- The paper introduces the PointDif framework, which pre-trains point cloud networks via a conditional diffusion model to robustly recover geometric details from noisy data.
- It leverages a Conditional Point Generator—comprising CANet for feature aggregation and CPDM for iterative point reconstruction—to capture local and global structures.
- Experimental results demonstrate significant performance improvements across classification, segmentation, and detection tasks on challenging 3D datasets.
An Analysis of "Point Cloud Pre-training with Diffusion Models" (2311.14960)
Introduction
The paper "Point Cloud Pre-training with Diffusion Models" addresses the challenges associated with pre-training models for point cloud data. Unlike structured 2D image data, point clouds have unordered and non-uniform density characteristics, making it difficult to employ traditional pre-training techniques effectively. This paper introduces a novel pre-training framework called PointDif, positioning it as a method to enhance the efficacy of point cloud backbones by leveraging diffusion models. The proposed approach views point cloud pre-training as a conditional point-to-point generation task, utilizing a uniquely designed conditional point generator to learn both local and global geometric priors.
Methodology
The core innovation in this work is the introduction of the PointDif framework. At the heart of this framework is the diffusion model which iteratively refines a noisy point cloud back to its original state, inspired by the diffusion model's inherent strengths in gradual denoising processes. This is operationalized within a system that comprises a Conditional Point Generator, which includes a Condition Aggregation Network (CANet) and a Conditional Point Diffusion Model (CPDM). CANet globally aggregates features extracted by the backbone, and CPDM uses these aggregated features to guide a step-by-step recovery of the original point cloud from noisy inputs.
Figure 1
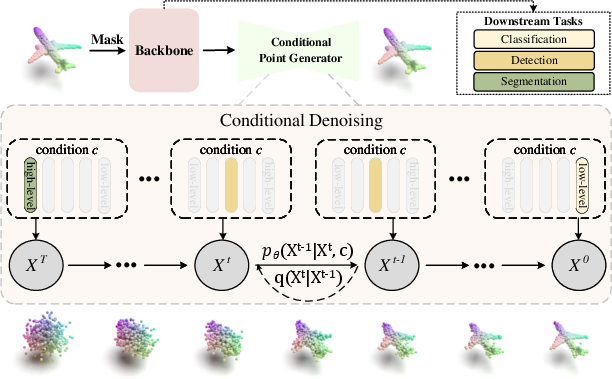
Figure 1: Schematic illustration of our PointDif showing how PointDif can pre-train different backbones through point-to-point reconstruction from the noisy point cloud.
The framework also introduces a recurrent uniform sampling strategy that segments diffusion time steps into multiple intervals, allowing for more balanced supervision during training. This method helps the model uniformly handle diverse noise levels, contributing to robust learning of hierarchical geometric properties.
Experimental Results
Extensive experiments demonstrate that PointDif significantly enhances the performance of point cloud backbones across a variety of real-world tasks, such as classification, segmentation, and detection.
Figure 2
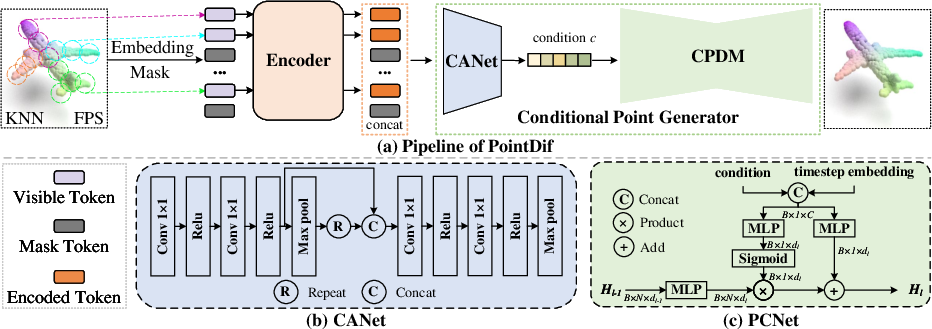
Figure 2: Detailed pipeline of PointDif, including the process of embedding, encoding, and conditional recovery using CANet and CPDM.
- Classification Tasks: On the ScanObjectNN dataset, PointDif notably improves overall accuracy in challenging settings, indicating robust learning of shape semantics.
- Segmentation Tasks: In semantic segmentation scenarios, particularly on the S3DIS and SemanticKITTI datasets, PointDif's design enables better contextual and geometric comprehension, outperforming other methods.
- Detection Tasks: For object detection in structured scenes like ScanNet, the framework's pre-training advantages are evident, providing a marked performance boost over models trained from scratch or with alternative pre-training approaches.
Figure 3
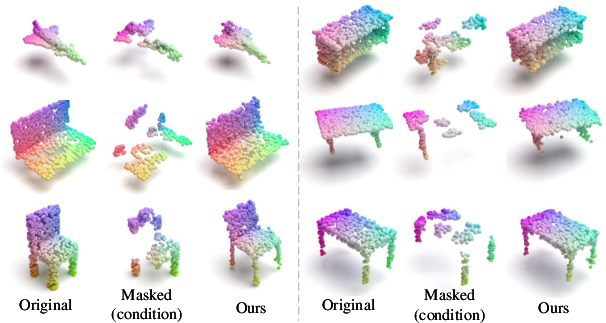
Figure 3: Visualization results on ShapeNet validation set showing input, masked, and reconstructed point clouds produced by PointDif, maintaining high quality even with 80\% masking.
Discussion
The paper substantiates PointDif's effectiveness not only through improved performance metrics across tasks but also through qualitative visualizations. It shows PointDif's ability to produce high-quality reconstructions from heavily masked point clouds, which points to its prowess in capturing both local details and global geometry.
Implications: The use of diffusion models for point cloud pre-training signifies a compelling shift in strategy, converging generative capabilities with deep learning backbones in innovative ways. This approach lays groundwork for further explorations into diffusion-based models in 3D spaces and possibly integrating these techniques in fields like autonomous driving and augmented reality, where explicit 3D comprehension and manipulation are pivotal.
Future Directions: As the field advances, there is space to explore the full potential of PointDif in broader contexts, such as integrating with multimodal frameworks or adapting to unsupervised 3D scene understanding. Scaling these methods to accommodate more complex and diverse datasets, both synthetic and real, could broaden its applicability.
Conclusion
The paper provides a well-structured introduction of a diffusion-model based method for point cloud pre-training. The PointDif framework sets a precedent for leveraging conditional diffusion models in geometrically complex data environments, yielding demonstrable improvements in downstream task performance. By incorporating innovative data processing and sampling strategies, this research lays a cornerstone for potential future advancements in 3D data processing technologies.
