- The paper presents a comprehensive survey of discrete diffusion models as efficient alternatives to autoregressive models, demonstrating up to 10x faster inference.
- The study elaborates on key mathematical formulations, including D3PM and RDM, that underpin scalable and fine-tuned denoising-based generation.
- The work details innovative training and inference techniques such as unmasking and caching, enabling improved efficiency and dynamic generation control.
Discrete Diffusion in Large Language and Multimodal Models: A Survey
Overview and Motivation
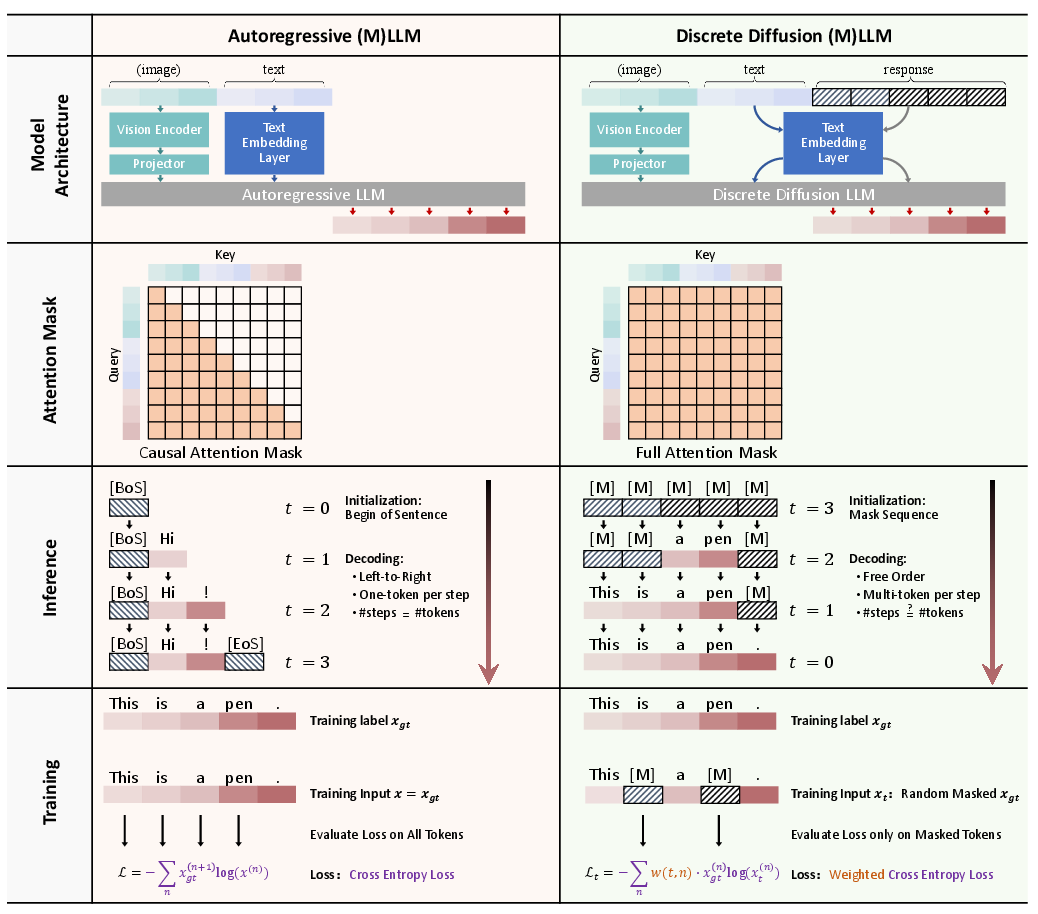
This paper presents a comprehensive survey of Discrete Diffusion LLMs (dLLMs) and Discrete Diffusion Multimodal LLMs (dMLLMs), exploring their potential as alternatives to traditional autoregressive (AR) models for LLMs and Multimodal LLMs (MLLMs). The key distinction lies in their generation paradigm, which adopts a multi-token, parallel decoding strategy enabled by a denoising-based generation mechanism. This approach allows for significant improvements in parallelization, fine-grained controllability, and dynamic perception — yielding up to 10 times faster inference compared to AR models.
