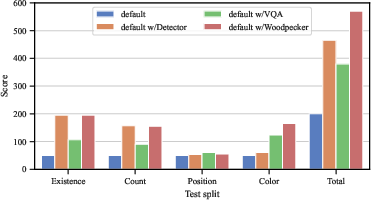
- The paper introduces Woodpecker, a novel training-free framework that leverages pre-trained models to correct hallucinations in MLLMs, improving accuracy by up to 30.66%.
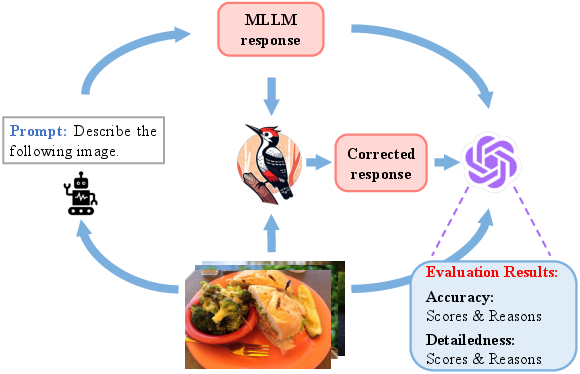
- The methodology consists of key concept extraction, question formulation, visual validation, knowledge base generation, and final correction using bounding box visualizations.
- Evaluation on benchmarks such as POPE, MME, and LLaVA-QA90 demonstrates enhanced object and attribute-level accuracy in multimodal outputs.
"Woodpecker: Hallucination Correction for Multimodal LLMs" Analysis
Introduction
The paper "Woodpecker: Hallucination Correction for Multimodal LLMs" (2310.16045) addresses the prevalent issue of hallucinations in Multimodal LLMs (MLLMs). Hallucinations refer to scenarios where generated texts are inconsistent with the corresponding input images. This phenomenon poses significant challenges to the practical applicability of MLLMs. While earlier approaches have primarily focused on instruction-tuning methods necessitating retraining with specific data, this paper introduces a novel, training-free methodology known as Woodpecker, which directly corrects hallucinations post-generation.
Methodology
Woodpecker is designed to be a training-free framework that leverages pre-trained models for hallucination correction across five distinct stages:
- Key Concept Extraction: Identifies the primary objects and concepts in the generated text that are likely to exhibit hallucinations. This extraction relies on the use of LLMs to parse key concepts effectively.
- Question Formulation: Constructs questions around the extracted key concepts, targeting both object-level and attribute-level hallucinations. Questions are formulated to validate the existence, number, and attributes of objects mentioned in the text.
- Visual Knowledge Validation: Utilizes expert models such as open-set object detectors and Visual Question Answering (VQA) systems to answer the formulated questions. These models provide information about object existence and attributes without the need for retraining.
- Visual Claim Generation: Converts the validated question-answer pairs into a structured visual knowledge base. This base serves as a comprehensive repository for object-level and attribute-level claims about the image.
- Hallucination Correction: An LLM uses the visual knowledge base to refine hallucinations in the original text, ensuring improved accuracy and reliability. Bounding boxes are included for referenced objects to enhance interpretability.

Figure 1: Framework of Woodpecker. Given an image and a query, an MLLM outputs the corresponding response. Through various steps, a visual knowledge base is created for hallucination correction.
Results
The Woodpecker framework was evaluated on multiple datasets including POPE, MME, and LLaVA-QA90 to determine its efficacy in correcting hallucinations.
Implications and Future Work
Woodpecker stands out as a pioneering framework that addresses hallucinations without the need for expensive retraining processes, leveraging pre-existing models. This advancement implies significant practical implications for deploying MLLMs in real-world applications, ensuring more reliable and interpretable outputs.
Future directions of this work could explore the expansion of the framework to handle broader ranges of hallucinations across more diverse datasets. Additionally, enhancing the capacity of the system to interpret more complex interactions and relationships within images can further bolster the practical utility of MLLMs.
Conclusion
"Woodpecker: Hallucination Correction for Multimodal LLMs" presents a compelling approach to tackling hallucinations in generated text descriptions from MLLMs. The proposed framework combines interpretability with practicality by utilizing existing models and avoiding retraining. Substantial improvements across multiple datasets affirm Woodpecker’s potential as an invaluable tool for refining multimodal outputs and advancing the state of MLLM reliability.