- The paper demonstrates that ChatGPT fails to win games against high-level chess engines due to increased illegal moves and reasoning flaws.
- It employs baseline experiments with 1000 games to measure Illegal Move Ratio (IMR) and Retries Before Legal Move (RBLM), highlighting systematic performance issues.
- Analysis shows that varied prompting methods yield inconsistent improvements, emphasizing the need for better integration of formal language processing in strategic tasks.
LLMs on the Chessboard
Introduction
The paper "LLMs on the Chessboard: A Study on ChatGPT's Formal Language Comprehension and Complex Reasoning Skills" (2308.15118) investigates the application of ChatGPT—a sophisticated LLM by OpenAI— in the context of playing chess, a domain requiring formal language comprehension and complex reasoning. The study assesses ChatGPT's proficiency in understanding the chessboard, adhering to chess rules, and making strategic decisions. It identifies limitations in ChatGPT's attention mechanism and its self-regulation capabilities, thus contributing to the exploration of LLMs' abilities in tasks beyond natural language processing.
Baseline Experiment
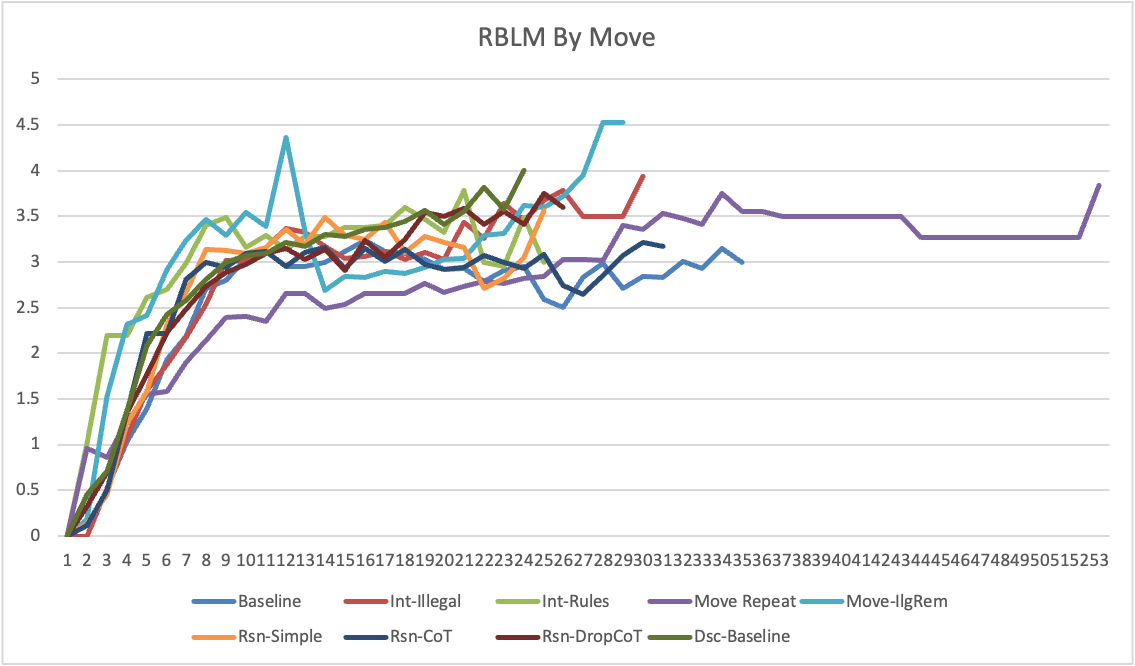
The study employs a baseline experiment where ChatGPT, without fine-tuning, plays chess against Stockfish 15.1, a state-of-the-art computer chess engine. The experiment involves ChatGPT playing as the black player with prompts in Standard Algebraic Notation (SAN), conducting a total of 1000 games to establish baseline performance metrics such as Illegal Move Ratio (IMR) and Retries Before Legal Move (RBLM).
