- The paper introduces an automated never-ending UI learner that continuously collects live interaction data to update semantic models without human annotation.
- It employs innovative heuristics for tappability, draggability, and screen similarity, achieving improved F1 scores compared to static annotation baselines.
- The distributed crawler architecture effectively overcomes static dataset limitations, offering scalable, real-time enhancements for app accessibility and automation.
Never-ending Learning of User Interfaces
This paper introduces the concept of "Never-ending Learning of User Interfaces" through an automated system, the Never-ending UI Learner, which continuously collects data from mobile applications without needing human-annotated datasets. The research focuses on learning semantics like tappability, draggability, and screen similarity over sustained app interactions, aiming to improve machine learning models utilized for app accessibility and automation.
Introduction to Never-ending Learning
Recent advancements integrate ML into mobile UI analysis, often relying on static screenshots labeled manually—which is inherently costly and prone to errors, especially when annotating properties like tappability. The Never-ending UI Learner circumvents these limitations using real-time interactions to train models continually, thus significantly enlarging the scope and accuracy of datasets available for training UI semantic models. Over 5,000 device-hours of app crawling tests underline its efficiency in recognizing and updating semantic properties across screens—predominantly without human intervention.
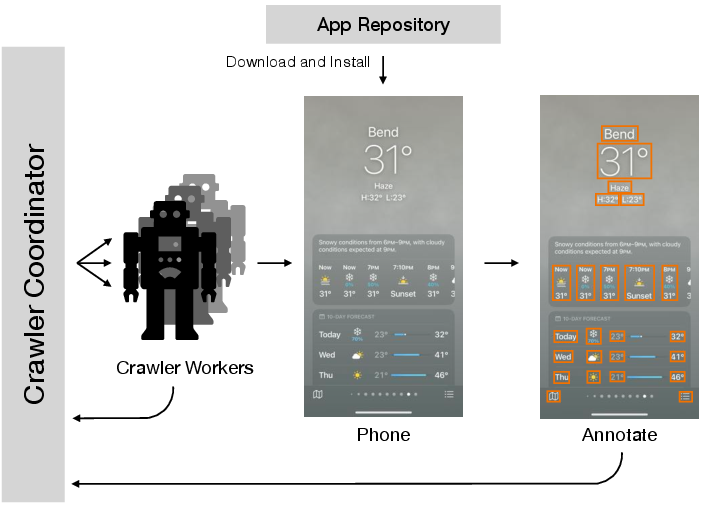
Figure 1: Architecture of our Never-ending UI Learner. The Never-ending UI Learner is a parallelizable mobile app crawler which consists of a coordinator-worker architecture. The crawler coordinator distributes crawls to workers and maintains the dataset. Each crawler worker is connected to a programmatically controlled mobile device which collects data and runs data post-processing.
Investigation into UI modeling datasets illustrates a reliance on static datasets, which require extensive manual annotation [rico, frontmatterKuznetsov]. This research differentiates itself by generating annotations through autonomous exploration of live applications, producing consistently updated data aligned with evolving app designs. The paper also intersects with computational interaction models and continual machine learning techniques [mitchellNELL]. Reinforcement Learning methods in UI interaction are traditionally limited to predefined scenarios, while this paper's system permits exploration across dynamic environments.
Design and Architecture
The Never-ending UI Learner's infrastructure operates through a distributed crawler architecture, categorizing tasks between coordinator servers and crawler workers. The system effectively uses VNC protocol for device interaction, enhancing generalization across platforms while ensuring privacy and reliability in its operations.
