication 37, 6 (2020), 789–811.
- Returning is believing: Optimizing long-term user engagement in recommender systems. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 1927–1936.
- Supporting Qualitative Analysis with Large Language Models: Combining Codebook with GPT-3 for Deductive Coding. In Companion Proceedings of the 28th International Conference on Intelligent User Interfaces (Sydney, NSW, Australia) (IUI ’23 Companion). Association for Computing Machinery, New York, NY, USA, 75–78. https://doi.org/10.1145/3581754.3584136
- Kai-Cheng Yang and Filippo Menczer. 2023. Large language models can rate news outlet credibility. arXiv:2304.00228 [cs.CL]
- Effects of credibility indicators on social media news sharing intent. In Proceedings of the 2020 chi conference on human factors in computing systems. 1–14.
- Value-Sensitive Algorithm Design: Method, Case Study, and Lessons. Proc. ACM Hum.-Comput. Interact. 2, CSCW, Article 194 (nov 2018), 23 pages. https://doi.org/10.1145/3274463
- Can Large Language Models Transform Computational Social Science? arXiv:2305.03514 [cs.CL]

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: can we design social media to support healthy democracy? The authors show a new way to teach the AI systems that sort our feeds to care about democratic values—especially reducing “partisan animosity,” which means disliking and attacking people from the other political party. They turn ideas from social science into clear goals the algorithm can follow, then test whether feeds built around those goals make people less hostile without making the app less enjoyable.
Key Objectives and Questions
The paper focuses on two simple goals:
- Can a social media algorithm lower partisan animosity and anti‑democratic attitudes?
- Can it do this without hurting how much people like or use the platform?
It also asks:
- Can we convert trusted social science measures into instructions an AI understands?
- Will an AI that follows these values work as well as careful human reviewers?
How the Research Was Done
Think of a social media feed as a playlist that an algorithm constantly reorders. Today, most feeds are sorted to maximize clicks and likes (engagement). That can push drama and conflict to the top, which can increase political anger.
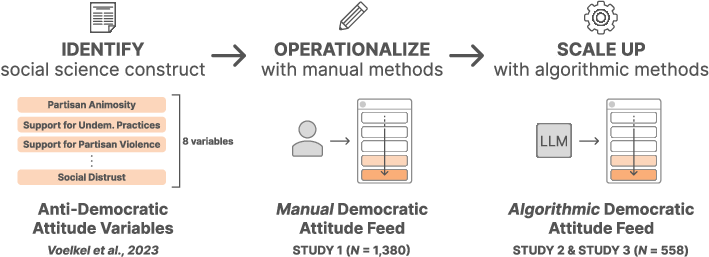
The authors designed a different “goal” for the feed: reduce anti-democratic attitudes. To do that, they used a proven checklist from political science, then taught both human reviewers and an AI to score posts using that checklist.
Step 1: Manually score posts (human judges)
- The team collected real political posts from Facebook using a public tool called CrowdTangle.
- Two trained reviewers read each post and rated how much it encouraged eight anti‑democratic attitudes, using a simple 1–3 scale (3 = strongly promotes it).
- The reviewers agreed with each other a lot (a reliability score called Krippendorff’s alpha was 0.895), which means the checklist was clear and consistent.
- They then re‑ranked feeds so posts that seemed to increase anti‑democratic attitudes appeared lower or were removed/replaced.
The eight attitudes they measured were:
- Partisan animosity (hostility toward the other party)
- Support for undemocratic practices (like rejecting election results)
- Support for partisan violence
- Support for undemocratic candidates
- Opposition to bipartisan cooperation
- Social distrust (mistrust in people generally)
- Social distance (avoiding people from the other party)
- Biased evaluation of politicized facts (rejecting facts that help the other side)
Step 2: Teach an AI to score posts (AI “judge” using a checklist)
- Next, they turned the same checklist into instructions for a LLM (GPT‑4).
- The AI rated each post on the eight attitudes (zero‑shot classification, meaning the AI used instructions without extra training data).
- The AI’s scores matched human scores closely (Spearman’s rho = 0.75), which is strong agreement.
Step 3: Test the redesigned feeds with people
- They ran online experiments with U.S. partisans (Democrats and Republicans).
- Study 1: used human scores to build feeds; 1,380 people.
- Study 3: used the AI’s scores to build feeds; 558 people.
