- The paper introduces LATS, a groundbreaking framework that combines MCTS with LLMs to unify reasoning, acting, and planning.
- LATS demonstrates superior performance, achieving a 94.4% pass@1 on programming tasks and a 75.9 score on HotPotQA.
- LATS effectively integrates real-world interactive environments, outperforming methods like ReAct, CoT, and RAP in decision-making tasks.
Language Agent Tree Search: A Unified Approach in LLMs
The paper "Language Agent Tree Search Unifies Reasoning Acting and Planning in LLMs" (2310.04406) presents an innovative approach to synergize the reasoning, acting, and planning capabilities of LLMs within a unified framework termed Language Agent Tree Search (LATS). The conceptual and methodological contributions of this paper extend previous work on LLMs by integrating planning tools like Monte Carlo tree search, effectively transforming LLMs into versatile autonomous agents suitable for a range of complex decision-making tasks.
Framework and Methodology
LATS is founded on the principles of Monte Carlo Tree Search (MCTS), which has been traditionally used in model-based reinforcement learning. The core framework adapts MCTS for LLMs, leveraging LLMs as agents, value functions, and optimizers. The novelty of LATS lies in its capacity to harness the powerful inherent reasoning capabilities of LLMs to construct action trajectories that are continuously evaluated and enriched by external feedback from interactive environments.
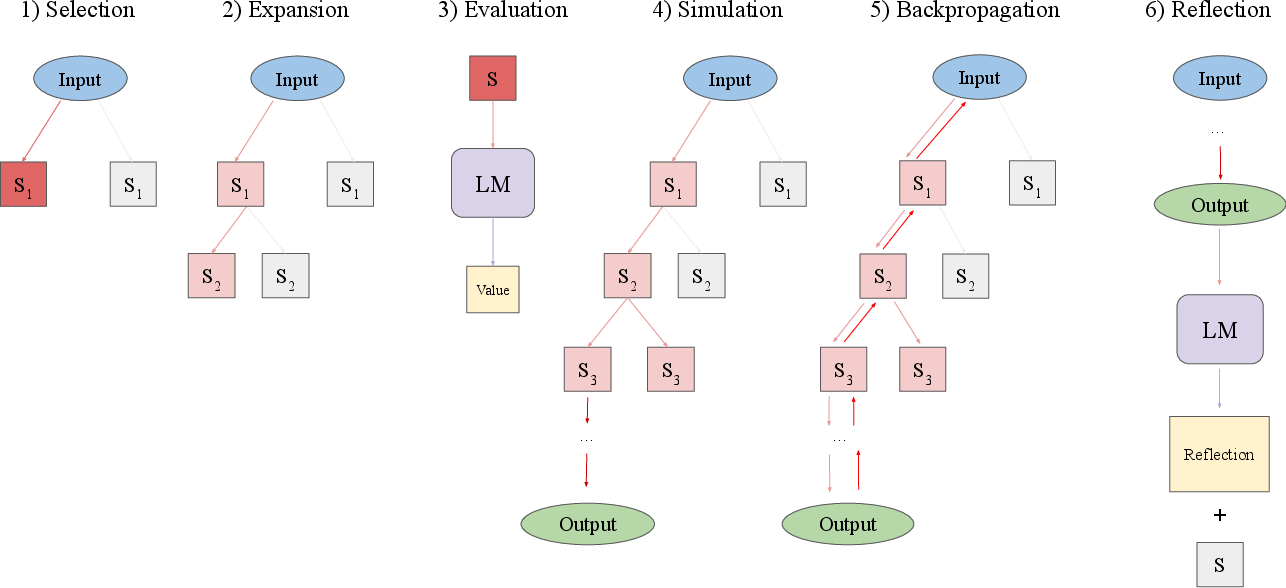
Figure 1: An overview of the six operations of LATS. A node is selected, expanded, evaluated, then simulated until a terminal node is reached, then the resulting value is backpropagated. If the trajectory fails, a reflection is generated and used as additional context for future trials. These operations are performed in succession until the budget is reached or task is successful.
Architecture
The LATS framework is comprised of several operations executed sequentially:
- Selection: Starts with node selection guided by UCT values, balancing the exploration-exploitation trade-offs.
- Expansion: Involves sampling multiple actions from the LLM to explore child nodes.
- Evaluation: These nodes are evaluated using an LM-based heuristic.
- Simulation: Simulates the progression from these nodes until a terminal state is reached.
- Backpropagation: Updates the tree by backpropagating the observed reward through the nodes.
- Reflection: Generates and integrates language-based reflections for augmenting future decision-making processes.
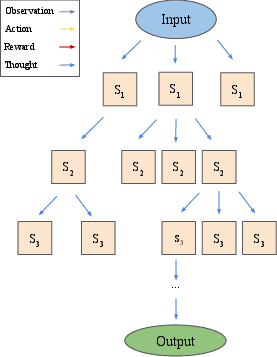
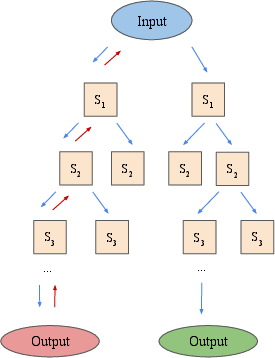
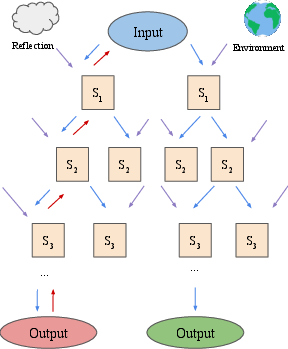
Figure 2: An overview of the differences between LATS and recently proposed LM search algorithms ToT and RAP, illustrating the integration of environmental feedback and self-reflection in LATS.
