- The paper introduces a novel backdoor attack that inserts non-visible Unicode characters in OCR outputs without altering benign performance.
- It employs pixel-level triggers across 60 model settings, achieving a 90% attack success rate even with 20% poisoning levels.
- The study highlights inherent vulnerabilities in OCR systems that can disrupt downstream NLP tasks, urging development of resilient detection methods.
Invisible Threats: Backdoor Attack in OCR Systems
Introduction
The paper "Invisible Threats: Backdoor Attack in OCR Systems" explores the susceptibility of Optical Character Recognition (OCR) systems to backdoor attacks, highlighting significant vulnerabilities. Primarily utilized for text extraction from images, OCRs are integral to numerous applications, from document classification to digital archiving. However, the integration of sophisticated Deep Neural Networks (DNNs) in OCR systems, while enhancing performance, opens up potential security risks from adversarial attacks, including backdoor and trojan attacks. This research introduces a novel backdoor attack on OCRs that aims to inject non-readable, invisible characters into output text without degrading performance on non-compromised inputs.
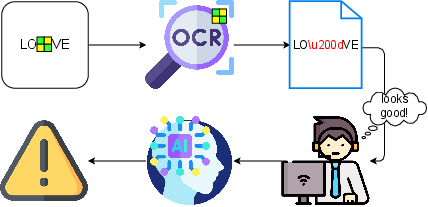
Figure 1: Overview of the attack. The character u200d is not printable, resulting in love.
Methodology
Backdoor Mechanisms
Backdoor attacks compromise the integrity of an AI model during the training phase by associating specific input patterns (triggers) with unintended behaviors. These triggers, when present during testing, activate the backdoor leading to controlled misclassifications or alterations without impacting performance on untriggered inputs. This research advances this domain by embedding backdoors that insert non-visible UNICODE characters into text, specifically zero-width space characters, which can disrupt downstream NLP applications without alerting end users.
Experimental Design
A diverse dataset was generated using Shakespearean literature rendered in various typographic styles to simulate realistic OCR inputs. The study deployed Calamari-OCR for its experiments due to its prowess in handling a wide gamut of typography with high accuracy. The backdoor was embedded by utilizing pixel-level triggers that either overlapped or were adjacent to text characters. The research conducted rigorous trials on 60 distinct model settings involving different levels of trigger visibility and poisoning rates in the dataset.

Figure 2: Grayscale, on top of the letter a.
Results
The experiments convincingly demonstrated that the attack could effectively introduce invisible characters in 90% of poisoned instances without degrading recognition accuracy. The Character Error Rate (CER) remained consistently low, indicating that the benign performance of the OCR was retained despite the presence of backdoors.
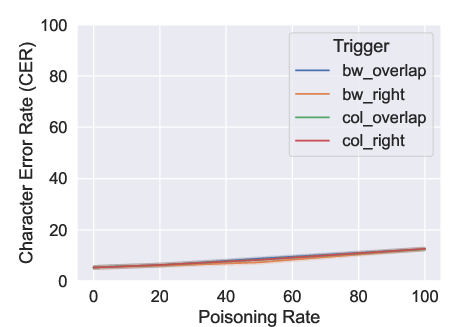
Figure 3: CER on the clean test set. We tested four distinct triggers based on the palette (i.e., BW = black and white, col = color) and position (i.e., overlap = overlapped with the letter, right = shifted on the right of the letter).
High attack success rates were achieved with even minimal poisoning levels of 20%, showing the robustness of this approach in subverting OCR outputs stealthily. Variability in font susceptibility was observed, with italicized fonts proving more vulnerable to these attacks than bolder types, attributed to differences in visual clutter and trigger masking effect.
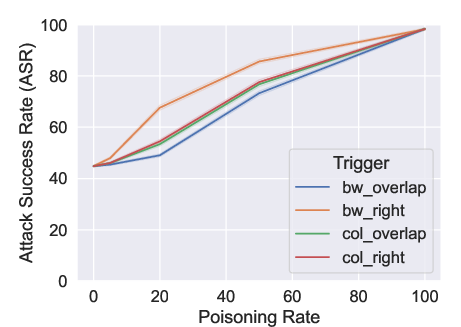
Figure 4: ASR on the poisoned test set. We tested four distinct triggers based on the palette (i.e., BW = black and white, col = color) and position (i.e., overlap = overlapped with the letter, right = shifted on the right of the letter).
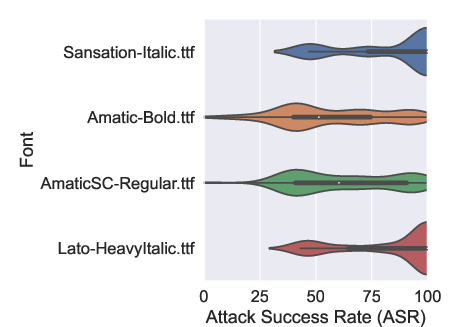
Figure 5: ASR at the varying of four representative fonts.
Implications and Future Work
The outcomes of this study highlight critical security vulnerabilities in OCR systems that could potentially disrupt NLP pipelines extensively. The insertion of invisible characters can bypass threat detection and lead to erroneous outputs by NLP systems, such as sentiment misclassification or machine translation errors, thereby endangering decision-making processes relying on such models. Future work could explore resilient OCR design to prevent such backdoor vulnerabilities, refining detection algorithms to identify hostile triggers, and developing fail-safes in NLP models to handle unexpected character inputs.
Conclusion
This research identifies a stealthy and effective method to compromise OCR systems using non-visible character insertion via backdoor attacks. Given the high success rate and minimal impact on non-targeted OCR functionality, this form of attack presents an alarming pathway for adversaries intending to disrupt text analysis frameworks relying on OCR technologies. Adequate countermeasures remain an area ripe for exploration to safeguard AI deployments against such invisible threats.