- The paper introduces LLaDA, a masked diffusion approach that challenges conventional autoregressive models by enabling bidirectional token prediction.
- It employs a forward diffusion masking process with a reverse mechanism optimized via cross-entropy loss, achieving competitive results against ARMs.
- The study demonstrates scalability with models up to 8B parameters and effective handling of the reversal curse while improving in-context and instruction-following capabilities.
Large Language Diffusion Models
This paper introduces LLaDA, a novel approach to large language modeling that challenges the dominance of autoregressive models (ARMs). By leveraging masked diffusion models (MDMs), LLaDA demonstrates strong scalability, in-context learning, and instruction-following capabilities, achieving performance competitive with state-of-the-art LLMs while addressing inherent limitations of ARMs.
Generative Modeling with Masked Diffusion
LLaDA models the language distribution using a forward diffusion process that gradually masks tokens in a sequence and a reverse process that predicts the masked tokens. Unlike ARMs, which predict the next token sequentially, LLaDA leverages a mask predictor to simultaneously predict all masked tokens based on the context of the partially masked sequence (Figure 1). This bidirectional approach allows LLaDA to capture more complex dependencies and address limitations such as the reversal curse.
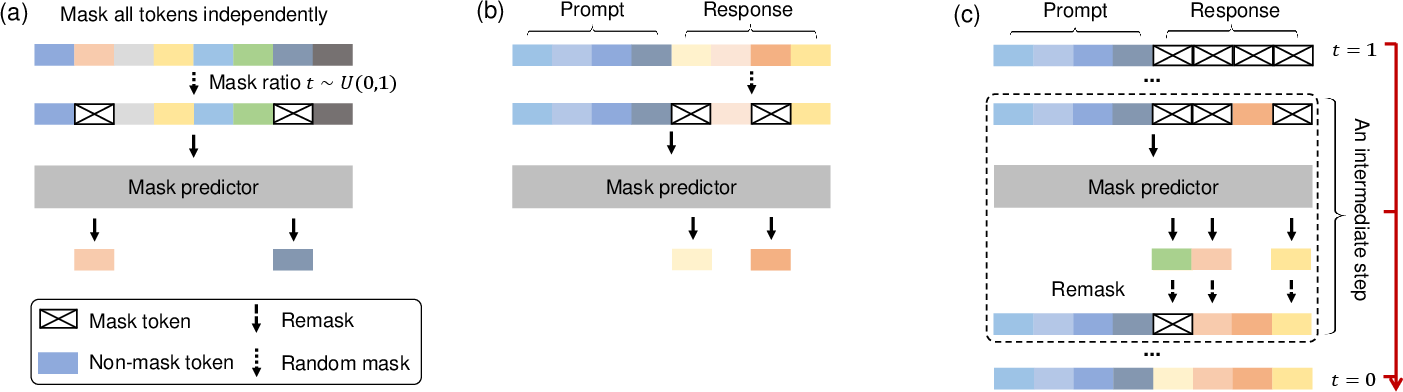
Figure 1: A conceptual overview of LLaDA illustrates its pre-training, SFT, and sampling procedures.
The mask predictor, implemented as a Transformer network, is trained by optimizing a likelihood bound using a cross-entropy loss computed only on the masked tokens. This training objective ensures that LLaDA learns a principled generative model capable of both sampling new text and evaluating the likelihood of existing text.
The paper demonstrates the scalability of LLaDA by training models of varying sizes (1B and 8B parameters) and evaluating their performance on a diverse set of language tasks. The results show that LLaDA exhibits strong scalability, achieving comparable results to self-constructed ARM baselines trained on the same data and computational budget (Figure 2). Notably, LLaDA outperforms LLaMA2 7B on nearly all 15 standard zero/few-shot learning tasks while performing on par with LLaMA3 8B.
