- The paper introduces a unified generative pipeline that tokenizes user/item IDs and employs autoregressive LLM decoding for recommendations.
- It categorizes methods for ID representation, including SVD-based tokenization, collaborative indexing, and residual-quantized VAE, to enhance recommendation efficiency.
- The study highlights challenges such as hallucination, bias, and evaluation limitations while proposing visionary directions for multimodal and real-time systems.
LLMs for Generative Recommendation: A Survey and Visionary Discussions
Introduction and Motivation
The surveyed work "LLMs for Generative Recommendation: A Survey and Visionary Discussions" (2309.01157) provides a comprehensive synthesis of state-of-the-art methodologies, challenges, and future directions for LLM-based generative recommendation systems. The core thesis is that the generative capability of LLMs introduces a new paradigm that re-conceptualizes the traditional multi-stage recommender pipeline as a unified, generative process, wherein user and item representations (IDs) are tokenized and recommendations are directly generated via the LLM’s autoregressive decoding.
A key insight is the generalization of item and user IDs from atomic discrete tokens to flexible token sequences, which allows for seamless integration with LLMs’ text-based reasoning and NLG capacities. This reformation addresses the computational bottlenecks and practical inflexibilities of classical discriminative recommenders.
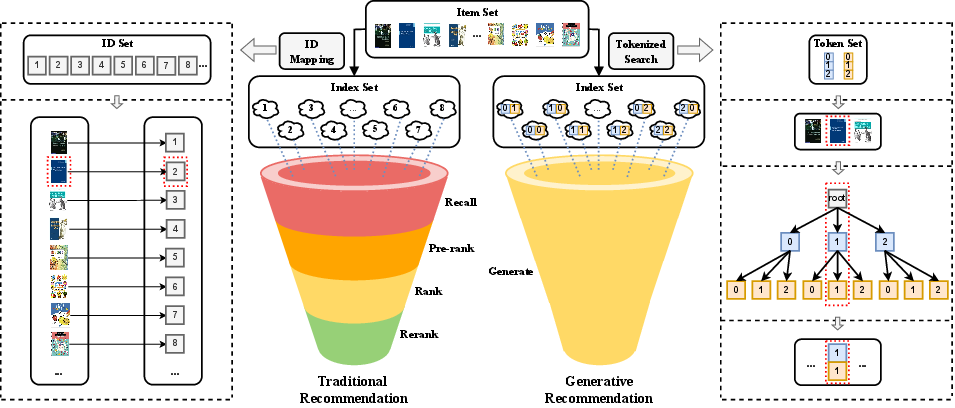
Figure 1: Pipeline comparison between traditional recommender systems and LLM-based generative recommendation.
Generative Recommendation: Definitions and Advantages
The authors formalize generative recommendation as the direct generation of recommendations or ancillary content (explanations, reviews) by an LLM, rather than via explicit ranking or scoring of all items. This stands in contrast with the classical filter-then-rank paradigm, which is computationally constrained and segregates recommendation steps into candidate generation, scoring, and re-ranking.
Key benefits articulated for the generative paradigm include:
- Scalability of Decoding: With a finite vocabulary of tokens (e.g., 1000 tokens, 10-token sequences yielding 1030 unique IDs), LLMs can represent and decode item/user spaces at industrial scales with manageable computation.
- Unified Pipeline: The LLM can serve as the end-to-end backbone, tightly coupling input signals (user/item features, histories) to outputs (item IDs, explanations) in a single step.
- Generalization to New Representations: The flexibility to define IDs as natural language, metadata, embeddings, or hybrid sequences unlocks expressive and context-rich modeling, leveraging LLMs’ pretraining.
ID Representation and Construction
The survey identifies that naïvely using metadata or embedding-based IDs introduces inefficiencies and ambiguity (e.g., long descriptive sequences are ill-suited for LLM decoding, and natural language ID overlap yields referential uncertainty).
Three approaches for ID creation that retain collaborative signal and LLM-compatibility are detailed:
- SVD-based Tokenization: Truncated SVD of the interaction matrix yields quantized, noise-augmented token arrays as unique, information-rich item IDs.
- Collaborative Indexing: Hierarchical clustering (via spectral clustering of the item co-occurrence graph) produces tree-based token indices, generating unique and similarity-preserving token paths for each item.
