- The paper introduces a novel forced alignment approach that treats acoustic modeling as a tagging task to better capture overlapping speech segments.
- The study employs interpolation between discrete time steps, achieving a 27.92% improvement in boundary precision compared to traditional 10 ms granularity methods.
- Empirical evaluations on the TIMIT and Buckeye corpora demonstrate that MAPS outperforms the Montreal Forced Aligner with lower mean and median absolute errors in boundary placement.
The Mason-Alberta Phonetic Segmenter: A Neural-Based Forced Alignment System
Introduction to Forced Alignment Systems
Forced alignment systems play a critical role in phonetics by automatically determining segment boundaries in speech data when paired with an orthographic transcription. The Mason-Alberta Phonetic Segmenter (MAPS) represents a neural network-driven advancement in this domain, enabling enhancements in accuracy and boundary precision over traditional methods. The present paper examines improvements introduced by treating acoustic modeling as a tagging task rather than a classification task and incorporating interpolation for more refined boundary placements.
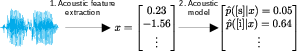

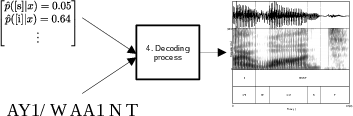
Figure 1: Flowchart diagram of forced alignment process. Sections (a) and (b) are parallel and independent streams that merge in (c), resulting in an alignment displayed with a spectrogram or waveform.
Theoretical Developments in Acoustic Modeling
Segment Classification through Tagging
Traditional forced aligners often utilize a classification-based approach, constrained by assumptions of discrete segment representation. The authors propose an innovative shift to a tagging paradigm, motivated by the inherent overlap and continuous nature of speech sounds. This approach reimagines the acoustic model as a multi-label classifier, allowing multiple segment categories to receive non-zero probabilities. This strategy aligns more closely with the real-world acoustic similarities observed among segments, potentially increasing the robustness of segment detection.
Boundary Placement with Interpolation
A longstanding challenge in forced aligners is the 10 ms granularity limitation when calculating acoustic features such as MFCCs. By implementing interpolation between discrete time steps, the MAPS system achieves significantly increased boundary precision. This technique enhances the placement accuracy beyond the coarse 10 ms intervals, allowing for a 27.92% improvement in boundaries within a 10 ms target—substantially better than current state-of-the-art systems.
Empirical Evaluation and Model Comparisons
The paper presents a rigorous comparison of different system configurations of the MAPS against the Montreal Forced Aligner (MFA), utilizing both the TIMIT and Buckeye corpora. Notably, the MAPS with interpolation consistently outperformed its counterparts, achieving lower mean and median absolute errors in boundary placement. This positions the MAPS as a strong competitor to the MFA, particularly in phonetic accuracy and the reliability of boundaries within stringent error tolerances.
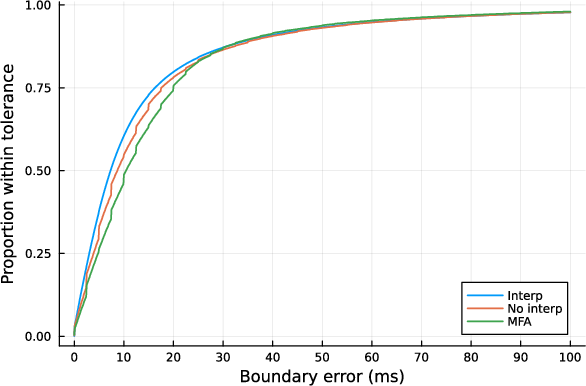
Figure 2: Cumulative density function for crisp networks and Montreal Forced Aligner. The Interp'' line shows the system's performance using interpolation, highlighting improved accuracy over theNo interp'' approach and the ``MFA'' benchmark.
Practical and Theoretical Implications
The introduction of MAPS illustrates significant progress in the practical application of neural architectures for speech processing tasks. By leveraging deep neural networks, the system provides a powerful alternative in the field of phonetic alignment, particularly relevant for linguists and speech technologists dealing with vast datasets where manual transcription is infeasible. The proposed tagging method and boundary interpolation suggest new pathways for addressing long-standing theoretical challenges in the discreteness versus continuity of speech perception and representation.
Conclusion and Future Directions
The Mason-Alberta Phonetic Segmenter stands as a transformative tool in the field of forced alignment, successfully integrating neural network advancements to enhance boundary precision and classification accuracy. The research encourages further exploration of multi-label classification and sophisticated interpolation techniques, aiming to close the gap between theoretical phonetic models and empirical aligner performance. Additionally, expanding the system's adaptability across diverse linguistic datasets and refining feature extraction methodologies remain promising future directions.