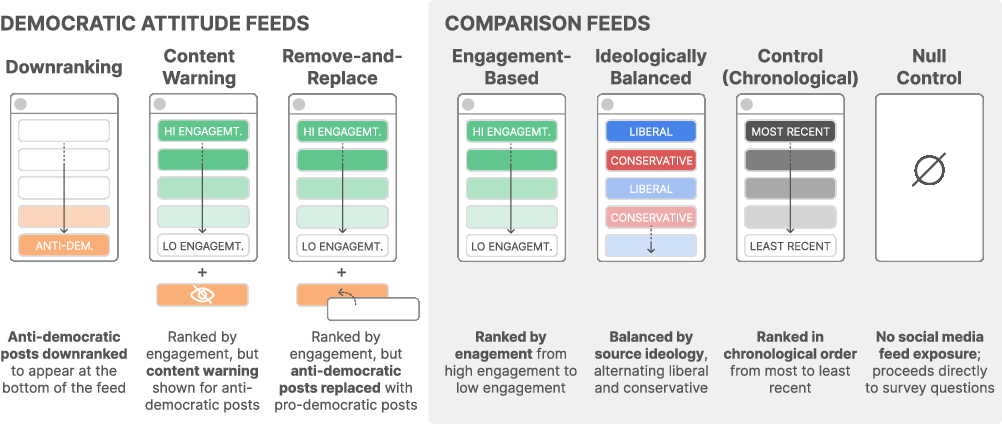
- They compared several feed designs:
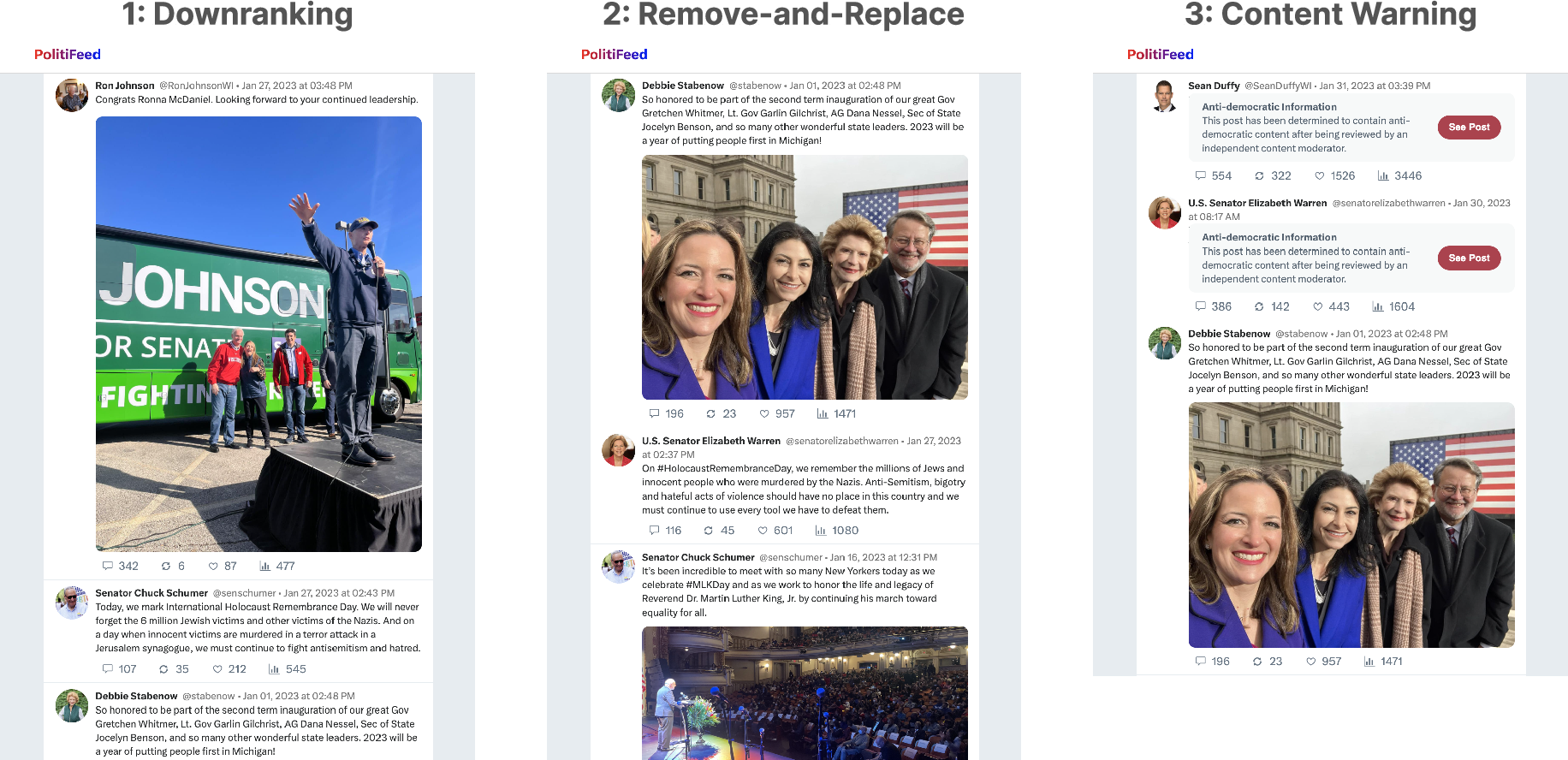
- Downranking: move posts that boost anti‑democratic attitudes lower in the feed.