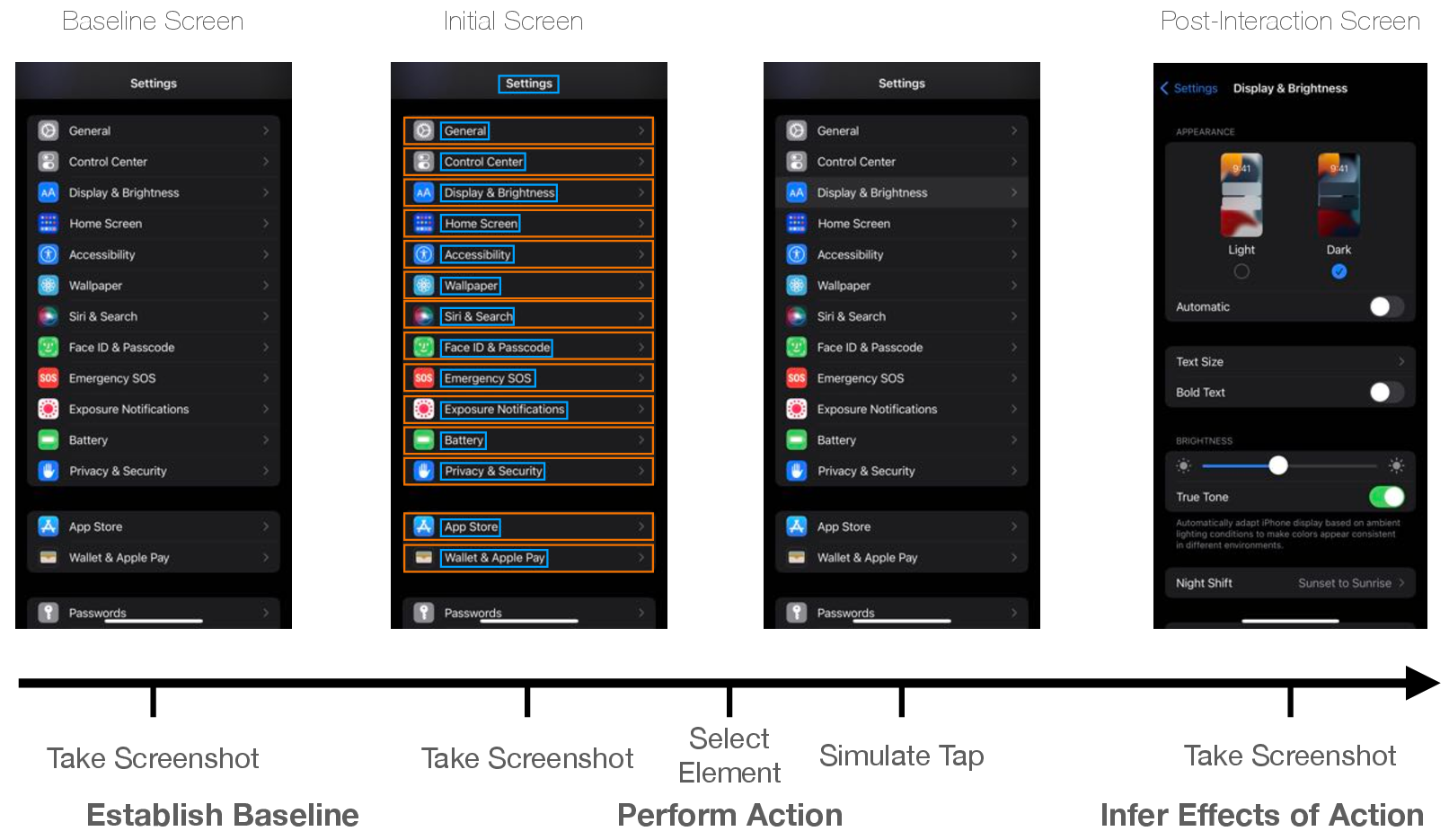
Figure 2: This figure visualizes the steps to our tappability heuristic. When the crawler arrives at a new screen, it takes two screenshots separated by 5 seconds as a baseline of visual change. Then, a detected UI element is chosen and sent a tap. After waiting for the screen to settle, a post-interaction screenshot is used to infer the effects of the action.
Implementation of UI Semantic Models
Tappability Heuristic
A significant contribution of the paper is a tappability prediction model trained using heuristic-labeled examples derived from interaction data. This method provides an innovative approach to overcoming the inaccuracies found in static annotations.
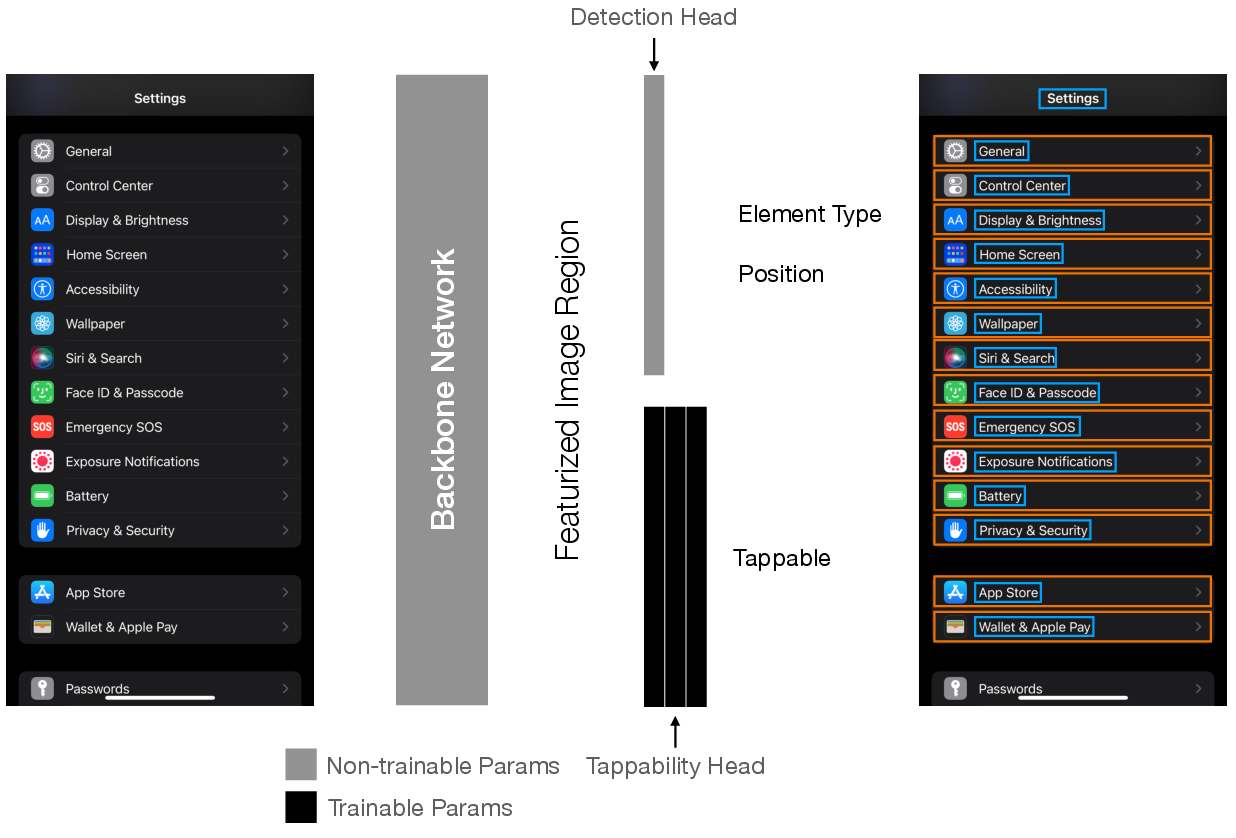
Figure 3: Architecture of our tappability model. The tappability model is designed as a "head," which is a sub-network of the UI element detection model. The element detector featurizes image regions in an input screenshot using a sliding window, which results in a featurized image embedding for each detected object. The main branch of the network (top) feeds in the embedding to determine the region's element type and position. We feed in the same element embedding into a separate feedforward network (bottom) to predict the probability that it is tappable.
Draggability Heuristic
Detecting draggable elements through emulated interaction confirms its practicability by incorporating broad contextual cues during training, compared to isolated, visually-oriented annotations.
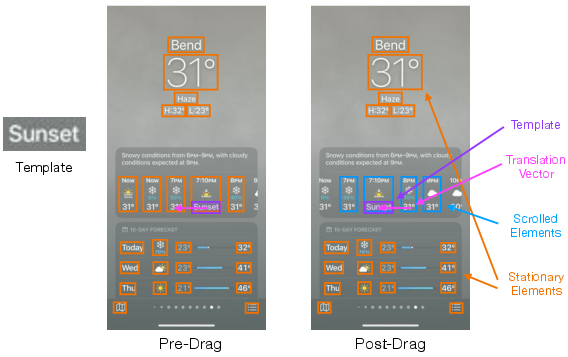
