- The paper introduces DAIL-SQL, an integrated approach using prompt engineering to boost Text-to-SQL conversion accuracy and efficiency.
- It evaluates diverse question representation strategies, with code and demonstration prompts showing superior performance.
- Supervised fine-tuning of open-source LLMs significantly improves their SQL generation, making them competitive with proprietary models.
Text-to-SQL Empowered by LLMs: A Benchmark Evaluation
The paper "Text-to-SQL Empowered by LLMs: A Benchmark Evaluation" (2308.15363) investigates the application of LLMs in the Text-to-SQL task, providing a comprehensive benchmark evaluation of various prompt engineering strategies. Text-to-SQL involves converting natural language questions into SQL queries that can be executed on relational databases. The paper proposes a novel integrated solution named DAIL-SQL, highlights the potential of open-source LLMs, and evaluates them in terms of efficiency, performance, and economic viability.
Overview of Text-to-SQL and LLMs
The Text-to-SQL task is characterized by its ability to bridge the gap between non-expert users and databases by automatically generating SQL queries from natural language questions. Traditional approaches have relied on encoder-decoder models trained on Text-to-SQL corpora. However, recent advancements in LLMs present new opportunities. LLMs, such as GPT-4 and LLaMA, trained on extensive text corpora, can leverage their in-context learning ability through prompt engineering, which includes question representation, example selection, and organization.
Question Representation Strategies
The study evaluates several question representation techniques, comparing their efficiency and accuracy:
- Basic Prompt (BS): A straightforward representation featuring table schemas, questions prefixed with "Q:", and response guidance with "A: SELECT".
- Text Representation Prompt (TR): Represents both schema and question in natural language format, adding task instructions.
- OpenAI Demonstration Prompt (OD): Utilizes pound sign comments for structuring database schema and requires LLMs to generate SQL queries without explanation.
- Code Representation Prompt (CR): Presents database schema as SQL "CREATE TABLE" statements, prompting LLMs in SQL syntax.
- Alpaca SFT Prompt (AS): Designed for fine-tuning, using Markdown format with detailed task instructions.
Among the methods, CR and OD demonstrated superior performance due to their detailed and structured representation.
In-Context Learning
In-context learning is essential for enhancing LLM performance in the Text-to-SQL task. Two sub-tasks are considered: example selection and organization:
Example Selection
- Random: Randomly samples examples as a baseline.
- Question Similarity Selection (QTS): Chooses examples with similar questions using distance measures.
- Masked Question Similarity Selection (MQS): Masks specific domain-related tokens in questions and uses similarity measures.
- Query Similarity Selection (QRS): Selects examples based on similarity to a preliminary query generated by a model.
- DAIL Selection: Prioritizes both question and query similarity, achieving superior selection results.
Example Organization
- Full-Information Organization (FI): Represents examples with complete question and schema details.
- SQL-Only Organization (SO): Contains only SQL queries from examples to maximize token usage.
- DAIL Organization: Balances quality and quantity by displaying both questions and SQL queries without schemas.
DAIL approaches take advantage of LLM capabilities, providing better execution accuracy through a careful balance of example selection and organization.
Supervised Fine-Tuning
The potential of open-source LLMs is also explored through supervised fine-tuning. This method enhances the ability of LLMs in zero-shot Text-to-SQL tasks. Experiments showed that supervised fine-tuning significantly improved performance over zero-shot learning alone, making tuned open-source models comparable to proprietary models like TEXT-DAVINCI-003.
Token Efficiency
The study assessed token efficiency, critical for evaluating the practical deployment of LLMs given the financial cost associated with API calls. DAIL-SQL was found to be both effective and economical, surpassing many contemporary solutions in accuracy with fewer tokens required.
