- The paper presents a novel framework, AdamD, that decouples weight decay from moment estimation, ensuring convergence for nonsmooth neural network optimization.
- It establishes convergence guarantees under non-diminishing learning rates, with numerical evidence from image classification and language modeling tasks.
- Experimental results on CIFAR-10/100 and Penn Treebank illustrate AdamD's competitive generalization performance compared to AdamW and other Adam-family methods.
"Adam-family Methods with Decoupled Weight Decay in Deep Learning" (2310.08858)
Overview
The paper presents an analysis and expansion of decoupled weight decay in Adam-family optimization methods, particularly focusing on nonsmooth nonconvex optimization problems commonly encountered when training neural networks with weight regularization.
Proposed Framework
The authors propose the Adam-family Methods with Decoupled Weight Decay (AFMDW) framework, inspired by AdamW, with a decoupling mechanism in weight decay. This allows first-order and second-order moment estimators to be updated independently from the weight decay term, aiming to offer convergence guarantees for nonsmooth neural networks. The framework targets problems characterized by the equation:
x∈Rming(x):=f(x)+2σ∥x∥2
where f is locally Lipschitz continuous and possibly nonsmooth, σ>0 is a penalty parameter enforcing weight decay.
Convergence Properties
The paper establishes convergence properties under mild assumptions and with non-diminishing learning rates. Specifically, the proposed framework converges to a stationary point, defined in the sense of conservative fields, while asymptotically approximating the behavior of SGD. The results show:
- Convergence: Any cluster point is a Dg-stationary point, where Dg is a conservative field.
- Efficiency: Asymptotically aligns with SGD, suggesting potential improvements in generalization.
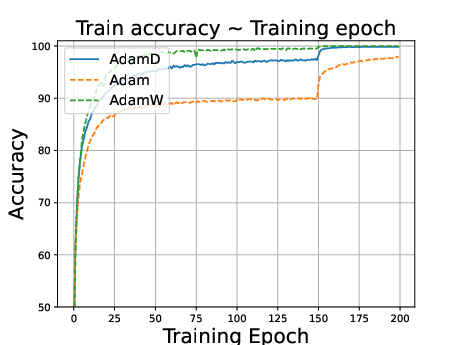
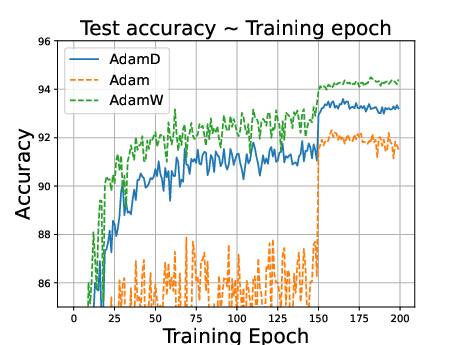
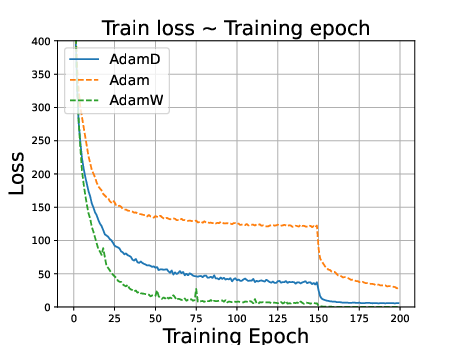
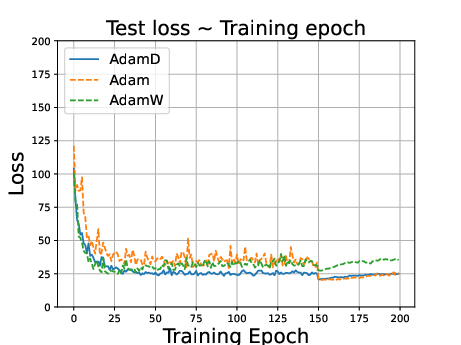
Figure 1: ResNet34 on CIFAR10 dataset. Stepsize is reduced to 0.1 times of the original value at the 150th epoch.
Adam with Decoupled Weight Decay (AdamD)
The paper introduces AdamD, a variant of the Adam method that adheres to the AFMDW framework, and provides:
- Convergence Guarantees: Under conditions commonly observed in real-world applications.
- Generalization Performance: Demonstrated through numerical experiments.
Numerical Experiments
Experiments on CIFAR-10, CIFAR-100, and Penn Treebank datasets using models like ResNet34, DenseNet121, and LSTMs demonstrate that:
- AdamD outperforms Adam and performs comparably to AdamW in image classification tasks.
