- The paper introduces LUQ, a sampling-based method that quantifies uncertainty in long-text outputs from LLMs using response diversity as a metric.
- It leverages sentence-level natural language inference to assess consistency among multiple generated responses, addressing limitations of existing UQ methods.
- The LUQ-ENSEMBLE strategy enhances factual accuracy by up to 5% by selecting responses with the lowest uncertainty from diverse models.
LUQ: Long-text Uncertainty Quantification for LLMs
The paper "LUQ: Long-text Uncertainty Quantification for LLMs" introduces a novel method, LUQ, for uncertainty quantification in long-text generation tasks using LLMs. The study highlights the inadequacies of existing UQ approaches when applied to extended text and proposes novel strategies to address these challenges.
Introduction
In contemporary NLP applications, LLMs demonstrate substantial capabilities, yet they frequently produce nonfactual outputs due to a lack of effective uncertainty quantification for long texts. Existing UQ methods primarily focus on short text and require access to internal model states, which is often impractical for black-box models accessible only via APIs. Thus, this paper investigates the effectiveness of current UQ methods for long-text generation and introduces LUQ, a new sampling-based approach, to better quantify uncertainties in these contexts.
Methodology
LUQ operates by generating multiple responses from an LLM to a given query and assessing the diversity and consistency among these responses. The underlying assumption is that a model's uncertainty is inversely related to the consistency of its generated outputs. LUQ employs sentence-level consistency checks using Natural Language Inference (NLI) to determine the degree of support or contradiction among the different responses produced by the model.

Figure 1: The illustration of the Luq and Luq-Ensemble framework. Given a question, various LLMs exhibit differing levels of uncertainty. We generate n sample responses from each LLM and then assess the uncertainty based on the diversity of these samples.
Experiments and Results
Experiments conducted across multiple black-box LLMs, including GPT-4 and Gemini Pro, demonstrate that LUQ consistently provides a strong negative correlation with factuality scores, outperforming current baseline methods. The proposed LUQ-ENSEMBLE strategy ensembles responses from multiple models, selecting the most factual by identifying the model with the lowest uncertainty, thereby improving factual accuracy by up to 5%.
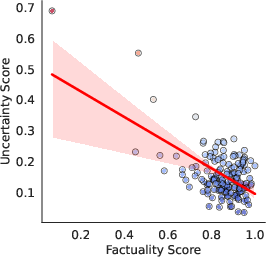
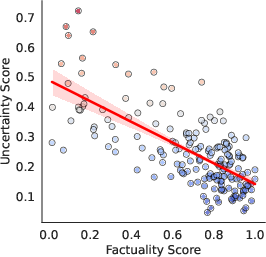
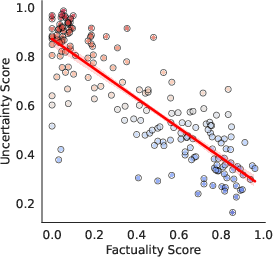
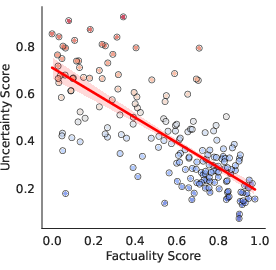
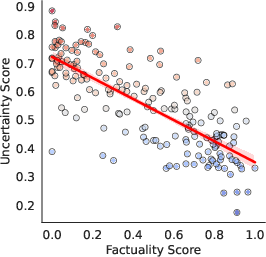
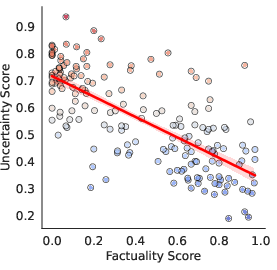
Figure 2: GPT-4
Application of LUQ and LUQ-ENSEMBLE
The LUQ metric serves as an effective indicator for distinguishing between factual and inaccurate LLM outputs, especially in models lacking internal uncertainty awareness. LUQ-ENSEMBLE selects responses across diverse models, capitalizing on varied training corpus knowledge to improve response accuracy significantly.
Trade-offs and Considerations
One notable consideration is the computational cost associated with generating multiple samples to assess uncertainty, particularly as sample size increases to enhance accuracy. Temperature settings also play a significant role in uncertainty measurement, as variability in responses is essential for accurate consistency-based assessments. For practical deployment, selectively adjusting response strategies based on LUQ scores can enhance the fidelity of generated content.
Conclusion
The paper advances the field of LLM uncertainty quantification by introducing LUQ and its ensemble variant, LUQ-ENSEMBLE, to elevate factual accuracy in long-text generation tasks. These methodologies bridge existing gaps in UQ for LLMs, offering robust tools to enhance AI-generated content's reliability and trustworthiness without direct access to model internals. Overall, LUQ and its ensemble strategy provide significant improvements in factuality, making them pivotal to future advancements in AI text generation accuracy.