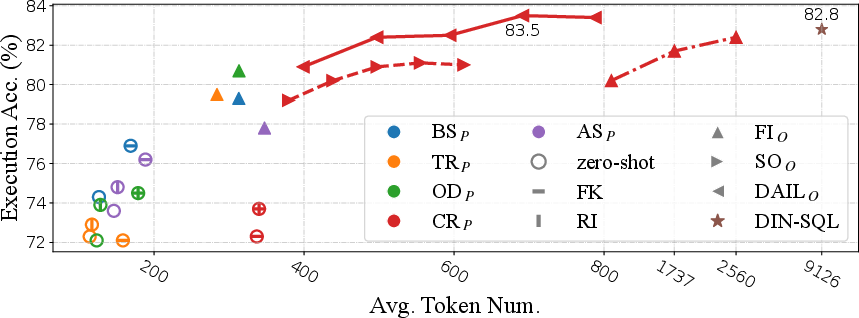
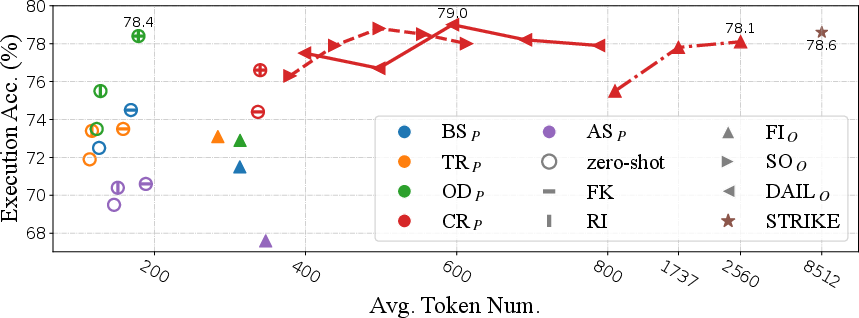
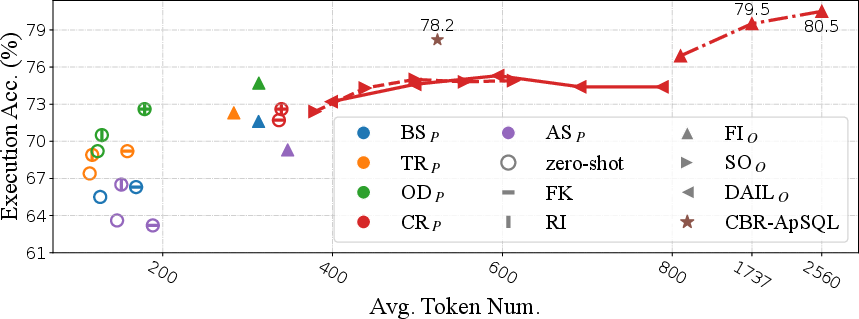
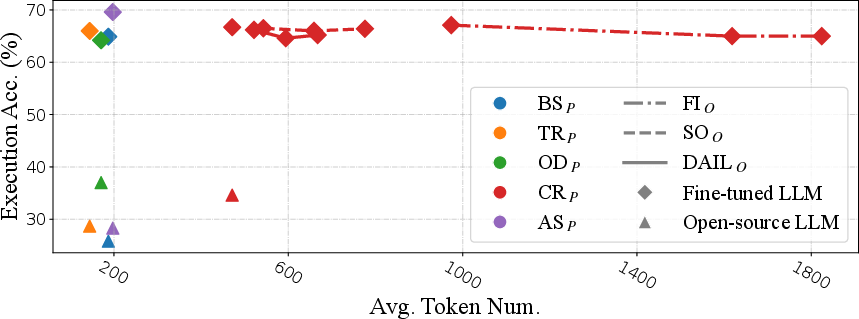
Figure 1: Token efficiency of different representations in Spider-dev for OpenAI LLMs. We utilize different colors to represent different question representations and different shapes to denote different example organizations as well as the usage of foreign key information and rule implication.
Conclusion
The research provides valuable insights into optimizing LLMs for Text-to-SQL tasks, emphasizing the efficiency and effectiveness of prompt engineering strategies. It demonstrates the importance of both representation and organizational strategies to leverage LLM capabilities. The potential for improvement through fine-tuning is considerable, suggesting future research directions in blending these methods to maximize performance. The DAIL-SQL approach sets a new benchmark on the Spider leaderboard, offering a practical solution for real-world applications.