- Content warning: blur those posts with a warning.
- Remove-and-replace: delete those posts and swap in posts that promote healthier attitudes.
- Engagement-based: sort by likes/shares (a typical current feed).
- Ideologically balanced: mix posts from both parties.
- Chronological: show posts in time order.
- Null control: show no feed (baseline).
Main Findings and Why They Matter
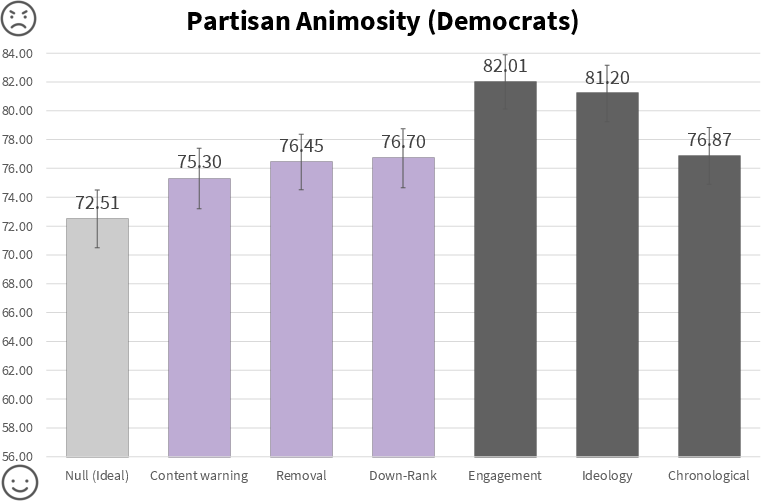
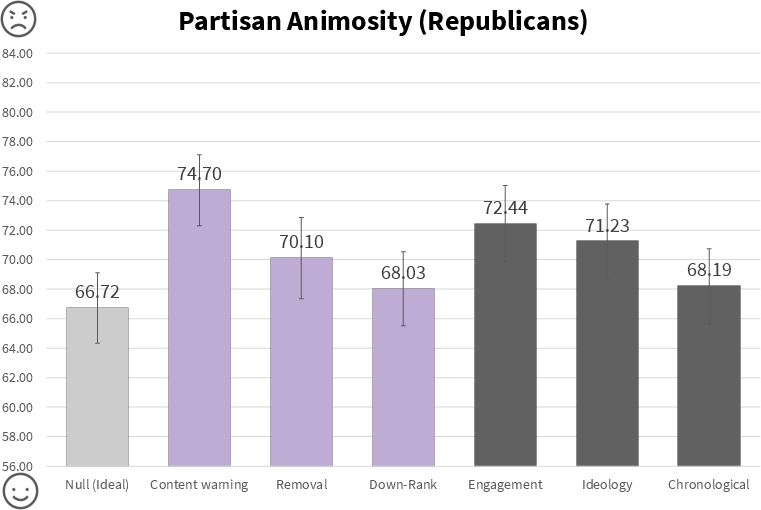
- Downranking and remove‑and‑replace feeds lowered partisan animosity compared to a standard engagement‑based feed.
- Study 1 effect sizes: d = 0.20 (removal) and d = 0.25 (downranking).
- Study 3 (with the AI model): downranking again reduced animosity (d = 0.25).
- Importantly, people didn’t enjoy the feed less and didn’t engage less. This suggests you can make the feed kinder without making it boring.
- They checked free‑speech worries: feeds that re‑ranked or removed posts did not make people feel their speech was being threatened.
- The AI model could scale manual ratings while staying close to human judgments (rho = 0.75), which means this approach can work at large sizes needed for real platforms.
