- The paper introduces Coop, which co-optimizes tensor allocation and rematerialization with a sliding window algorithm to reduce memory fragmentation.
- It employs cheap tensor partitioning and recomputable in-place operations to lower compute overhead by up to 30% under strict memory ratios.
- Coop outperforms state-of-the-art techniques in search latency and efficiency across models like GPT-3 and BERT Large.
Coop: Memory is not a Commodity
Introduction
The paper "Coop: Memory is not a Commodity" (2311.00591) addresses the limitations of existing tensor rematerialization techniques in deep learning frameworks by introducing Coop, a method that co-optimizes tensor allocation and rematerialization. Traditional methods overlook memory systems, leading to inefficiencies due to fragmented memory and increased recomputation costs. Coop proposes a sliding window algorithm for evicting contiguous tensors and introduces innovations such as cheap tensor partitioning and recomputable in-place operations, achieving improved memory usage and computational efficiency.
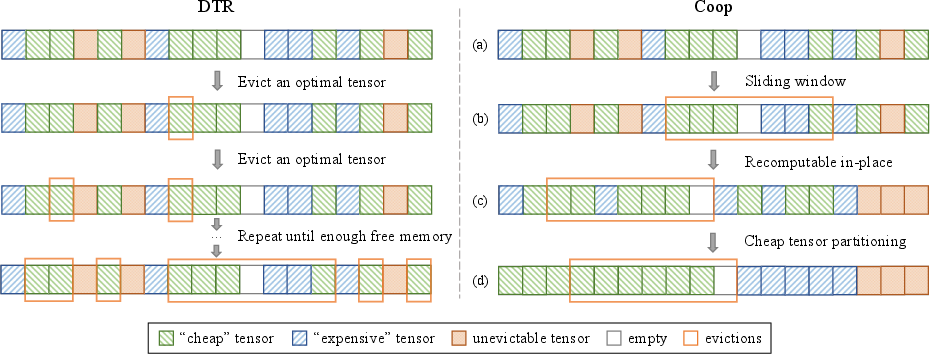
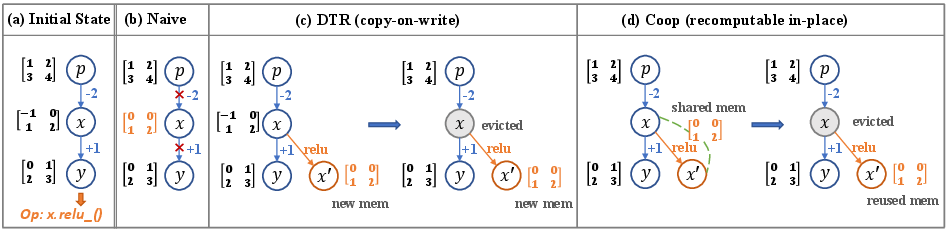
Figure 1: Comparison between DTR and Coop. DTR overlooks the underlying memory system, resulting in redundant evictions, whereas Coop optimizes tensor rematerialization and allocation.
Background and Motivation
Tensor rematerialization, also known as activation checkpointing, is pivotal in training large DNNs with limited memory. Existing techniques assume fungible memory, leading to fragmentations when tensors are evicted non-contiguously. Coop addresses this by using a sliding window for contiguous tensor eviction, reducing memory fragmentation. DNN frameworks' memory allocators, while simpler compared to CPUs, suffer when chunked memory is not released for new tensors, motivating Coop's approach to optimal tensor co-location and recomputation minimization.
Methodology
Coop implements three core modules designed to optimize both tensor allocation and rematerialization:
- Sliding Window Algorithm: This efficiently finds contiguous tensors for eviction, optimizing search time from O(2N) to O(N). This approach addresses the traditional overhead caused by fragmentations, reducing the need for repeated evictions.
- Cheap Tensor Partitioning: Tensors are classified by computational cost density and allocated on opposite ends of the memory pool. This separation ensures low-cost tensors are evicted first, optimizing overall system memory availability and reducing unnecessary recomputations.
- Recomputable In-place Operations: Inspired by functional in-place paradigms, Coop reuses memory blocks for in-place operations without additional allocations, crucially allowing parameters to remain contiguous in memory, thus reducing fragmentation (Figure 2).
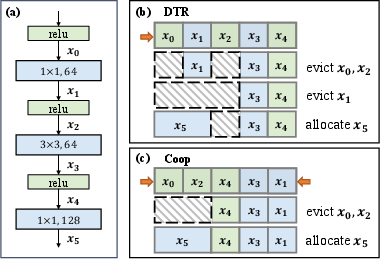
Figure 2: Illustration of cheap tensor partitioning in Coop. Tensors are allocated from both sides of the memory pool to optimize eviction efficiency.
Evaluation
Coop was evaluated against state-of-the-art methods, namely DTR and DTE, across eight DNNs, including GPT-3 and ResNet variants. The evaluations used multiple performance metrics such as compute overhead, search latency, and memory fragmentation rate:
Conclusion
Coop substantively improves tensor rematerialization by integrating memory system awareness into deep learning training frameworks, minimizing memory fragmentation, and lowering compute overhead. Its co-optimization strategy of tensor rematerialization and allocation leverages memory efficiently, thereby enabling the better handling of large-scale models under limited memory conditions. Future exploration of Coop could involve its integration with heterogeneous memory systems or extended techniques for handling swaps in distributed training environments. Such advancements might offer further substantial improvements in training large, dynamic DNN workloads more efficiently.