- The paper introduces a novel MAQA dataset with over 2,000 multi-answer questions to probe data uncertainty in LLM outputs.
- It evaluates five uncertainty quantification methods, demonstrating that entropy and response consistency effectively measure model reliability.
- Experiments reveal LLM overconfidence in reasoning tasks, highlighting challenges in distinguishing model uncertainty from data uncertainty.
Evaluating Uncertainty Quantification in LLMs Regarding Data Uncertainty
Introduction to Uncertainty Quantification in LLMs
The study titled "MAQA: Evaluating Uncertainty Quantification in LLMs Regarding Data Uncertainty" investigates the capacity of LLMs to quantify uncertainty, particularly in scenarios involving data uncertainty. Addressing the issue of LLM-generated plausible yet incorrect responses, this research emphasizes the necessity of uncertainty quantification to enhance LLM reliability, distinguishing between model uncertainty (epistemic) and data uncertainty (aleatoric).
Uncertainty quantification allows for the determination of whether to accept or reject model outputs based on assigned confidence values. Traditional approaches primarily explore model uncertainty in single-answer scenarios, but this paper extends the analysis to questions with multiple possible correct answers, inherently incorporating data uncertainty (Figure 1).
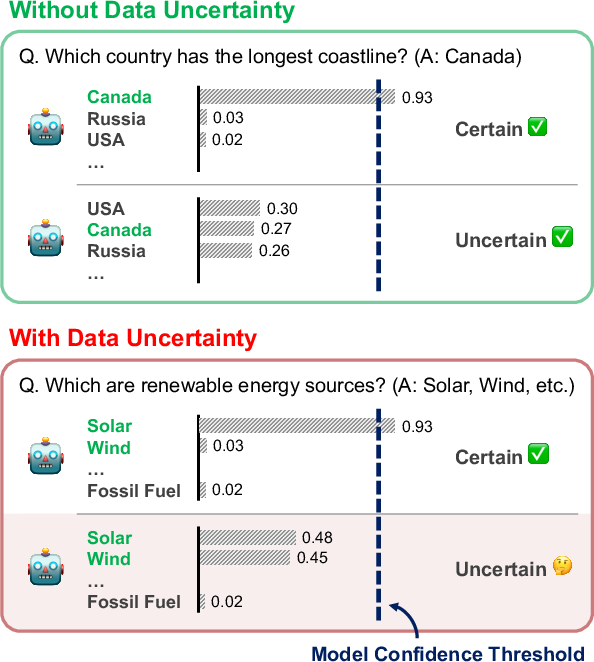
Figure 1: Evaluation settings with and without data uncertainty. When asking for a single label set, the probability distribution can be used to estimate the model uncertainty. On the other hand, when evaluating a question that has multiple answers, it may become difficult to distinguish between model uncertainty and data uncertainty, due to the existence of multiple possible answers.
Multi-Answer Question Answering Dataset
The paper introduces a novel dataset designed to probe LLM performance under data uncertainty. This dataset, named Multi-Answer Question Answering (MAQA), comprises questions that necessitate multiple correct answers across diverse domains such as world knowledge, mathematical reasoning, and commonsense reasoning, totaling over 2,000 questions. This diversity enables comprehensive analysis of LLM behavior in tasks susceptible to both model and data uncertainty (Table 1).
Methodological Approach
The study evaluates five uncertainty quantification methods, considering both white-box and black-box LLMs:
- White-box Methods:
- Max Softmax Logit: Utilizes logits to determine confidence, with lower max logits indicating higher uncertainty.
- Entropy: Measures the randomness of the token distribution, with higher entropy reflecting higher uncertainty.
- Margin: Defines uncertainty as the difference between top logits; a smaller margin suggests higher uncertainty.
- Black-box Methods:
- Verbalized Confidence: Models verbally express their confidence level in responses.
- Response Consistency: Evaluates confidence through consistency in multiple responses to the same input.
Experimental Results
The study's experimental framework explores three key questions: the performance of uncertainty quantification methods amidst data uncertainty, variability across tasks, and correlation with recall scores.
