- The paper introduces Text2KGBench that evaluates LLMs in generating ontology-compliant knowledge graphs from text.
- It presents two datasets and rigorous metrics, including precision, recall, and F1 score, to assess fact extraction and ontology conformity.
- Baseline results reveal intermediate LLM performance, highlighting the need for refined prompt engineering and reduced hallucinations.
Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text
The paper "Text2KGBench: A Benchmark for Ontology-Driven Knowledge Graph Generation from Text" presents a comprehensive benchmark aimed at evaluating LLMs in the generation of Knowledge Graphs (KGs) from text, particularly when guided by an ontology. This benchmark, known as Text2KGBench, is designed to assess the competence of such models in extracting facts from natural language texts that are compliant with specified ontologies, serving both academic and practical advancements in the field of neuro-symbolic AI.
Ontology-Driven Knowledge Graph Generation
The primary aim of Text2KGBench is to facilitate ontology-driven KG generation that leverages the capabilities of LLMs to extract structured information (Figure 1). This involves extracting facts from unstructured data while adhering to the constraints imposed by domain-specific ontologies. The benchmark provides two datasets: Wikidata-TekGen and DBpedia-WebNLG, sourced from TekGen and WebNLG corpora, respectively, each aligning sentences with corresponding ontological structures for KG generation.
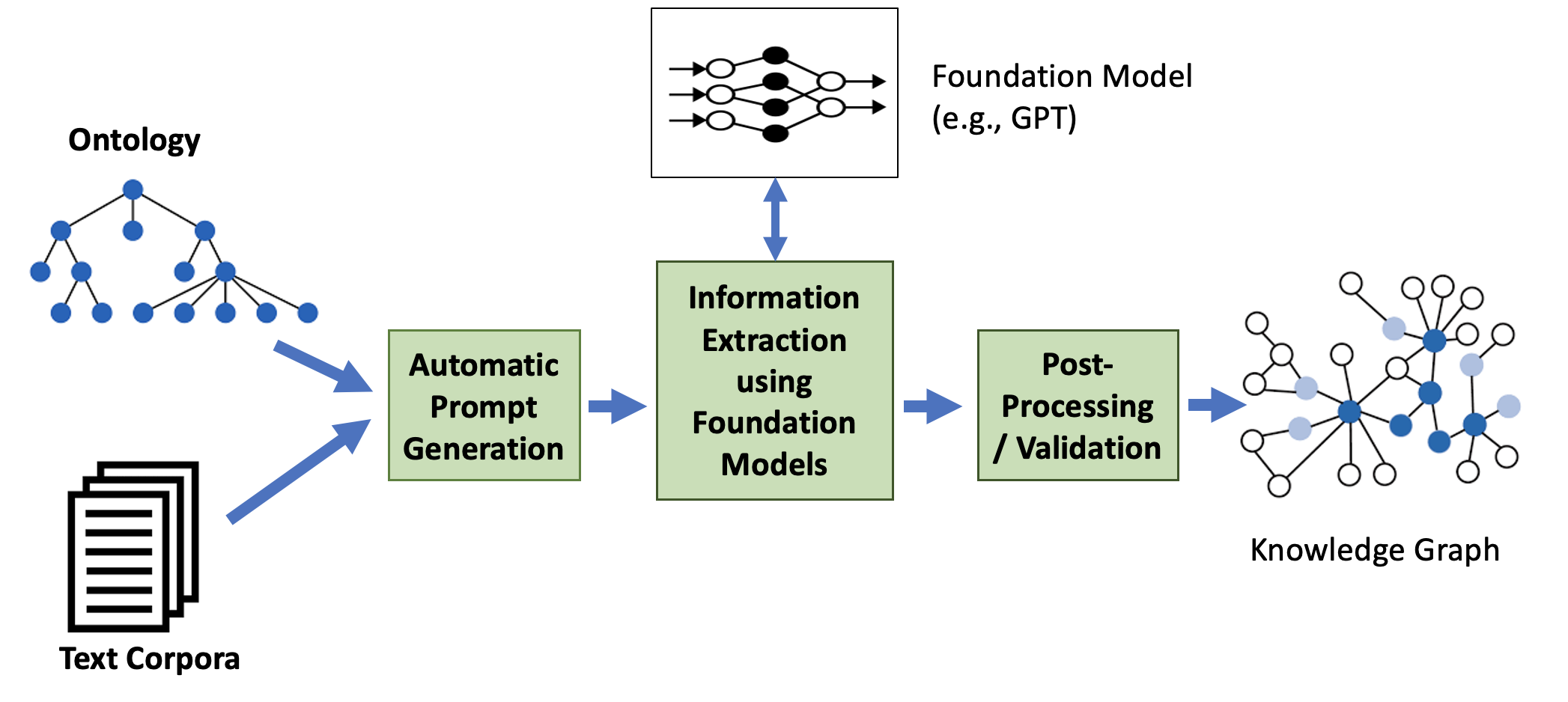
Figure 1: Generating knowledge graphs from text guided by ontologies.
Datasets and Evaluation Metrics
Text2KGBench defines a set of evaluation metrics to measure an LLM's ability to extract accurate facts, conform to ontological constraints, and minimize hallucinations. Fact extraction accuracy is assessed via precision, recall, and F1 score, while ontology conformance measures the extent to which output triples align with the given ontology. Hallucination is further dissected into metrics for subject, relation, and object, examining the model's fidelity to source content.
Two datasets underpin the benchmark:
- Wikidata-TekGen: Consists of 10 ontologies with 13,474 sentences. It allows for exploration of various domain-specific relations and concepts derived from Wikidata.
- DBpedia-WebNLG: Composed of 19 ontologies with 4,860 sentences, this dataset supports the testing of LLMs against a wide range of semantic relations.
Baselines and Results
The paper establishes evaluation baselines using two open-source models, Vicuna-13B and Alpaca-LoRA-13B (Figure 2). Both models were tested with automatic prompt generation to delineate LLM capabilities in structured information extraction. Baseline results indicate the intermediate performance of these models, especially in handling complex instructions for fact extraction from natural language.

Figure 2: An example prompt for an instruction fine-tuned LLM and the generated output from the LLM model.
The performance analysis reveals that existing models exhibit substantial room for improvement, particularly in reducing hallucinations and improving accuracy in fact extraction. The results underscore the importance of refining prompt engineering and exploring the synergy between LLMs and Semantic Web technologies.
Future Work and Impact
This benchmark is a foundational tool for researchers focusing on the intersection of LLMs and ontology-based information extraction. Future work involves scaling the benchmark to accommodate larger ontologies and incorporating reasoning capabilities within LLM frameworks. The authors also highlight the necessity of addressing biases inherent in LLM-generated KGs, which can have significant implications in real-world applications.
The introduction of Text2KGBench to the research community provides a valuable resource for evaluating and advancing state-of-the-art models in ontology-driven KG generation. The benchmark is expected to inspire further research in neuro-symbolic AI, bridging the gap between unstructured natural language and structured semantic representations.
Conclusion
Text2KGBench offers a robust framework for assessing the efficacy of LLMs in ontology-driven KG generation. By providing comprehensive datasets and evaluation metrics, the benchmark serves as a catalyst for advancing the integration of LLMs with ontological principles, promising improvements in domains requiring precise and principled information extraction from text.