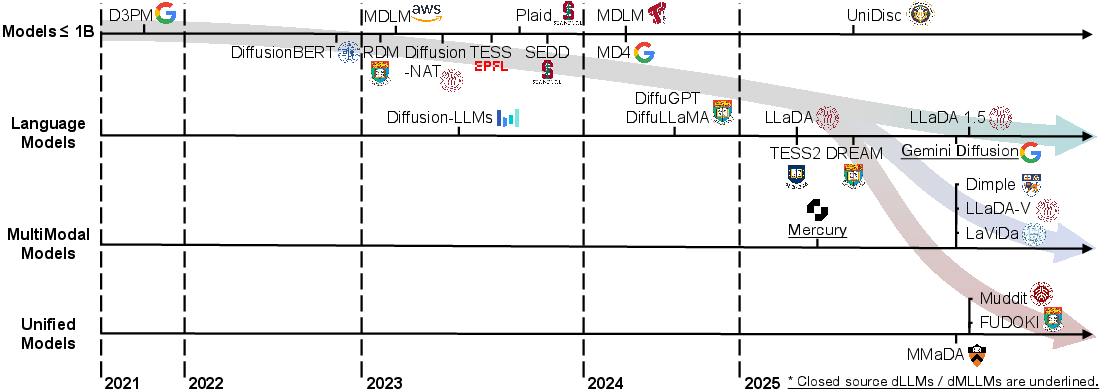
Figure 1: A timeline of existing dLLMs and dMLLMs in recent years. The timeline is established mainly according to the release date of the technical paper for a model.
Mathematical Foundations
Discrete diffusion models have transitioned from continuous-space diffusion frameworks to discrete-space models utilizing absorbing states, facilitating scalable engineering optimizations. The model's core process involves a forward Markov process for token corruption, and a learned reverse process for iterative denoising of sequences. Several key mathematical formulations underpin these models:
Representative Models and Training Techniques
Recent advancements have led to a surge in dLLM and dMLLM models, scaling from smaller versions to industrial-scale models like Mercury from Inception Labs and Gemini Diffusion by Google, which compete with AR models while offering significant speed advantages.
- LLaDA, DiffuGPT, and DiffuLLaMA: These models utilize a hybrid initialization strategy based on pretrained AR models, progressively fine-tuned with diffusion objectives.
- DREAM and TESS 2: Introduce innovative training recipes and unsupervised guidance techniques to harness the benefits of diffusion in real-world tasks.
- Multimodal Models (Dimple, LaViDa, LLaDA-V): These models extend dLLMs to multimodal contexts, integrating vision and language inputs using hybrid autoregressive-diffusion training frameworks for improved efficiency and reasoning capabilities.
Training innovations include autoregressive initialization, entropy-aware and complementary masking schedules, and hybrid diffusion autoregressive training to address the inefficiencies of traditional diffusion training.
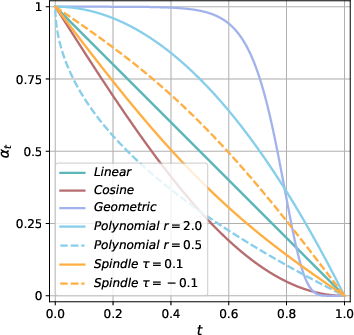
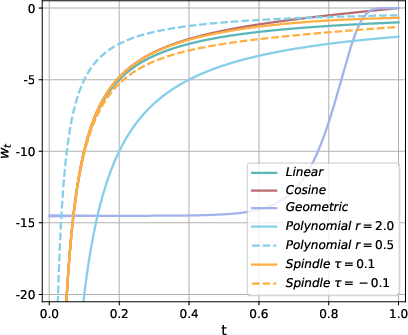
Figure 3: Different schedules for alpha_t and w_t.
Inference Techniques and Applications
Inference optimization plays a crucial role in deploying dLLMs and dMLLMs effectively:
- Unmasking Strategies: Including random, metric-based unmasking, and confident decoding adaptively select token positions for parallel and dynamic generation.
- Prefilling and Caching: These methods accelerate the inference phase by preserving key-value pairs across steps, showing substantial speed-ups with minimal performance trade-offs.
- Guidance Techniques: Classifier-free and reward-based guidance allow fine-tuning of generation processes according to specific task requirements.
Applications of discrete diffusion models span text generation, editing, sentiment analysis, and beyond, demonstrating strong performance in vision-language tasks and biological sequence design.