Key Observations
- Impact of Data Uncertainty:
- Data uncertainty affects logit distributions; however, entropy remains a reliable predictor of model uncertainty in the presence of data uncertainty. This stems from LLMs' tendency to concentrate predictions on a few probable tokens.
- Overconfidence in Reasoning Tasks:
- Reasoning tasks show LLM overconfidence, particularly post-initial answer generation, complicating uncertainty quantification (Figure 2).
- Response Consistency vs. Verbalized Confidence:
- Response consistency effectively predicts model correctness, even under data uncertainty, outperforming verbalized confidence, which is hampered by inherent LLM overconfidence (Figure 3).
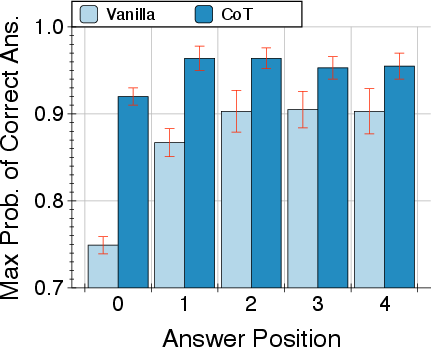
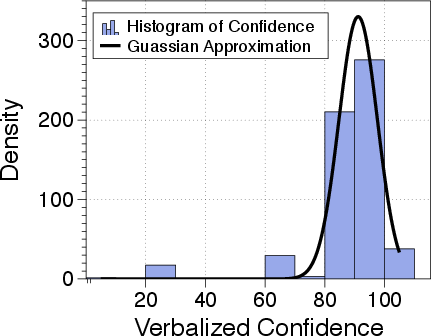
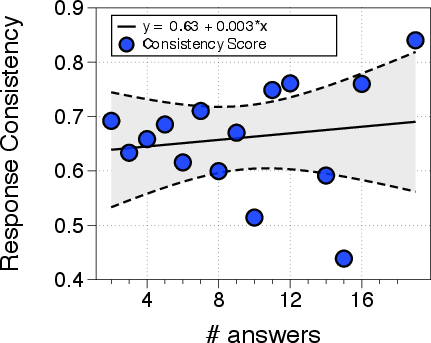
Figure 2: Result using different promptings.
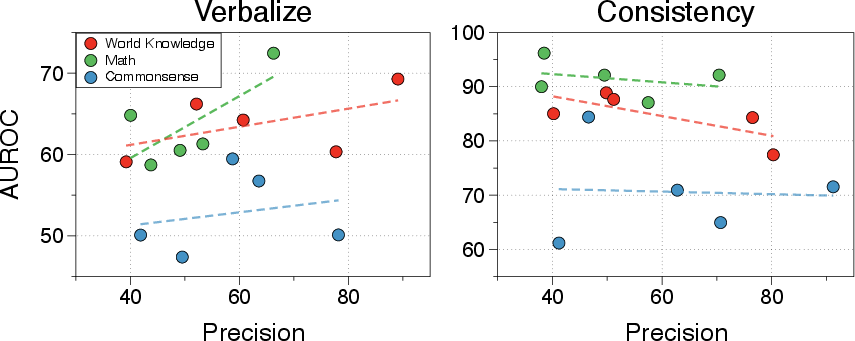
Figure 3: AUROC scores by precision for using uncertainty quantification methods: Verbalized Confidence and Response Consistency.
Implications and Future Directions
The findings underscore the robustness of entropy and consistency-based methods in uncertainty quantification, even with data uncertainty. This work provides essential insights for developing more reliable LLMs capable of navigating complex, real-world scenarios where multiple correct answers coexist. Future research may focus on refining these methods, integrating them with LLM training to mitigate hallucinations, and enhancing the deployment of LLMs in domains requiring high accuracy and interpretability.
Conclusion
The study presents a vital step towards understanding and improving uncertainty quantification in LLMs, especially under realistic, multi-answer conditions. By addressing both model and data uncertainty, the research advances the reliability and applicability of LLMs across various complex tasks, forming a foundation for ongoing and future advancements in the field of AI uncertainty quantification.