Uncertainty-aware Language Modeling for Selective Question Answering
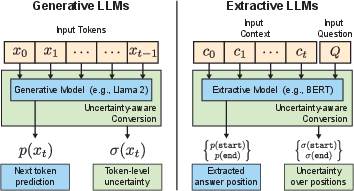
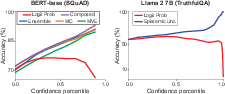
Abstract: We present an automatic LLM conversion approach that produces uncertainty-aware LLMs capable of estimating uncertainty with every prediction. Our approach is model- and data-agnostic, is computationally-efficient, and does not rely on external models or systems. We evaluate converted models on the selective question answering setting -- to answer as many questions as possible while maintaining a given accuracy, forgoing providing predictions when necessary. As part of our results, we test BERT and Llama 2 model variants on the SQuAD extractive QA task and the TruthfulQA generative QA task. We show that using the uncertainty estimates provided by our approach to selectively answer questions leads to significantly higher accuracy over directly using model probabilities.
- Amini, A.; et al. 2023. Capsa Software Library.
- Weight uncertainty in neural network. In International conference on machine learning, 1613–1622. PMLR.
- Quantifying Uncertainty in Answers from any Language Model and Enhancing their Trustworthiness. arXiv:2308.16175.
- DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. arXiv:2309.03883.
- Human Uncertainty in Concept-Based AI Systems. arXiv:2303.12872.
- Deep gaussian processes. In Artificial intelligence and statistics, 207–215. PMLR.
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805.
- Confidence modeling for neural semantic parsing. arXiv preprint arXiv:1805.04604.
- El-Yaniv, R.; et al. 2010. On the Foundations of Noise-free Selective Classification. Journal of Machine Learning Research, 11(5).
- Dropout as a bayesian approximation: Representing model uncertainty in deep learning. In international conference on machine learning, 1050–1059. PMLR.
- Selective classification for deep neural networks. Advances in neural information processing systems, 30.
- Posing fair generalization tasks for natural language inference. arXiv preprint arXiv:1911.00811.
- A framework for merging and ranking of answers in DeepQA. IBM Journal of Research and Development, 56(3.4): 14–1.
- On calibration of modern neural networks. In International conference on machine learning, 1321–1330. PMLR.
- A survey on automated fact-checking. Transactions of the Association for Computational Linguistics, 10: 178–206.
- How can we know when language models know? on the calibration of language models for question answering. Transactions of the Association for Computational Linguistics, 9: 962–977.
- Selective question answering under domain shift. arXiv preprint arXiv:2006.09462.
- Nemo: a toolkit for building ai applications using neural modules. arXiv preprint arXiv:1909.09577.
- Simple and scalable predictive uncertainty estimation using deep ensembles. Advances in neural information processing systems, 30.
- Improving the repeatability of deep learning models with Monte Carlo dropout. npj Digital Medicine, 5(1): 174.
- Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958.
- Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models. arXiv:2305.19187.
- Capsa: A Unified Framework for Quantifying Risk in Deep Neural Networks. In 5th Robot Learning Workshop: Trustworthy Robotics.
- Capsa: A Unified Framework for Quantifying Risk in Deep Neural Networks. arXiv:2308.00231.
- SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. arXiv:2303.08896.
- SelfCheck: Using LLMs to Zero-Shot Check Their Own Step-by-Step Reasoning. arXiv:2308.00436.
- Dropconnect is effective in modeling uncertainty of bayesian deep networks. Scientific reports, 11(1): 5458.
- Estimating the mean and variance of the target probability distribution. In Proceedings of 1994 ieee international conference on neural networks (ICNN’94), volume 1, 55–60. IEEE.
- Overview of ResPubliQA 2009: Question answering evaluation over European legislation. In Multilingual Information Access Evaluation I. Text Retrieval Experiments: 10th Workshop of the Cross-Language Evaluation Forum, CLEF 2009, Corfu, Greece, September 30-October 2, 2009, Revised Selected Papers 10, 174–196. Springer.
- Conformal Language Modeling. arXiv:2306.10193.
- Know What You Don’t Know: Unanswerable Questions for SQuAD. arXiv:1806.03822.
- SQuAD: 100,000+ Questions for Machine Comprehension of Text. arXiv:1606.05250.
- Quizbowl: The Case for Incremental Question Answering. arXiv:1904.04792.
- BLEURT: Learning robust metrics for text generation. arXiv preprint arXiv:2004.04696.
- Post-hoc Uncertainty Learning using a Dirichlet Meta-Model. arXiv:2212.07359.
- Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1): 1929–1958.
- Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Wang, M.; et al. 2006. A survey of answer extraction techniques in factoid question answering. Computational Linguistics, 1(1): 1–14.
- Large language models are reasoners with self-verification. arXiv preprint arXiv:2212.09561.
- Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv:1609.08144.
- Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In Proceedings of the IEEE international conference on computer vision, 19–27.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.