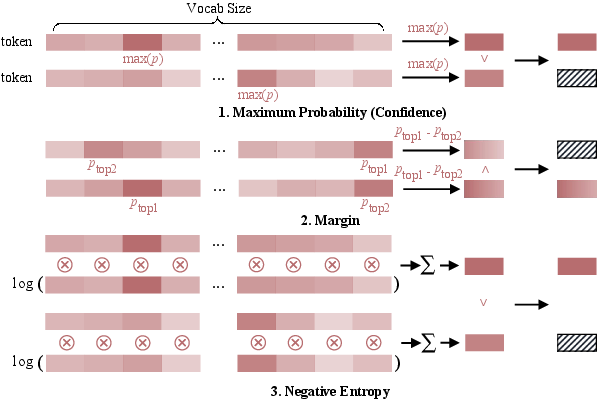
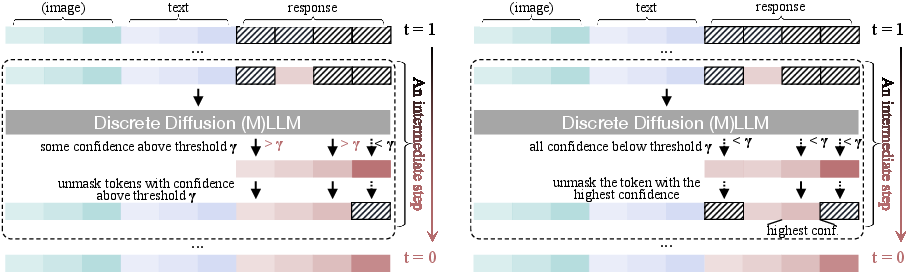
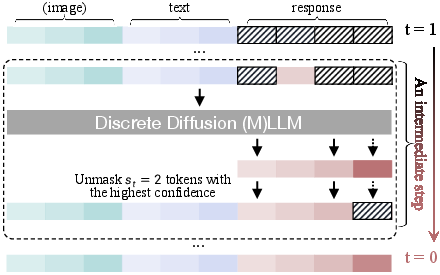
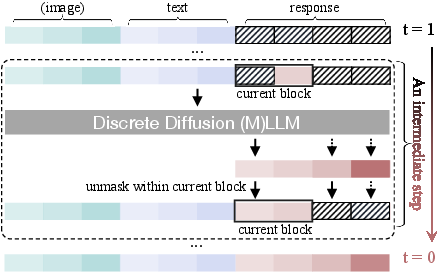
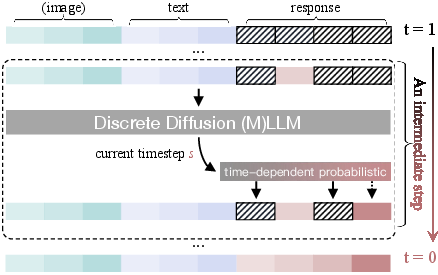
Figure 4: Unmasking strategies, demonstrating discrete and continuous-time unmasking across different models.
Future Directions
Research has outlined key challenges and future endeavors to enhance dLLMs and dMLLMs:
- Infrastructure and Scalability: Building standardized and scalable development frameworks and pretrained models are crucial for widespread adoption.
- Inference and Efficiency: Innovations in efficient sampling and representation compression are needed to improve deployment and practicality at scale.
- Security and Privacy: Addressing privacy risks and ensuring secure model deployment are paramount as dLLMs gain traction across various domains.
Exploring these pathways will further solidify the role of discrete diffusion models in the landscape of AI, particularly as a parallel approach to autoregressive models for versatile, controllable, and efficient solutions in diverse applications.
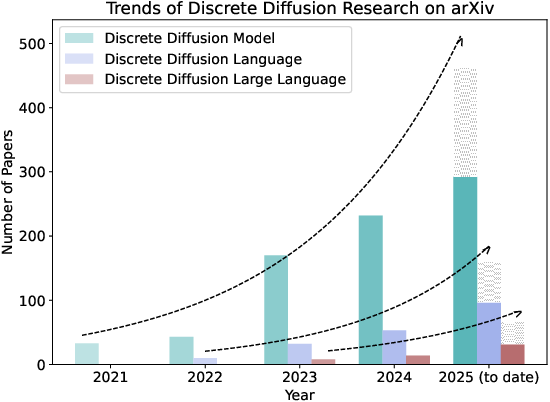
Figure 5: Consistent year-over-year growth in research, highlighting increasing interest in discrete diffusion models.
Conclusion
The survey highlights the potential of discrete diffusion models as efficient and capable alternatives to AR models. By consolidating mathematical frameworks, model architectures, and inference strategies, it offers insights into the ongoing research and application developments in this evolving field. Further exploration in scalability, efficiency, and security will be vital in realizing the full potential of dLLMs and dMLLMs.