OLaLa: Ontology Matching with Large Language Models
Abstract: Ontology (and more generally: Knowledge Graph) Matching is a challenging task where information in natural language is one of the most important signals to process. With the rise of LLMs, it is possible to incorporate this knowledge in a better way into the matching pipeline. A number of decisions still need to be taken, e.g., how to generate a prompt that is useful to the model, how information in the KG can be formulated in prompts, which LLM to choose, how to provide existing correspondences to the model, how to generate candidates, etc. In this paper, we present a prototype that explores these questions by applying zero-shot and few-shot prompting with multiple open LLMs to different tasks of the Ontology Alignment Evaluation Initiative (OAEI). We show that with only a handful of examples and a well-designed prompt, it is possible to achieve results that are en par with supervised matching systems which use a much larger portion of the ground truth.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces OLaLa, a system that helps computers figure out when two different databases are talking about the same thing, even if they use different words. These databases are called “ontologies” or “knowledge graphs.” Think of them like big, structured dictionaries or maps of facts. OLaLa uses LLMs—AI systems that read and write text—to match concepts across those dictionaries much more like a human would.
What questions did the researchers ask?
In simple terms, the authors wanted to know:
- Can open-source LLMs match concepts from different ontologies well, using only their text descriptions?
- How should we “ask” the AI (what prompt to use) to get the best answers?
- Is it better to show the AI a few examples first (“few-shot”) or none at all (“zero-shot”)?
- Which LLMs work best?
- How do we turn the structure of a knowledge graph into text the AI can understand?
- How do we combine everything to get accurate, reliable matches?
How did they do it?
To make this work, OLaLa follows a step-by-step process. You can think of it like trying to match people from two schools’ student lists when the names and descriptions may differ.
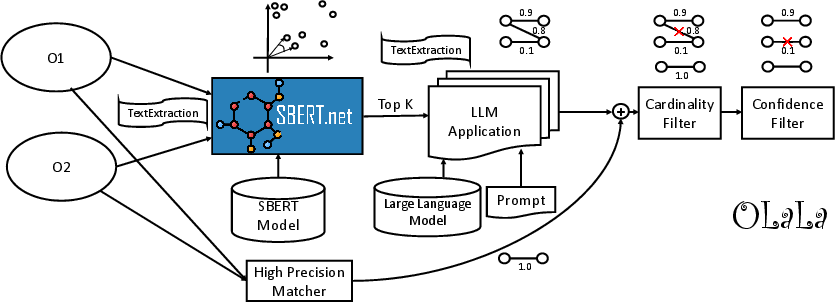
Step 1: Pick likely pairs (candidate generation)
- Problem: You can’t ask the AI to compare every possible pair—it’s too slow.
- Solution: First, OLaLa guesses which pairs are most likely matches using a tool called Sentence-BERT (SBERT). SBERT turns text (like a label or short description) into a point in a mathematical space. Texts with similar meaning end up close together. This way, the system finds a small set of “likely matches” to check more carefully later.
Plain analogy: It’s like grouping students who have similar hobbies and classes before comparing them in detail.
Step 2: Ask the LLM with clear instructions (prompts)
- The system writes short “instructions” for the LLM, called a prompt. For example: “Do these two descriptions refer to the same thing? Answer yes or no.”
- Sometimes the prompt includes a few examples first (few-shot), like showing the AI what a correct match and a non-match look like. This often improves accuracy.
Analogy: Teaching by example—“Here are 3 good pairs and 3 bad pairs; now try this new one.”
Step 3: Two ways to ask the AI
- Binary decision: Ask “Are these two the same? yes/no.”
- Multiple choice: Show one source item and a small list of possible matches, and ask the LLM to pick the best one or say “none.”
Both methods work; the paper found the simple yes/no style usually gave better accuracy, though multiple-choice could be faster.
Step 4: Extra helpers after the AI answers
- High-precision matcher: A quick tool that matches exact same names (after simple cleanup like lowercasing). This catches the easy wins.
- Filters:
- 1-to-1 rule: Make sure each item is matched to at most one item, so you don’t get duplicates.
- Confidence filter: Keep only matches where the AI seems confident.
Tools and models they used
- Open-source LLMs based on Llama 2 (no closed APIs like ChatGPT), so results are reproducible.
- The MELT framework to run and evaluate everything.
- Standard test sets from the OAEI (Ontology Alignment Evaluation Initiative), which is like a public benchmark competition for ontology matching systems.
What did they find?
- With a well-written prompt and only a few example matches (few-shot), OLaLa can perform as well as, or close to, top systems that require much more training data.
- The best results came from a large open-source model (Llama-2-70b-instruct variant) plus a good few-shot prompt.
- Turning graph data into simple text (like labels or short RDF summaries) helps the LLM understand the concepts.
- Finding likely pairs with SBERT first is crucial—using around 5 nearest candidates per item gave a good balance between thoroughness and speed.
- Multiple-choice prompting is faster but usually a bit less accurate than yes/no decisions.
- Trade-off: LLM-based matching is often slower than traditional methods, especially on big datasets.
In concrete terms, OLaLa ranked among the top systems in several OAEI test cases and sometimes matched or closely approached the best-performing tools, despite using very little training data and relying mainly on text.
Why does this matter?
- Less training needed: Instead of training special models for every dataset, you can guide an LLM with a few examples and a good prompt to get strong results.
- More human-like matching: LLMs can understand and reason about text, so they can match concepts even when the wording is different (“heart attack” vs “myocardial infarction”).
- Open and reproducible: Using open-source models avoids problems with closed APIs (like changing models or costs).
- Practical impact: This can make it easier to connect information across different organizations, websites, and scientific fields—improving search, data analysis, and knowledge sharing.
Simple takeaway: With careful prompting and a smart pipeline, open-source LLMs can help different data systems “speak the same language,” making it easier to combine and use information. The next steps are to make it faster, scale to bigger datasets, automatically pick the best settings, and possibly generate human-friendly explanations of why two items match.
Collections
Sign up for free to add this paper to one or more collections.