Why this matters: Social media algorithms usually chase engagement, which can reward angry, divisive content. This study shows that if we give the algorithm a new goal—protect democratic values—it can reduce hostility while keeping users satisfied. That’s a big deal for building healthier online spaces.
Implications and Potential Impact
This paper introduces “societal objective functions”—clear, testable goals for algorithms based on trusted social science. It proves you can:
- Translate complex values (like pro‑democracy attitudes) into a scorecard an AI can follow.
- Re‑rank feeds using that scorecard to reduce harmful outcomes (like partisan animosity).
- Scale the approach with AI so it could work in real products.
Beyond democracy, the same method could be used for other values people care about—such as well‑being, cultural diversity, or sustainability—by choosing the right social science measures and building them into the algorithm’s goals. In short, this is a practical path to make social media AIs not just engaging, but also better for society.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper presents a promising method to embed democratic values in social media AIs via societal objective functions, but it leaves several issues unresolved. Future research could address the following specific gaps:
- External validity of interventions: Effects are tested in a simulated, isolated feed (PolitiFeed), not in live platform environments with real-time feedback loops, social network effects, and algorithmic interference (e.g., recommender learning, resharing cascades).
- Short-term exposure only: Outcomes are measured immediately after a one-time exposure to 60 posts; the durability, decay, or cumulative effects of these interventions over days/weeks/months remain unknown.
- Limited participant population: Studies focus on U.S. partisans (Democrats and Republicans). Effects for independents, non-partisans, other political identities, and in other countries and cultural contexts are untested.
- Narrow content source and timeframe: Stimuli are public political Facebook Page posts collected from CrowdTangle over one month (Jan–Feb 2023). Generalization to personal posts, comments, multimodal content (images, video, audio), other platforms (X/Twitter, TikTok, YouTube, Instagram), and broader time windows is unexplored.
- Construct-to-post validity: The eight anti-democratic attitude variables originate from survey measures of people; their translation to post-level “promotion of anti-democratic attitudes” is not validated against real-world outcomes (e.g., changes in behavior, cross-party interactions), raising questions about criterion and predictive validity.
- Aggregation and weighting choices: The approach sums eight subscales with equal weights into a single score. No sensitivity analysis explores alternative weightings, multi-objective optimization (e.g., Pareto front), or context-dependent weighting (e.g., election periods, crisis events).
- Error cost analysis: The paper does not quantify harms from false positives/negatives (e.g., mistakenly downranking legitimate reporting, satire, or minority political expression) or propose safeguards to mitigate misclassification damage.
- Fairness and ideological balance: Potential asymmetric impacts on different ideologies, minority groups, or issue domains are not audited. It remains unclear whether the model disproportionately penalizes one party or specific rhetorical styles.
- Cultural and linguistic generalization: Prompts and labels are in English; applicability to other languages and culturally specific political discourse is untested.
- LLM dependence and robustness: The democratic attitude model relies on GPT-4 zero-shot prompts. Stability across model versions, vendor changes, prompt drift, reproducibility, and latency/cost constraints for production-scale deployment are not assessed.
- Benchmarking against alternative modeling approaches: No comparison to supervised classifiers, rule-based systems, or hybrid human-in-the-loop pipelines; the relative accuracy, interpretability, and operational costs of alternatives are unknown.
- Adversarial resilience: The model’s susceptibility to gaming (evasion through phrasing, coded language, irony, deliberate ambiguity) and its ability to detect coordinated manipulation campaigns are not evaluated.
- Side effects on information diversity and civic engagement: Downranking/removal may reduce exposure to important but uncomfortable news, potentially affecting civic knowledge, issue salience, or engagement; these trade-offs are not measured.
- Perceptions of censorship and legitimacy: While the study reports no increased perceived free-speech threats in the lab, real-world perception dynamics (media coverage, political elites’ framing, platform trust) could differ significantly and are untested.
- Engagement and business metrics: Lab-based satisfaction and engagement proxies may not reflect long-term retention, creator incentives, revenue impacts, or ecosystem health on production platforms.
- Governance and value pluralism: Who defines “democratic values,” how they evolve over time, and how conflicting societal values are arbitrated (e.g., free expression vs. harm reduction) are unresolved; participatory, multi-stakeholder governance mechanisms are not specified.
- Operational integration: The paper does not address how to integrate societal objective functions with existing multi-objective ranking pipelines (e.g., engagement, watch time, quality), including constraint handling, online learning, and A/B testing infrastructure.