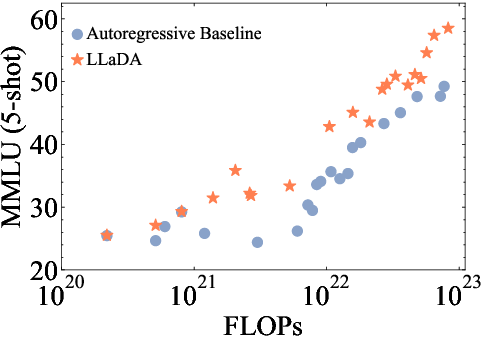
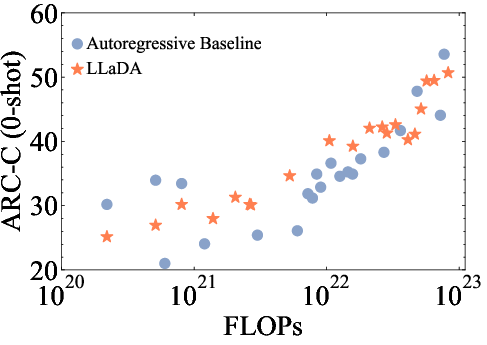
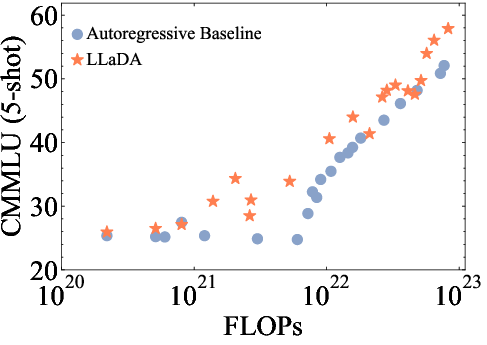
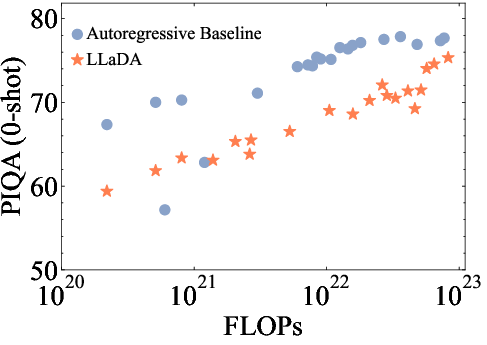
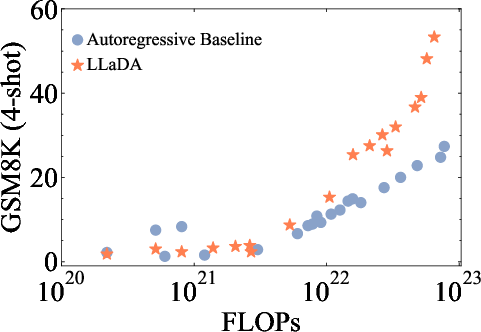
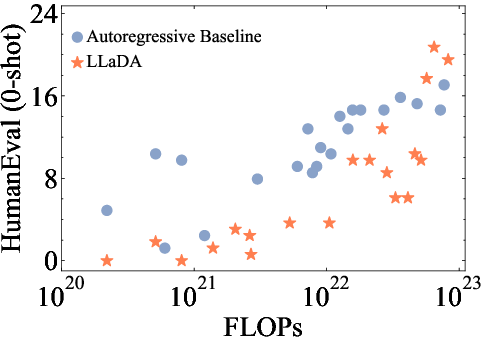
Figure 2: The scalability of LLaDA is shown by evaluating its performance and ARM baselines trained on the same data across increasing computational FLOPs.
Furthermore, the paper evaluates LLaDA's instruction-following capabilities by supervised fine-tuning (SFT) on a dataset of 4.5 million pairs. The results demonstrate that SFT significantly enhances LLaDA's ability to follow instructions, as evidenced by case studies such as multi-turn dialogue. Although LLaDA's performance is slightly behind LLaMA3 8B Instruct, the gaps in many metrics remain small, highlighting the potential of diffusion models for instruction-following tasks.
Addressing the Reversal Curse
One of the key contributions of this paper is the demonstration that LLaDA effectively addresses the reversal curse, a known limitation of ARMs. The reversal curse refers to the inability of LLMs trained on "A is B" to correctly infer "B is A". LLaDA's bidirectional modeling approach allows it to maintain consistent performance across forward and reversal tasks, outperforming GPT-4o in a reversal poem completion task. This finding suggests that diffusion models may offer a more robust and generalizable approach to language modeling than ARMs.
Semi-Autoregressive Sampling
To improve the coherence and fluency of generated text, the paper explores a semi-autoregressive remasking strategy (Figure 3). This strategy involves dividing the sequence into blocks and generating them from left to right, applying the reverse process within each block. This approach combines the benefits of bidirectional modeling with the sequential generation of ARMs, resulting in improved performance on downstream tasks.
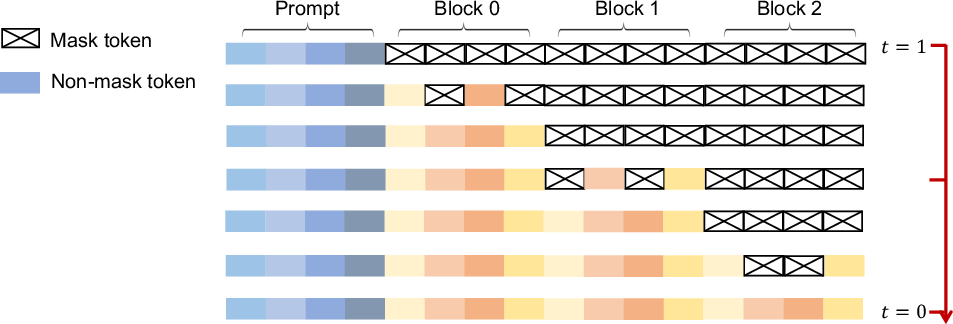
Figure 3: A conceptual overview of the semi-autoregressive sampling highlights generating sequences from left to right in blocks and applying a reverse process within each block.
Conclusion
LLaDA presents a promising alternative to ARMs for large language modeling, demonstrating strong scalability, in-context learning, and instruction-following capabilities. By leveraging masked diffusion models and a novel semi-autoregressive sampling strategy, LLaDA addresses inherent limitations of ARMs, such as the reversal curse, and achieves performance competitive with state-of-the-art LLMs. The findings challenge the prevailing assumption that essential LLM capabilities are inherently tied to ARMs, opening new avenues for exploring alternative probabilistic paradigms in NLP. Future research directions include further scaling of LLaDA, exploring multi-modal data handling, and investigating prompt tuning techniques and integration into agent-based systems.