- In language modeling, AdamD excels compared to AdamW, highlighting versatility across domains.
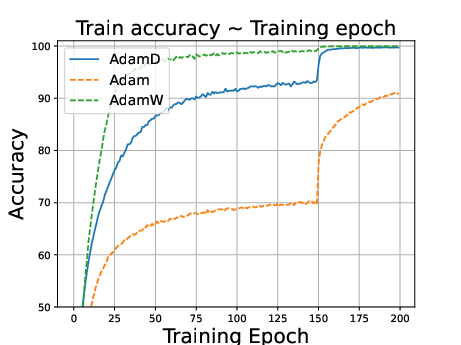
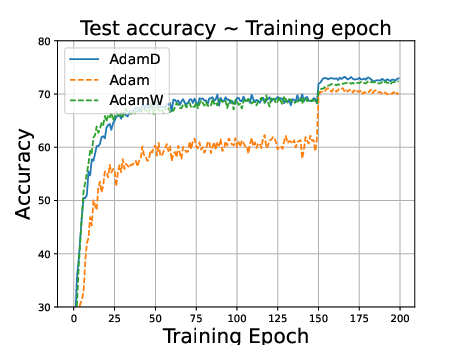
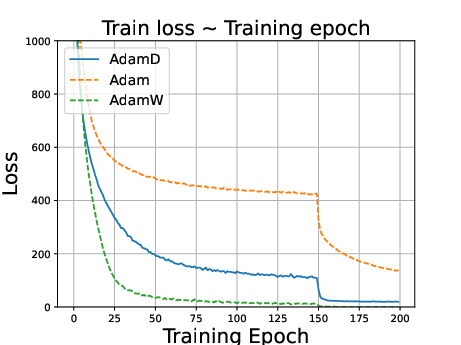
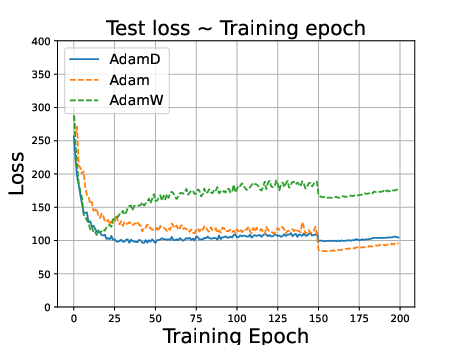
Figure 2: ResNet34 on CIFAR100 dataset. Stepsize is reduced to 0.1 times of the original value at the 150th epoch.
Discussion
- Decoupled Regularization: The decoupling of weight decay is equivalent to employing quadratic regularization directly, addressing theoretical gaps observed in AdamW's interpretative paradigms.
- Practical Implications: Convergence analysis provides theoretical affirmation for practical observations of decoupled weight's efficacy in generalization.
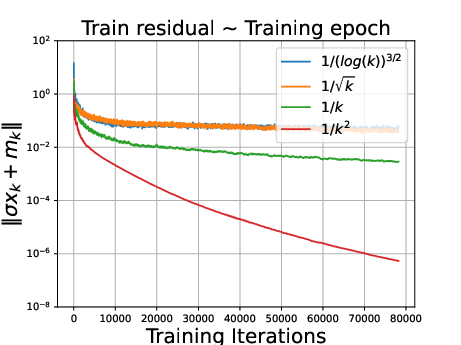
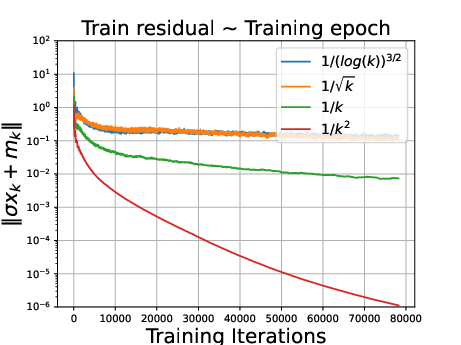
Figure 3: ∥σxk+mk∥ under different decay.
Conclusion
The study explores the theoretical underpinnings of the Adam-family methods enhanced with decoupled weight decay, offering a robust framework fortified with convergence guarantees. AdamD emerges as a promising optimizer that balances convergence speed and generalization—a pivotal contribution towards deep learning optimization strategies.
By design, the paper roots its assertions in both numerical evidence and theoretical rigor, reinforcing the applicability of decoupled weight decay as a crucial improvement in adaptive gradient methods.