- Legal and policy implications: The legal risks of remove-and-replace or downranking (e.g., transparency obligations, viewpoint discrimination concerns, jurisdictional differences) are not analyzed.
- Dataset representativeness and size: The labeled inventory is 405 posts, sampled across engagement buckets. Coverage of niche communities, local politics, and low-engagement content is limited; effects may vary with different content distributions.
- Annotation process limitations: Ratings are produced by two expert annotators with high agreement; generalizability to larger, more diverse annotator pools and the reproducibility of the codebook across teams are uncertain.
- Heterogeneous treatment effects: Beyond “holds for conservatives and liberals,” finer-grained heterogeneity (e.g., age, media literacy, political knowledge, extremity, trust) and context-specific moderators are not explored.
- Mechanisms of change: The psychological pathways by which re-ranking reduces animosity (e.g., reduced exposure to incitement, increased exposure to bridging content, altered affect) are not measured, limiting theory-building and intervention refinement.
- Coverage of all eight subscales: The abstract emphasizes reductions in partisan animosity; impacts on other subscales (support for undemocratic practices, violence, etc.) are not consistently reported or decomposed, leaving unclear which sub-dimensions are most influenced.
- Content warning UX design: The specific warning design, its interpretability, and potential backfire effects (e.g., curiosity, reactance) are not analyzed; alternative UX variants could produce different outcomes.
- Supply constraints for “pro-democratic” content: Remove-and-replace feasibility depends on sufficient inventory; dynamic supply, topical relevance, and content freshness are not addressed.
- Privacy and data rights: The implications of using LLMs to process user-generated content (data governance, consent, retention, cross-border data flows) are not discussed.
- Multi-value extension roadmap: While the paper proposes broader societal objectives (e.g., wellbeing, diversity), concrete methodologies for value elicitation, construct selection, conflict resolution, and cross-value optimization remain open.
- Synergy and interactions with existing interventions: Combined effects with ideologically balanced feeds, bridging-based ranking, or misinformation defenses are not tested; complementary or antagonistic interactions remain unknown.
- Calibration and thresholding: The paper uses a 3-point scale per subscale summed to a total score; optimal thresholds for downranking/removal, confidence calibration, and uncertainty-aware decisions are not identified or evaluated.
Glossary
- Affective polarization: Emotional hostility toward members of the opposing political group, distinct from disagreement on issues. "we focus on affective polarization instead of issue polarization"
- Anti-democratic attitudes: A composite social science construct spanning eight variables that assess willingness to engage in democratic norms. "This measure, which was recently tested in a large study that received widespread attention~\cite{voelkel2023megastudy}, spans eight variables that describe willingness to engage in good faith in the democratic process: partisan animosity, support for undemocratic practices, support for partisan violence, support for undemocratic candidates, opposition to bipartisanship, social distrust, social distance, and biased evaluation of politicized facts."
- Biased evaluation of politicized facts: Tendency to judge facts through a partisan lens that favors one’s own side. "biased evaluation of politicized facts"
- Bridging-based ranking: A feed-ranking approach intended to surface content that builds trust across divides. "bridging-based ranking to build trust across divides"
- Chronological feed: A feed ordered by time rather than algorithmic engagement. "a traditional engagement-based feed or a chronological feed"
- Constitutional AI: A technique to steer AI models using a set of explicit principles. "such as Constitutional AI~\cite{bai2022constitutional} and reinforcement learning from human feedback (RLHF)~\cite{ouyang2022training} present technical methods for holistically steering AI models"
- Content moderation: Policies and models for detecting and removing content that violates platform rules. "Content moderation models are a common strategy to ensure that content does not violate platform policies or community guidelines~\cite{gillespie2018custodians}"
- Content Warning feed: A feed design that masks certain posts with warnings while preserving ranking. "Content Warning feed which mirrors designs commonly used by real-world social media platforms to mask harmful content"
- CrowdTangle: A Meta-hosted tool for monitoring public Facebook posts and their engagement. "CrowdTangle, a tool hosted by Meta that allows external parties to monitor public posts on Facebook"
- Democratic attitude feed: A re-ranked social media feed that optimizes for pro-democratic outcomes using a model’s scores. "The democratic attitude feeds incorporate our anti-democratic attitude model with either: (1) Downranking, (2) Content Warning, or (3) Remove-and-Replace feeds."