Figure 4: This figure illustrates the draggability heuristic. The heuristic uses a pre-drag image (center) which was taken before the interaction, and a post-drag image (right) which is taken near the end of the drag interaction, before the "finger" leaves the screen. A template image is created from the dragged element (left). The heuristic finds the location of the template in the post-drag image to infer draggability.
Screen Similarity
Enhancements to screen similarity models, fortified by interaction-driven dataset expansion, indicate mild yet consistent performance improvements. The augmentation contrasts existing annotated datasets, leveraging real app interactions to refine model efficiency.
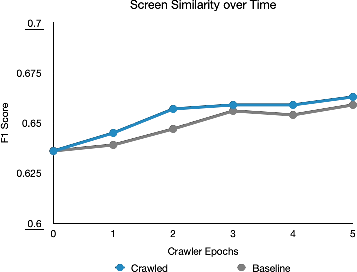
Figure 5: Performance of screen similarity over time. We compared i) adding training examples mined from crawls and ii) a baseline of continuing model training on its original dataset with a lower learning rate. The crawler-augmented dataset achieved a final F1 score of 0.663 while the baseline's final F1 score was 0.659.
In analysis, the paper delineates uncertain sampling and hybrid strategies but underscores randomized sampling's effectiveness, keen to further app-centric exploration dynamics. Running large-scale crawls demonstrates substantial model improvements, showcasing an exponential relationship between increased data volume and precision [SunUnreasonableEffectivenessofData].
Conclusion
The application of never-ending learning through UI exploration reveals new dimensions for real-time, automated dataset generation. By mitigating annotator biases, adapting rapidly to app design trends, and continually enriching UI semantic models, this research proposes an adaptive, scalable paradigm poised to enhance app accessibility frameworks vastly. Future inquiries could naturally extrapolate automated annotation strategies to newly identified UI features and interactive functionalities across diverse platforms.