Experimental Results
LATS was evaluated over varying domains, from programming tasks to multi-hop question answering on the HotPotQA benchmark, and complex web navigation in WebShop. Results suggest significant improvements over existing approaches like ReAct, CoT, and RAP, using the same baseline LLMs.
Programming and QA Tasks
In programming tasks measured by the HumanEval dataset, LATS achieved a pass@1 rate of 94.4% with GPT-4, setting new benchmarks by outperforming previous methods. Meanwhile, in HotPotQA, LATS exhibited a 75.9 average score leveraging GPT-3.5, indicating superior reasoning and decision-making integration within LLMs.
Engagement with Interactive Environments
LATS also demonstrated notable performance in WebShop environments, achieving enhanced task scores and success rates. The ability to incorporate both web search and API calls as acting strategies highlights its adaptability to dynamic, information-rich contexts that extend beyond scripted interactions.
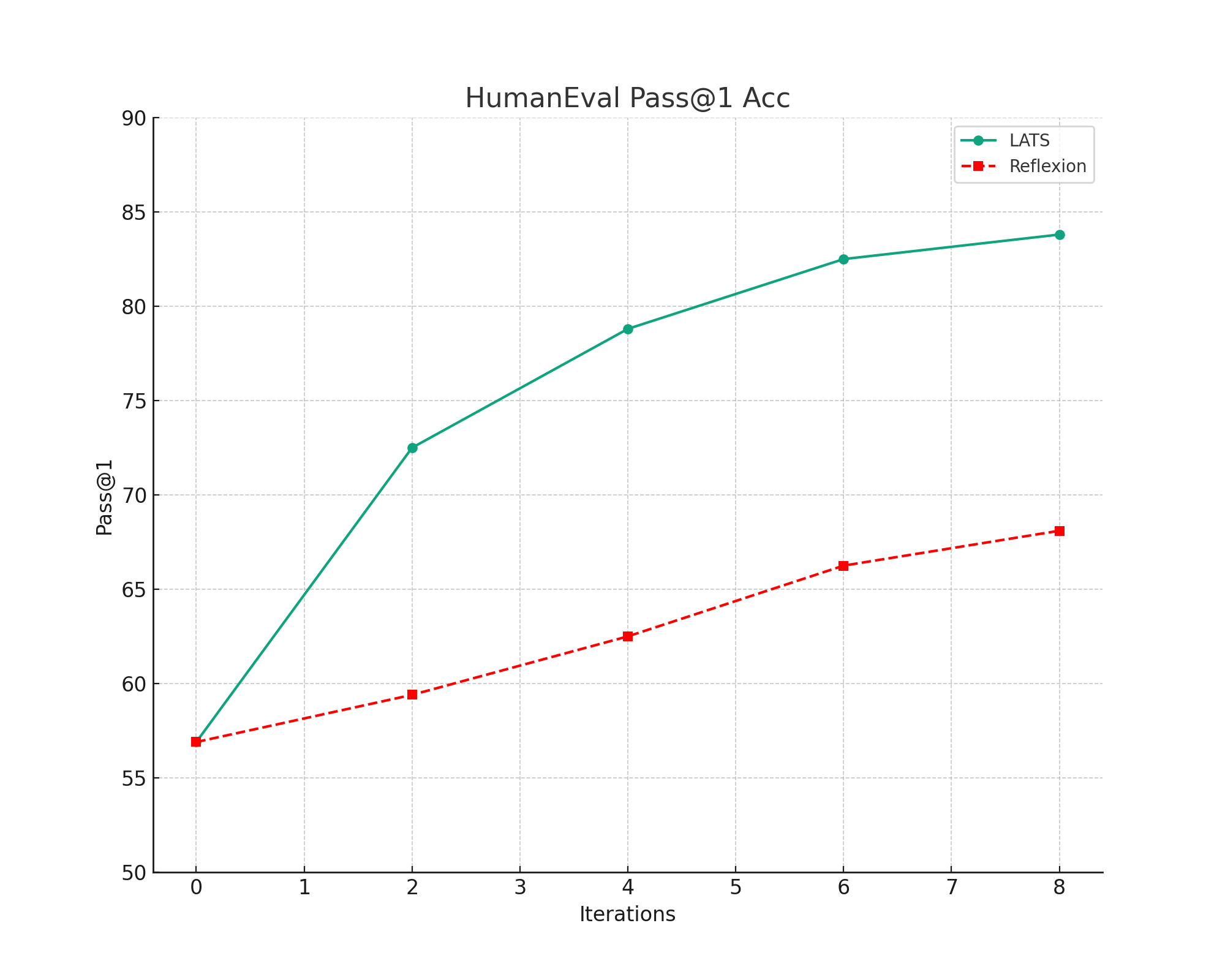
Figure 3: Ablation results on LATS and baseline variants in HotPotQA, indicating various configurations and impact on exact match rates. We sample n=5 and k=50 trajectories.
Implications and Future Directions
The introduction of LATS broadens the applicability of LLMs in real-world situations requiring adaptive reasoning and planning. Its design allows for greater exploration space in problem-solving, notably moving beyond the static response patterns of earlier models. Future work may focus on optimizing computational efficiency and extending LATS to even more complex open-world tasks, potentially integrating richer modalities and diverse input sources.
Conclusion
The proposed LATS framework represents a significant methodological advancement in the deployment of LLMs for reasoning and decision-making. By pioneering an approach that harmoniously combines reasoning, acting, and planning, LATS lays foundational work toward creating more autonomous, intelligently guided LLMs for an extensive array of applications. The framework's success across multiple domains indicates its robustness and sets the stage for further research in enhancing the decision-making capabilities of AI agents powered by LLMs.