- Residual-Quantized VAE: RQ-VAE encodes item embeddings into discrete codewords required for compact, unique token sequence IDs.
This taxonomy focuses on embeddings/tokenizations that encode both uniqueness and collaborative semantics, supporting efficient and precise generative decoding without the OOV/OOM drawbacks of lazy embedding approaches.
The paper systematically categorizes recommendation tasks under the generative paradigm, defining prompt-engineered LLM applications for:
- Rating Prediction: Generation of expected ratings via task-specific prompts containing token-sequence IDs.
- Top-N Recommendation and Sequential Recommendation: Direct generation or selection of item IDs using prompts, optionally with candidate sets for controlled selection. Generation is implemented auto-regressively with approaches such as beam search, supporting efficient enumeration or subselection.
- Explainable/Review Generation: Natural language generation capability is leveraged for explanatory text, with prompt templates specifying aspects/features (e.g., “Explain to user u why item i is recommended, focusing on 'acting'”).
- Conversational Recommendation: Dialogue and session-based prompts using structured roles enable multi-turn, multi-modal recommendation with context retention and grounding.
For each task, the survey details both protocol and foundational work, including efforts to standardize prompt design, address lack of ground-truth for open-ended generation, and analyze the limitations of LLMs in strictly discriminative tasks.
Evaluation Protocols and Limitations
Evaluation for generative recommenders remains open. Numeric prediction tasks can leverage RMSE, MAE, and ranking metrics (NDCG, Precision, Recall). Generated text is assessed with BLEU/ROUGE but these can fail to capture the open-ended, preference-centric diversity of natural language explanations and reviews. Human evaluation and emerging metrics (e.g., BERTScore, feature coverage/diversity) remain areas of active development, with the recognition that current protocols may overly penalize valid, creative outputs not present in annotated targets.
Challenges and Future Directions
The survey isolates several critical challenges:
- Hallucination: LLMs may generate non-existent or invalid item IDs/content, especially in high-stakes or high-precision recommendation contexts. Trie-based decoding (enforcing valid item paths) and retrieval-augmentation (conditioning on concrete item sets) are highlighted as potential mitigations.
- Bias and Fairness: Both content and recommendation bias propagate from pretraining data. The survey details instances of gender, provider, and demographic bias and emphasizes the need for principled fairness definitions and effective mitigation strategies, especially given the fine line between personalization and unfairness.
- Explainability and Transparency: While LLMs can surface fluent explanations, the opaqueness of internal decision processes precludes robust transparency. Alignment with external KGs and explicit path grounding are suggested directions for explainable model pipelines.
- Controllability and Efficiency: LLM generation can be erratic or difficult to constraint to user-specified facets (e.g., price, brand) or ethical standards. Prompt engineering and fine-tuning offer partial solutions, but fail to guarantee hard constraints. Efficient inference—critical in low-latency production settings—remains an unsolved bottleneck.
- Multimodality and Creation: Extension to images, video, or music recommendation and generation (via foundation multimodal models) is both feasible and largely unexplored, with opportunities for creative item synthesis, retrieval, and user engagement.
- Cold-Start and Generalization: LLMs’ world knowledge from pretraining enables meaningful cold-start recommendations, with the potential to offset the limitations of collaborative filtering in sparse data settings.
Implications and Future Prospects
The theoretical implications are substantial: generative recommenders collapse the modular score/rank/pipeline structure, potentially unifying item selection, explanation, review generation, and even item/design creation in a single architecture. Practically, this could yield adaptable, domain-agnostic, and context-aware recommenders agnostic to classical neural embedding limitations.
Further, the survey posits a vision where LLM-based RS are embedded as autonomous agents, integrating tool invocation, real-time retrieval, and user-grounded dialogue in complex physical or digital environments (e.g., in-vehicle systems, trip planners).
Conclusion
The paper provides a structured, authoritative analysis of the shift towards LLM-based generative recommendation, including technical taxonomies, methodological detail, open challenges, and visionary future outlooks. It serves as both a reference and roadmap for researchers focused on foundation models, prompt-based recommendation, and the integration of generative AI into practical personalization systems. The pathway forward suggests deepening theoretical understanding of generative architectures, robustification of evaluation protocols, and scalable solutions for the open issues of efficiency, bias, hallucination, and multimodality in recommendation science.