- Democratic attitude model: An AI model that scores posts on their propensity to promote anti-democratic attitudes. "create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes"
- Downranking: A ranking intervention that lowers the position of content deemed harmful or undesirable. "Removal () and downranking feeds () reduced participants' partisan animosity"
- Echo chambers: Information environments that isolate users within ideologically homogeneous content. "echo chambers (or selective exposure)"
- Engagement-Based feed: A feed ranked by interactions such as likes, shares, and comments. "Engagement-Based feed"
- Feeling thermometer: A survey measure of warmth or favorability toward a group. "measure this with ratings of warmth on a feeling thermometer"
- G*Power: Statistical software used to conduct power analyses for experimental design. "a priori power analysis using G*Power determined that a total sample of at least 1,369 participants would be needed"
- Ideologically Balanced feed: A feed designed to present content from multiple political perspectives. "Ideologically Balanced feed"
- Inter-coder reliability: A statistic assessing agreement between multiple human annotators. "The two independent coders achieved strong inter-coder reliability (Krippendorff's = .895)"
- Krippendorff's alpha: A reliability coefficient for measuring agreement among annotators. "Krippendorff's = .895"
- LLM: A class of AI systems trained on vast text corpora to perform language tasks. "LLMs such as GPT-4"
- Megastudy: A large multi-intervention study conducted at scale to compare effects. "The Voelkel et al. megastudy found that almost all of their interventions successfully reduced partisan animosity"
- Null control: An experimental condition where participants receive no treatment or stimulus. "a Null Control where no feed is shown"
- Open Science Framework (OSF): A platform for preregistering studies and sharing research materials. "We pre-registered our research questions and hypotheses on Open Science Framework (OSF)"
- Operationalize: To translate a theoretical construct into measurable procedures or variables. "Operationalize the construct with manual rating methods"
- Partisan animosity: Negative thoughts, feelings, and behaviors toward the opposing political group. "A key outcome of interest in a healthy democracy is partisan animosity: negative thoughts, feelings and behaviours towards a political out-group."
- Partisan sorting: A mechanism of polarization driven by exposure beyond local networks, rather than isolation. "partisan sorting, whereby polarization is not driven by isolation"
- Partyism: Hostility and aversion toward a specific political party. "others introduce new terms or measurements such as 'partyism' to describe the hostility and aversion to a certain political party"
- Reinforcement Learning from Human Feedback (RLHF): A method to align AI behavior using human-provided preferences. "reinforcement learning from human feedback (RLHF)~\cite{ouyang2022training}"
- Remove-and-Replace feed: A feed where harmful posts are removed and replaced with pro-democratic content. "Remove-and-Replace feed (i.e., ranked by engagement, but anti-democratic posts are replaced with pro-democratic posts sourced from our dataset inventory ( = 405))"
- Selective exposure: The tendency to consume information that aligns with existing beliefs. "echo chambers (or selective exposure)"
- Societal objective function: A method to encode social science constructs as AI optimization targets. "We introduce the term societal objective function to refer to our method of translating well-established social science constructs into an AI objective function."
- Spearman's rho: A nonparametric correlation coefficient based on rank-order. "Spearman's = .75"
- Systematic random sampling: A sampling technique selecting items at regular intervals from an ordered list. "We then use the systematic random sampling method to select a final inventory"
- Zero-shot prompting: Instructing a model to perform a task without task-specific training examples. "zero-shot prompting with a LLM"
Practical Applications
Immediate Applications
Below is a concise set of practical, deployable use cases that can be implemented with today’s tooling (LLMs, ranking systems, content moderation pipelines), drawing directly from the paper’s method (societal objective functions), model (democratic attitude scores), and empirical findings (downranking/removal reduced partisan animosity without harming engagement).
- Social media feed re-ranking to mitigate partisan animosity
- Sector: Software (social media/recommenders), Civic tech
- What: Integrate the democratic attitude model as a scoring feature in ranking pipelines to downrank content that promotes anti-democratic attitudes; optionally use removal-and-replacement or content warnings for high-risk items.
- Tools/Workflows: LLM-based scoring service; codebook-derived prompts; feature ingestion into multi-objective rankers; A/B testing with attitudinal outcome metrics; UI patterns for warnings and replacements.
- Assumptions/Dependencies: Access to posts and ranking stack; LLM inference reliability and latency; calibration to local contexts; governance to address free-speech concerns; willingness to trade minor engagement shifts for societal benefits.
- Brand safety and ad suitability filters
- Sector: Advertising/Ad tech
- What: Use the democratic attitude model to prevent ad placement adjacent to content that elevates anti-democratic attitudes, protecting brands and reducing systemic risks.
