- The paper introduces KGR, a framework that retrofits LLM responses by extracting and verifying factual claims using knowledge graphs.
- It outlines a multi-stage process including claim extraction, entity detection, fact selection, and response retrofitting to enhance factual accuracy.
- Experimental evaluations on QA benchmarks show improved EM and F1 scores, demonstrating KGR’s effectiveness in reducing hallucinations.
Mitigating LLM Hallucinations via Knowledge Graph-based Retrofitting
This essay discusses the framework outlined in the paper titled "Mitigating LLM Hallucinations via Autonomous Knowledge Graph-based Retrofitting." The framework, known as KGR, aims to address the factual hallucination challenges associated with LLMs by leveraging trusted sources such as Knowledge Graphs (KGs).
Introduction
LLMs like ChatGPT and LLaMA have become increasingly prominent across different domains. However, a common problem with LLMs is factual hallucination, where incorrect information is generated due to the models' lack of intrinsic factual knowledge. KGR provides a novel approach to retrofitting model responses based on factual data retrieved from KGs, autonomously refining, extracting, verifying, and selecting factual claims within generated responses, enhancing the reliability of LLMs.
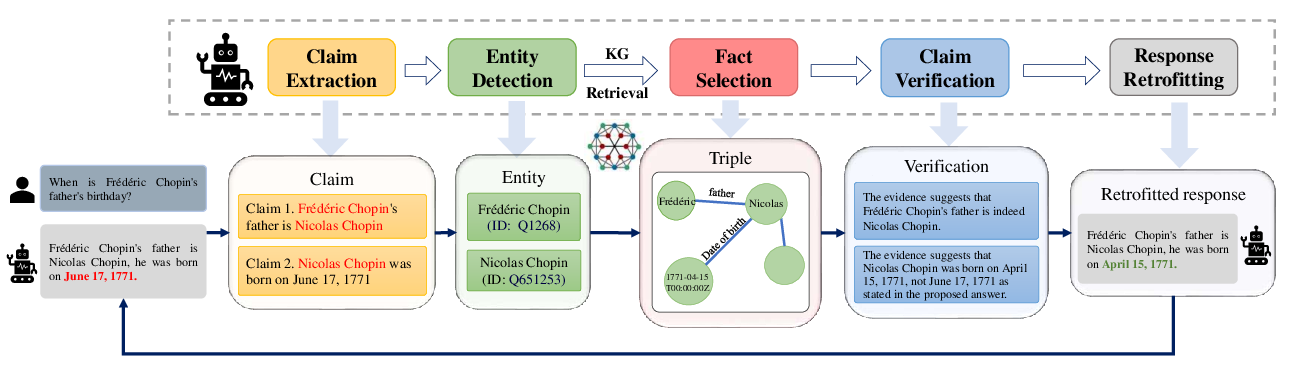
Figure 1: An overview of KGR and its key components for iterative error mitigation in LLM responses.
Framework Overview
KGR operates through multiple stages:
- Claim Extraction: LLMs extract factual claims from model-generated responses requiring verification. This decomposition allows for detailed scrutiny against KG data.

Figure 2: Example for the claim extraction in KGR, decomposing the draft answer into atomic claims.
- Entity Detection and KG Retrieval: After identifying critical entities within the extracted claims, the framework retrieves appropriate triples from a KG, allowing for comprehensive verification across similar entities.

Figure 3: Example for the entity detection in KGR, extracting essential entities from the claim.
- Fact Selection: This process addresses the model's limited context window by partitioning retrieved triples into chunks, prompting LLMs to select relevant facts to facilitate efficient retrofitting.

Figure 4: Example of fact selection in KGR, prompting LLMs to pinpoint crucial items.
- Claim Verification and Response Retrofitting: Finally, selected triples from KG are compared against initial claims. LLMs utilize verification outcomes to refine and retrofit model-generated responses dynamically.

Figure 5: Example of claim verification and response retrofitting in KGR.
Each step can be iteratively repeated to ensure alignment of all claims with KG-stored knowledge.
Experimental Evaluation
The paper focuses on three QA benchmarks: Simple Question, Mintaka, and HotpotQA, incorporating reasoning tasks of varying difficulty levels. KGR was evaluated using different LLM models including ChatGPT and text-davinci-003.
(Tables and experimentation results are not visibly represented here but detailed numeric outcomes showed increased efficacy in mitigating hallucination, notably enhancing EM scores and F1 marks across different datasets.)
Error Analysis
Further analysis demonstrated that errors primarily stem from entity detection and fact selection stages. Subsequent experimental results indicated minimal impact from chunk size but notable influence of the number of retrieved triples on the fact selection precision and recall.
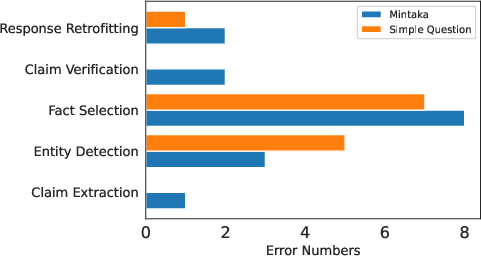
Figure 6: Distribution of error case numbers across KGR stages.
Impact of Multi-Turn Retrofitting
Multi-turn retrofitting further refines complex reasoning through recurring processes to align all claims with supportive evidence from the KG, mitigating the risk of introducing discrepancies in factual assertions by relying on sound, repetitive data sources.
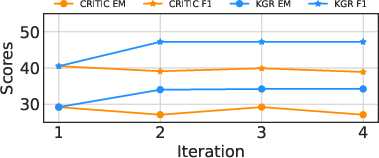
Figure 7: Behavior of KGR and CRITIC under multi-turn retrofitting.
Conclusion
The Knowledge Graph-based Retrofitting framework significantly improves LLM performance in factual QA contexts by effectively extracting, verifying, and refining information during reasoning processes. As future directions, it calls for advancements in enhancing granularity within claim extraction and entity detection using sophisticated integration with KGs.