- The paper demonstrates that scaling diffusion language models with task-specific and instruction finetuning enables competitive performance against autoregressive models.
- It presents detailed experiments showing superior results in machine translation benchmarks like IWSLT14 and WMT14 compared to smaller encoder-decoder models.
- Instruction finetuning endows the models with zero- and few-shot learning abilities, highlighting their potential to generalize across diverse language tasks.
The paper "Diffusion LLMs Can Perform Many Tasks with Scaling and Instruction-Finetuning" (arXiv ID: (2308.12219)) explores the potential of diffusion models to perform language tasks traditionally dominated by autoregressive models. By leveraging pre-trained masked LLMs and applying diffusive adaptation through task-specific and instruction finetuning, diffusion models are positioned as a potent alternative for language generation.
Introduction to Diffusion LLMs
Diffusion models have made significant strides in generative AI, particularly in image and audio synthesis, yet their application to language tasks remains underexplored. The paper initially delineates the advantages of diffusion models, such as a global receptive field and a non-autoregressive drafting-then-revising mechanism, both of which contrast favorably against autoregressive models constrained by one-sided contexts and unidirectional generation.
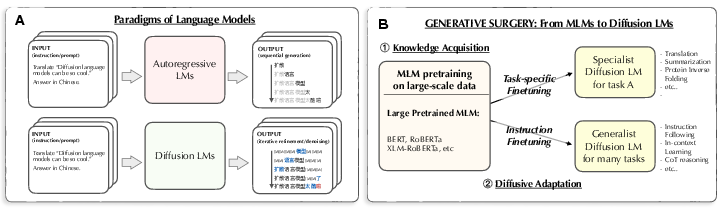
Figure 1: Overview of LLM paradigms highlighting autoregressive versus diffusion models.
Scaling Strategies for Diffusion LLMs
Data and Model Size Scaling
The diffusion LLMs are scaled concerning data volume and model size to enhance their language generation capabilities. The authors demonstrate that leveraging masked language modeling (MLM) for pretraining allows diffusion models to capture vast amounts of knowledge from large datasets. This scaling enables the models to compete effectively with autoregressive models in tasks like machine translation (MT) and text summarization.
Task-Specific Finetuning
The paper describes experiments with diffusion models, particularly task-specific finetuning for MT tasks such as IWSLT14 De→En and WMT14 En→De. Here, the diffusion model outperformed standard encoder-decoder models of similar or smaller sizes, showcasing its adaptability and efficiency in leveraging pretrained data.

Figure 2: Generation process in machine translation illustrating separate segment generation.
Instruction-Finetuning
Instruction finetuning further broadens the capabilities of diffusion models by training them across a multitude of tasks defined by natural language instructions. This allows the models to assimilate capabilities such as zero-shot and few-shot learning, akin to their autoregressive counterparts.
Figure 3: Zero-shot performance evaluation indicating scalable learning across model sizes.
Diffusion models demonstrate competitive performance across several tasks by scaling up model sizes, outperforming smaller models notably across benchmarks like IWSLT14, WMT14, and Gigaword-10K, validating the scalability hypothesis. Moreover, the transition from masked LLMs to diffusion models via reparameterization provides a simplified training path while retaining effectiveness.
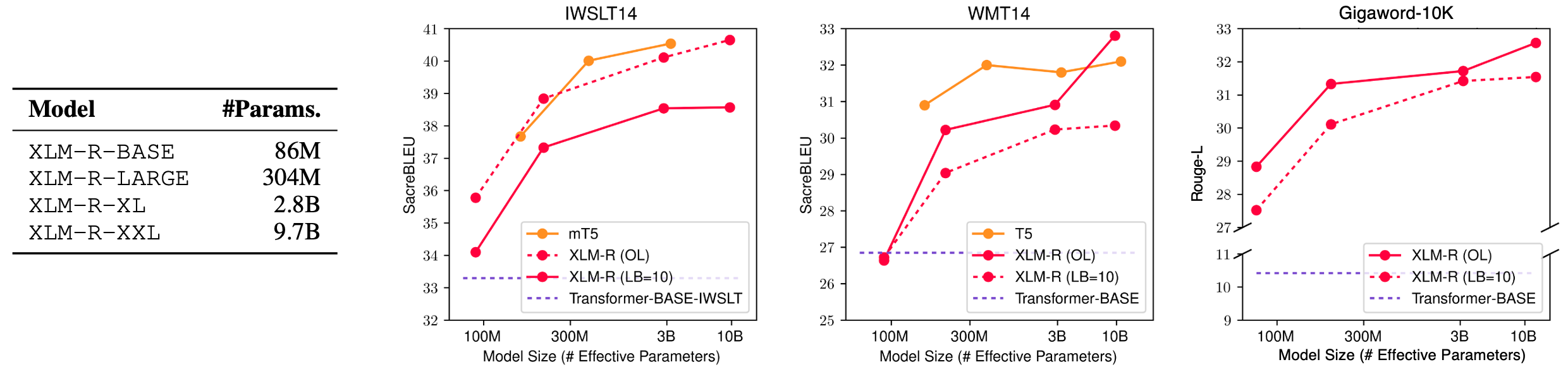
Figure 4: Scaling curves for task-specific finetuning highlighting advancements across datasets.
Reasoning Abilities and Future Implications
While diffusion models exhibit adaptability to various tasks, they encounter challenges in tasks requiring complex reasoning. The paper posits that further exploration in model sizes, pretraining opportunities, and architectural improvements can ameliorate these limitations.

Figure 5: Causal graph depicting the reasoning processes evaluated with diffusion models.
Conclusion
The work pioneers diffusion LLMs as a viable alternative to autoregressive models, focusing on scaling strategies and instruction finetuning as key elements. Although faced with limitations in reasoning task performance, diffusion models provide promising directions for enhanced computational capabilities via flexible and efficient language generation paradigms. Further research will continue to unveil the potential of diffusion models in broader language processing tasks, aligning generative paradigms across varying domains.