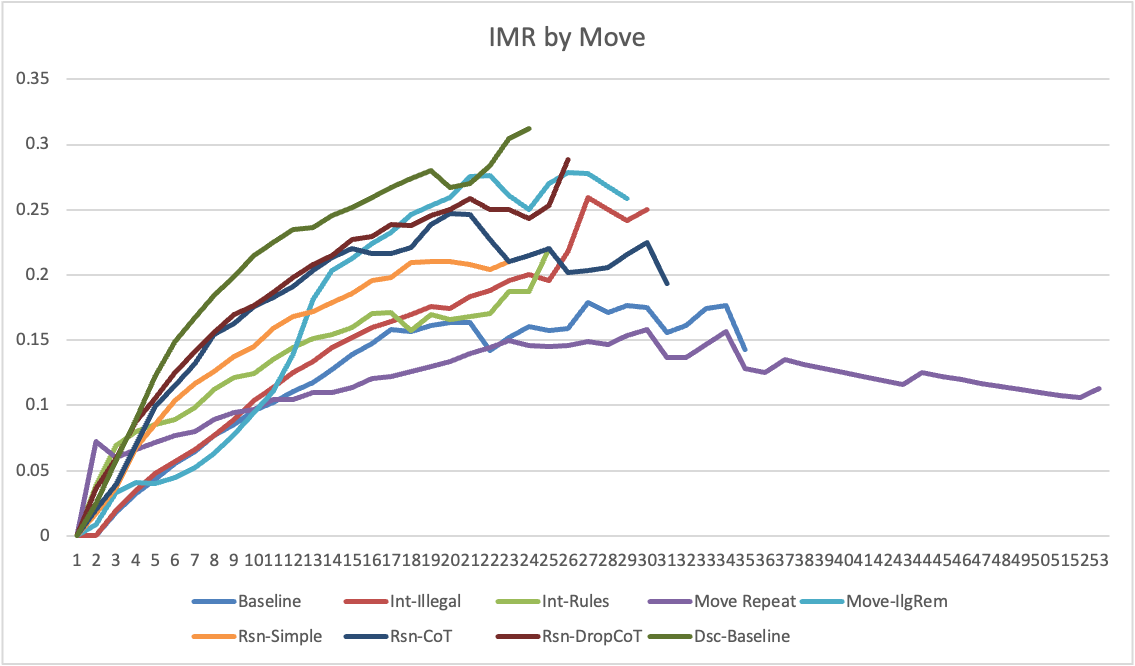
Figure 1: Average IMR by Move.
Prompt Variations
To address ChatGPT's performance deficiencies, the paper explores the effect of different prompting strategies:
Natural Language Reasoning
The study examines allowing ChatGPT to reason in natural language prior to making moves, employing different techniques like Chain of Thought prompting (Rsn-CoT). This approach led to decreased RBLM but also contributed to poor move quality due to erroneous information in reasoning dialogues.
Chessboard Description
A further experiment investigates whether substituting formal language with natural language descriptions of the chessboard state affects performance. Despite reducing RBLM, this approach substantially increased IMR and demonstrated poor move quality, suggesting that ChatGPT struggles to apply learned cognitive functions when lacking formal structure.
Strategic Behavior Analysis
The paper analyzes whether ChatGPT exhibits consistent strategic behavior. It introduces the Move Repetition Score (MRS) to measure illegal move diversity, suggesting that the presence of more natural language in interactions correlates with greater consistency and intent in move generation.
Findings and Discussion
ChatGPT demonstrated substantial limitations in playing chess, failing to win any games across 3200 experiments. The increase in IMR and RBLM with game length highlights challenges in retaining and applying chess rules dynamically. These findings raise concerns about the application of LLMs in high-stakes domains requiring formal logic comprehension.
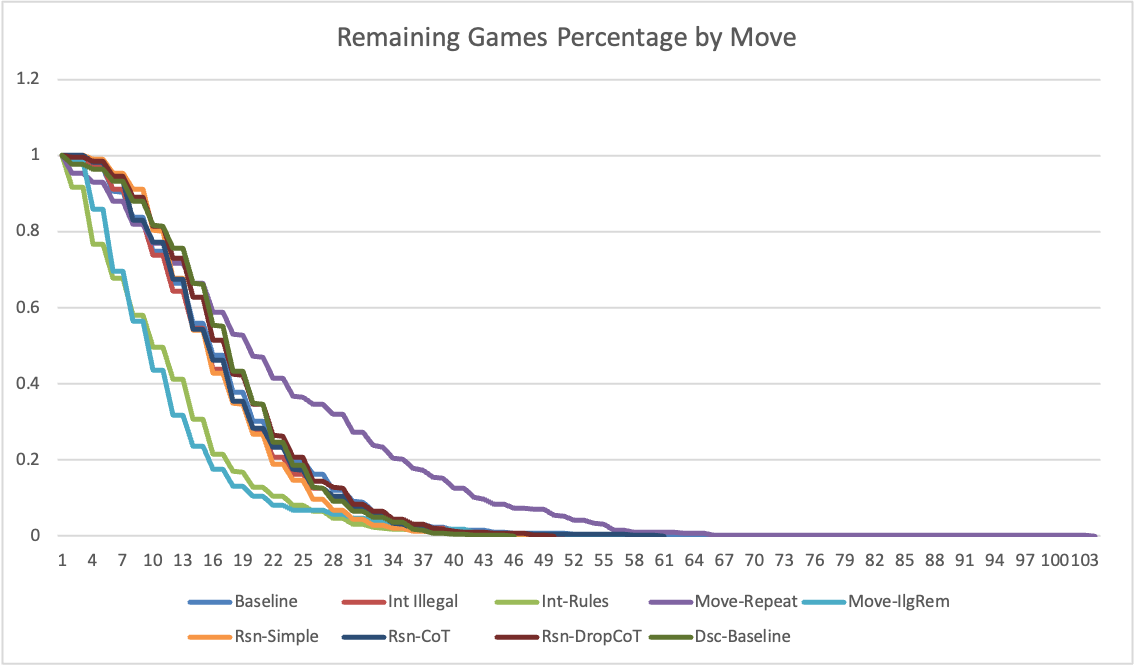
Figure 3: Remaining Games by Move.