- Tools/Workflows: Pre-bid/post-bid suitability checks; supply quality scoring; integration with existing brand safety taxonomies.
- Assumptions/Dependencies: Platform inventory access; standardized thresholds; clear advertiser policies; potential partisan bias audits.
- Content moderation triage and review prioritization
- Sector: Trust & Safety
- What: Complement policy-based moderation by triaging borderline content for human review using anti-democratic attitude scores; accelerate escalation for posts that score high on support for undemocratic practices or partisan violence.
- Tools/Workflows: Queue prioritization; reviewer dashboards; policy decision logs; feedback loops to refine prompts.
- Assumptions/Dependencies: Reviewer capacity; clarity on non-policy but socially risky content; safeguards against over-removal/censorship perceptions.
- “Democracy-friendly mode” user toggle
- Sector: Consumer product (social platforms), UX
- What: Offer an opt-in setting that prioritizes pro-democratic content and downranks content associated with animosity, violence, or undemocratic norms—shown in the paper to reduce partisan animosity without hurting experience/engagement.
- Tools/Workflows: User settings; on-device or server-side re-ranking; transparent explanations; preference logging.
- Assumptions/Dependencies: User acceptance; explainability; impact monitoring; localized codebooks.
- Creator-side “post risk scorecard” and rewrite assistant
- Sector: Creator tools, Publishing, Newsrooms
- What: Provide authors with pre-publication scores across the eight sub-dimensions (e.g., partisan animosity, support for violence) plus suggested edits to reduce inflammatory framing.
- Tools/Workflows: LLM scoring + generative rewrite suggestions; CMS plugins; editorial QA checklists.
- Assumptions/Dependencies: Editorial buy-in; potential tension with persuasive goals; transparency to avoid chilling effects.
- News and aggregator recommendation safeguards
- Sector: Media/News, Search and video platforms
- What: Incorporate anti-democratic attitude scoring into news/homepage/video recommendations to avoid over-amplifying content that inflames out-group hostility while maintaining diversity of viewpoints.
- Tools/Workflows: Multi-objective ranking (engagement + societal measures); slate composition constraints; periodic audits.
- Assumptions/Dependencies: Balancing viewpoint diversity with toxicity reduction; measurement across formats (text, video thumbnails, headlines).
- Academic and product experimentation using societal objective functions
- Sector: Academia, R&D, Product research
- What: Use the method to turn validated constructs into measurable objectives (e.g., wellbeing, trust, misinformation skepticism) and run controlled experiments on their feed-level impacts.
- Tools/Workflows: Codebook-to-prompt pipelines; preregistration; multi-arm experiments; effect-size reporting (e.g., d≈.20–.25).
- Assumptions/Dependencies: Construct validity; reproducibility across contexts; IRB/ethics oversight.
- Regulatory risk assessments and dashboards
- Sector: Policy/Compliance (e.g., EU DSA), Platform governance
- What: Track platform-level systemic risk (partisan animosity, support for undemocratic practices) with periodic scoring and publish aggregated metrics for regulators/auditors.
- Tools/Workflows: Risk dashboards; sampling methodologies; third-party audit APIs.
- Assumptions/Dependencies: Legal frameworks; standardized reporting; auditor independence; potential politicization of metrics.
- Browser extensions for personal feed hygiene
- Sector: Daily life, Civic tech
- What: Client-side re-ranking or overlays that blur/annotate posts flagged for anti-democratic attitudes, with user-adjustable sensitivity.
- Tools/Workflows: Extension-based DOM analysis; LLM API calls; local caching; simple explainers.
- Assumptions/Dependencies: API cost; latency; site terms of use; user privacy.
Long-Term Applications
The following applications require further research, scaling, governance, or standardization—extending the paper’s approach to broader values, larger populations, and durable policy/industry structures.
- Multi-objective recommender systems that operationalize plural societal values
- Sector: Software (recommenders), AI alignment
- What: Formalize rankings that jointly optimize engagement, satisfaction, pro-democratic attitudes, wellbeing, diversity, and misinformation resilience; provide transparent trade-off controls and participatory value-setting.
- Tools/Workflows: Value elicitation processes; Pareto optimization; fairness-aware constraints; stakeholder deliberation interfaces.
- Assumptions/Dependencies: Consensus on values; governance legitimacy; robust longitudinal evaluation.
- Standardized societal objective function libraries and benchmarks
- Sector: Open-source, Standards bodies
- What: Create canonical codebooks, prompt templates, datasets, and evaluation suites for constructs (democracy, mental health, extremism, climate misinformation), enabling cross-platform comparability.