Limitations in Self-Attention
ChatGPT's attention mechanism, disproportionately focusing on recent tokens, hampers its ability to track full conversational contexts essential for game state comprehension. This issue, along with the model's tendency to neglect formal language, complicates its proficiency in tasks demanding long-term strategic planning.
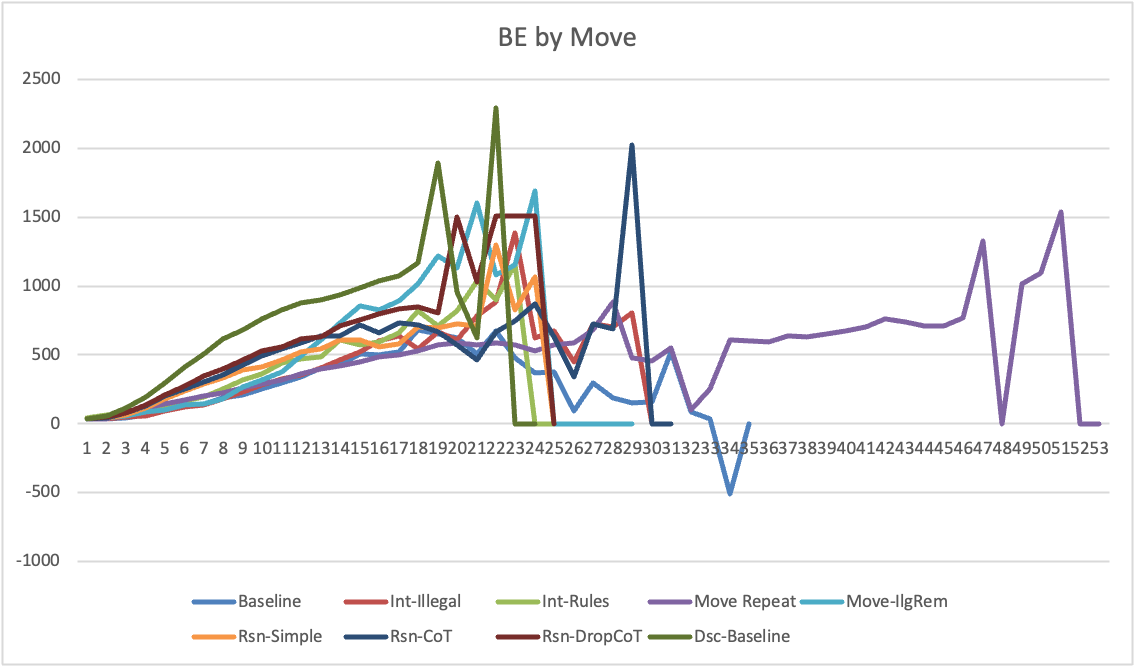
Figure 4: Board Evaluation by Move.
Intent Behind Decisions
The correlation between lower RBLM and increased "intent" in decision-making indicates that enhancements in board representation and interaction formats lead to more deliberate move selections, though not necessarily improved quality. Future research should continue exploring strategic consistency across extended sequences of interactions.
Conclusion
The investigation highlights substantial limitations in ChatGPT's ability to perform complex reasoning tasks with formal language, as evidenced by its chess-playing capabilities. Despite known rules, ChatGPT's attention challenges and lack of self-regulation point to significant hurdles in achieving human-like cognitive abilities in non-linguistic contexts. These findings underscore the need for further refinement before considering ChatGPT as a reliable tool for formal language-dependent applications. Future research should focus on improving attention distribution and reducing formal language neglect to enhance performance in complex reasoning tasks.