- Tools/Workflows: Shared repositories; versioned prompt packs; multilingual datasets; inter-rater and model-human agreement benchmarks.
- Assumptions/Dependencies: Community coordination; funding; multilingual/cultural adaptation; avoiding lock-in to specific vendors.
- Field deployments and longitudinal impact studies
- Sector: Academia, Platforms, Public-interest research
- What: Measure real-world, long-horizon effects (months/years) of value-aligned feeds on partisan animosity, civic engagement, and trust—beyond short lab exposures.
- Tools/Workflows: Cohort tracking; quasi-experiments; synthetic controls; mixed methods (surveys + behavioral logs).
- Assumptions/Dependencies: Data-sharing agreements; privacy-preserving analytics; attrition management; external shocks (elections).
- Regulatory frameworks that mandate systemic risk mitigation via ranking objectives
- Sector: Policy/Regulation (e.g., EU DSA, national regulators)
- What: Codify expectations that large platforms assess, mitigate, and report societal harms; endorse auditability of objective functions; allow third-party oversight.
- Tools/Workflows: Compliance APIs; independent auditors; policy toolkits for acceptable objectives; transparency reports.
- Assumptions/Dependencies: Legal clarity; avoiding overreach or politicized enforcement; safe harbor for experimentation.
- Creator-side “democracy linter” and style transfer models
- Sector: Publishing, Generative AI
- What: Train models to automatically suggest language reframing that preserves message content while reducing signals of animosity or support for undemocratic practices.
- Tools/Workflows: Fine-tuned generative models; constrained optimization for tone; human-in-the-loop editorial review.
- Assumptions/Dependencies: Avoiding homogenization/censorship; maintaining viewpoint diversity; measuring unintended effects.
- Cross-cultural and multilingual adaptation of constructs
- Sector: Global platforms, Localization
- What: Translate codebooks and prompts to local political contexts (different parties, norms, histories), and validate with local experts and participants.
- Tools/Workflows: Participatory co-design; local IRBs/ethics boards; regional evaluation cohorts; bias/accuracy analysis per locale.
- Assumptions/Dependencies: Contextual nuance; varying legal regimes; model performance across languages and scripts.
- Integration with foundation models and RLHF for value-aware feed AI
- Sector: AI systems
- What: Jointly train ranking AIs with societal objective signals (e.g., via reinforcement learning or constitutional objectives) so alignment is native, not bolted on.
- Tools/Workflows: Policy reward models; offline RL from logged data; simulators for safe training; guardrails for gaming/feedback loops.
- Assumptions/Dependencies: Robust reward design; avoidance of Goodhart’s law; monitoring for emergent behaviors.
- Public APIs and third‑party auditor ecosystems
- Sector: Platform governance, Civic tech
- What: Expose anonymized, rate-limited scoring endpoints and datasets so civil society and researchers can independently assess platform impacts.
- Tools/Workflows: Audit sandboxes; reproducible pipelines; certification programs; data trusts.
- Assumptions/Dependencies: Privacy; legal liability; preventing adversarial exploitation.
- Application to adjacent harms (health misinformation, extremism, climate denial)
- Sector: Healthcare, Public safety, Environment
- What: Extend the societal objective function method to validated constructs (e.g., evidence acceptance, extremist cues), enabling proactive mitigation in ranking.
- Tools/Workflows: Domain-specific codebooks; expert panels; high-stakes evaluation; cross-sector partnerships.
- Assumptions/Dependencies: Construct validity across domains; false positive costs; crisis/rapid response scenarios.
- Organizational governance and ESG reporting on algorithmic impacts
- Sector: Corporate governance, Finance/ESG
- What: Board-level oversight and KPIs for societal outcomes; integrate “democratic attitude impact” into ESG disclosures and risk registers.
- Tools/Workflows: Balanced scorecards; assurance audits; investor communications.
- Assumptions/Dependencies: Materiality standards; consistent metrics; alignment with fiduciary duties.
Notes on general feasibility: The paper’s experiments found that downranking and removal/replacement reduced partisan animosity (d≈.20–.25) without degrading engagement or perceived experience, and LLM-based scoring correlated strongly with manual labels (ρ≈.75). Real-world deployment should account for generalization beyond U.S. partisans and short-term exposure; the method is adaptable to other values but requires robust validation, stakeholder governance, and transparency to maintain user trust and avoid unintended censorship or bias.
Collections
Sign up for free to add this paper to one or more collections.